This document summarizes key concepts in information retrieval systems and algorithms for large data sets. It discusses the differences between information retrieval and data retrieval systems. It also describes several classic models for relevance ranking in IR, including the Boolean model and vector space model. The document outlines topics like text processing, indexing, searching, and evaluation in information retrieval systems.




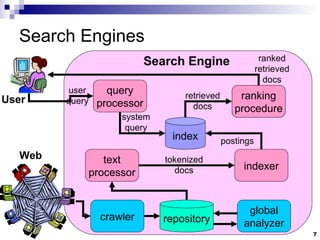
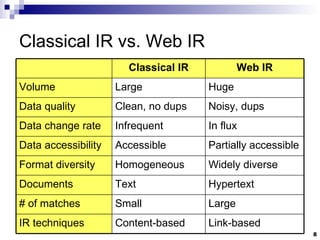












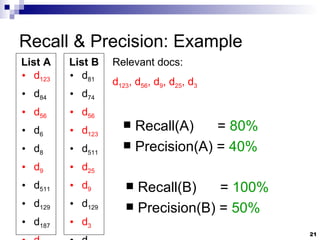

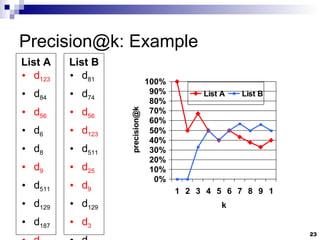


![Query Languages: Pattern Matching Prefixes Ex: prefix:comput Suffixes Ex: suffix:net Regular Expressions Ex: [0-9]+th world-wide web conference](https://image.slidesharecdn.com/slides1678/85/Slides-28-320.jpg)