Downloaded 453 times

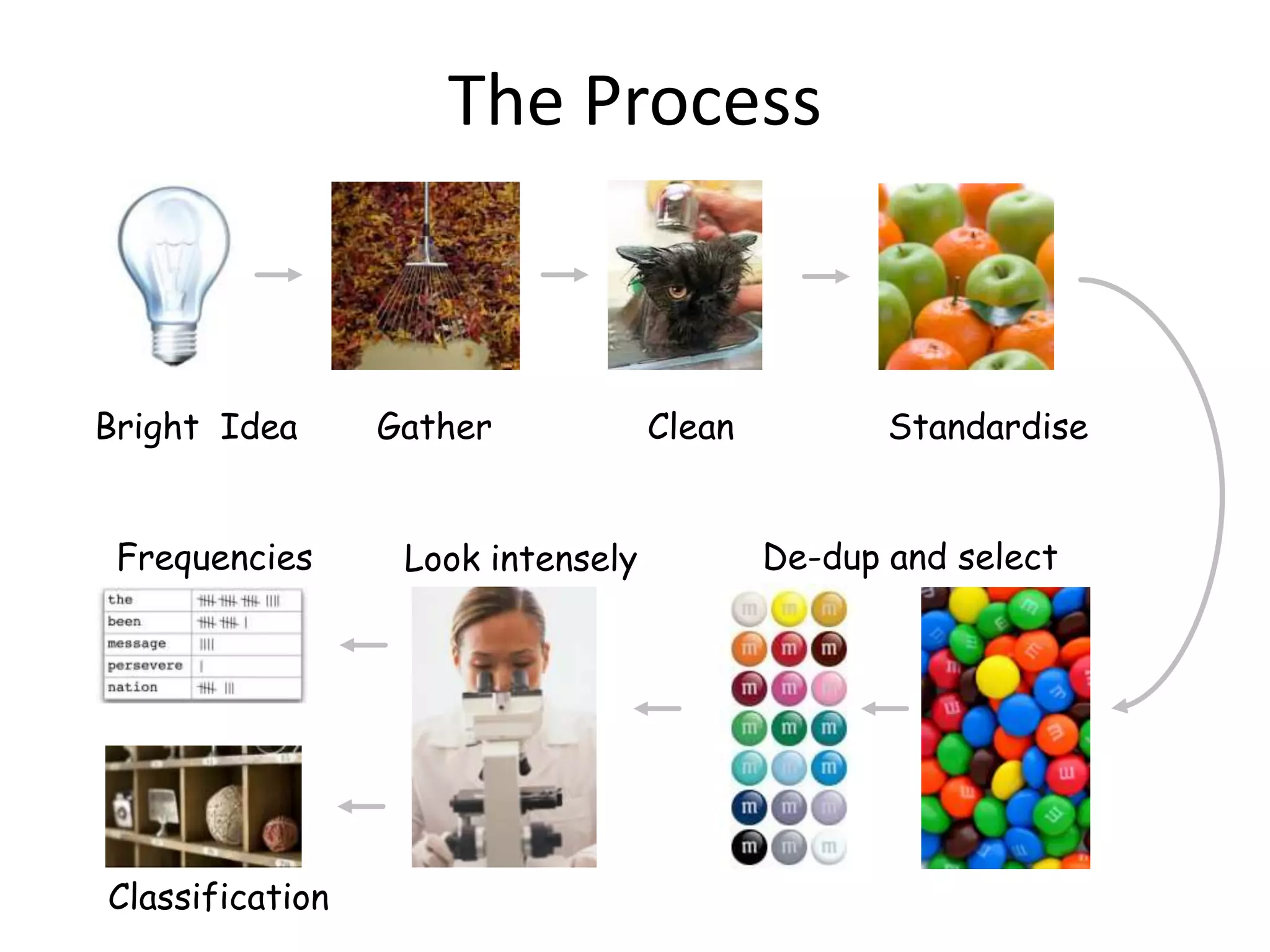

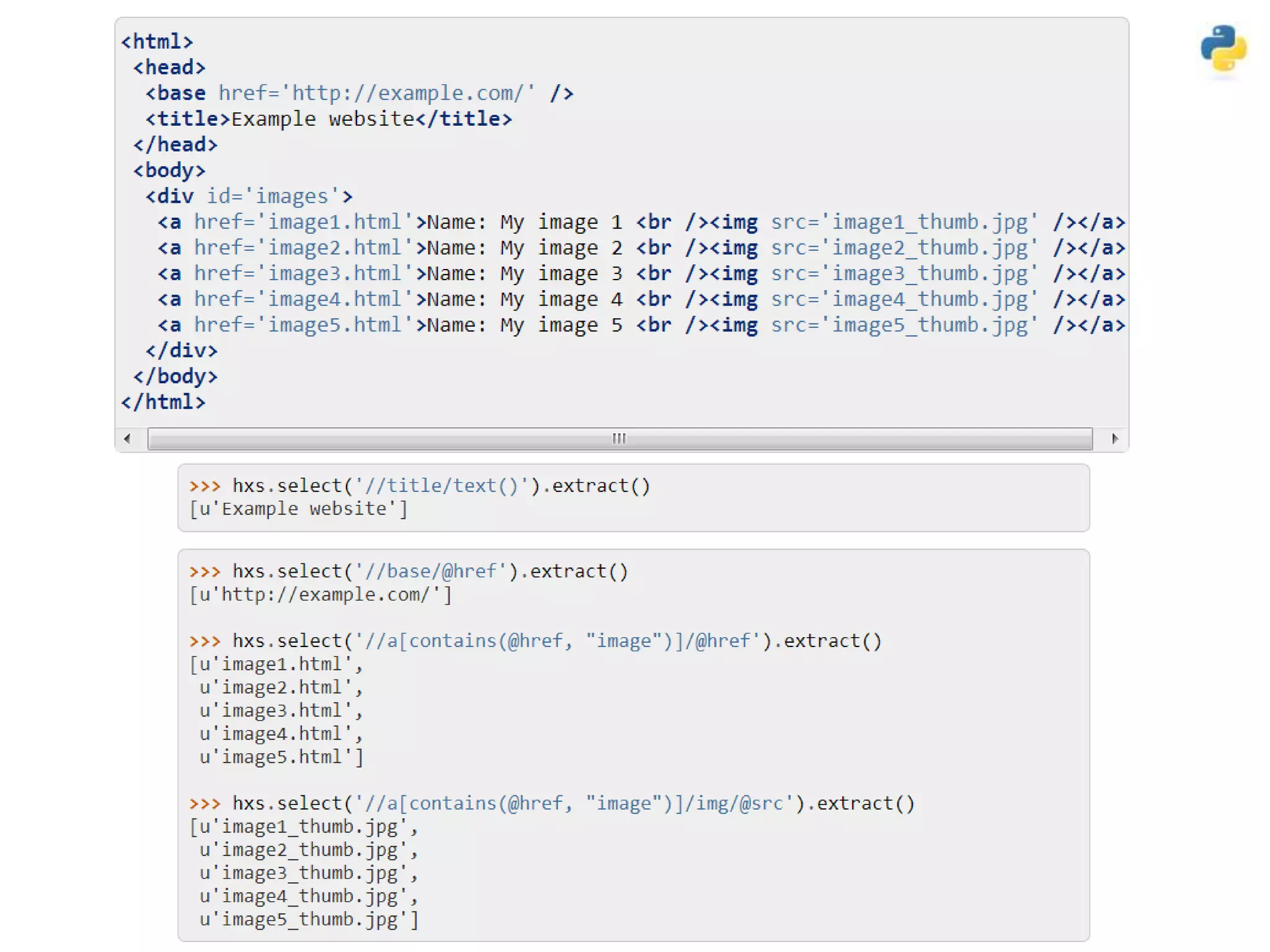
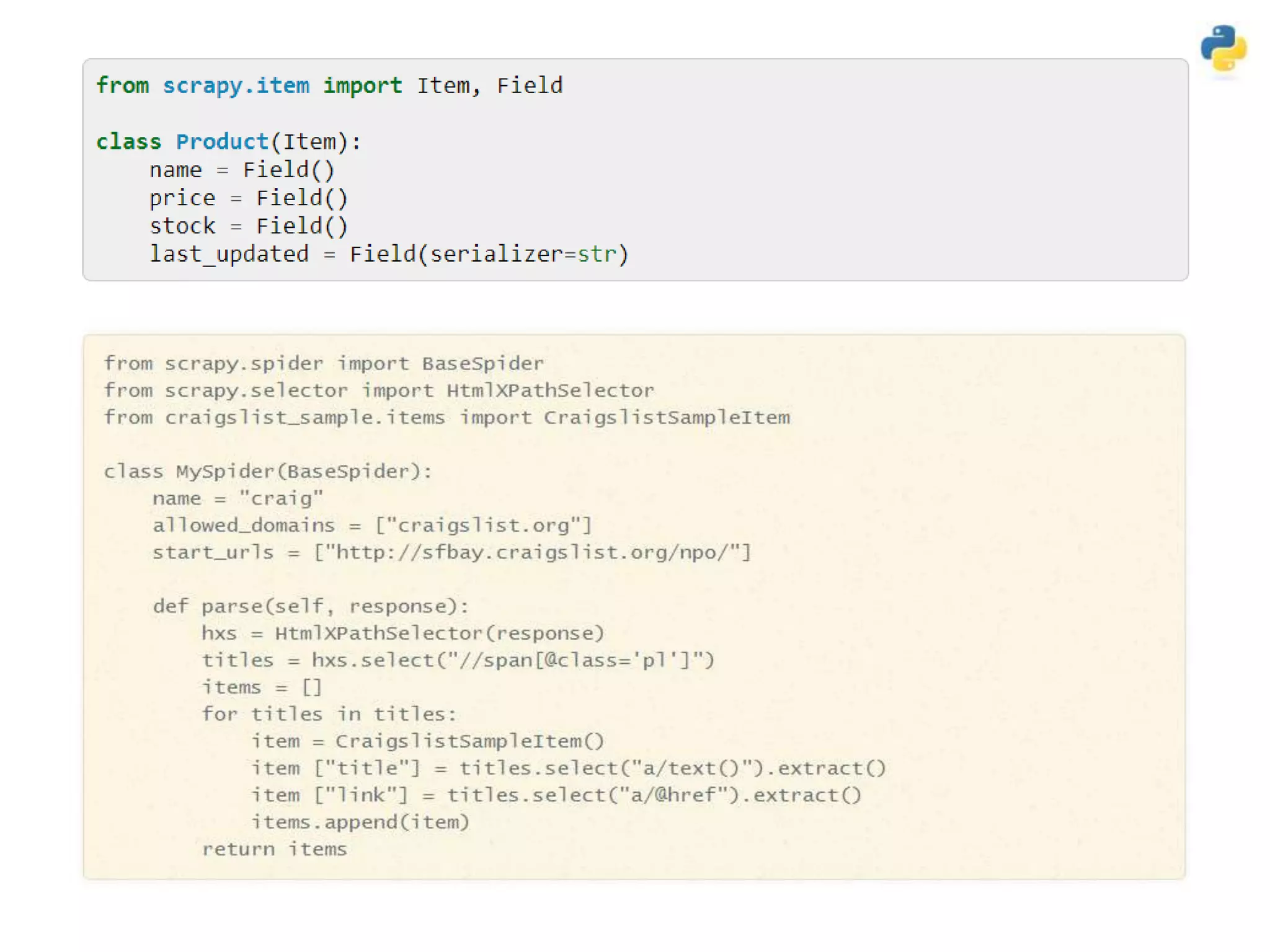
![• Translating text to consistent form
– Scrapy returns unicode strings
– Māori Maori
• SWAPSET =
[[ u"Ā", "A"], [ u"ā", "a"], [ u"ä", "a"]]
• translation_table =
dict([(ord(k), unicode(v)) for k, v in settings.SWAPSET])
• cleaned_content =
html_content.translate(translation_table)
– Or…
• test=u’Māori’ (you already have unicode)
• Unidecode(test) (returns ‘Maori’)](https://image.slidesharecdn.com/textanalyticsfortobaccocontrolslideshare-130919043258-phpapp01/75/Text-analytics-in-Python-and-R-with-examples-from-Tobacco-Control-7-2048.jpg)




![Deduplication
• Python sets
– shingles1 = set(get_shingles(record1['standardised_content']))
• Shingling and Jaccard similarity
– (a,rose,is,a,rose,is,a,rose)
– {(a,rose,is,a), (rose,is,a,rose), (is,a,rose,is), (a,rose,is,a), (rose,is,a,rose)}
• {(a,rose,is,a), (rose,is,a,rose), (is,a,rose,is)}
–
http://infolab.stanford.edu/~ullman/mmds/ch3.pdf a free text
http://www.cs.utah.edu/~jeffp/teaching/cs5955/L4-Jaccard+Shingle.pdf](https://image.slidesharecdn.com/textanalyticsfortobaccocontrolslideshare-130919043258-phpapp01/75/Text-analytics-in-Python-and-R-with-examples-from-Tobacco-Control-12-2048.jpg)
![Frequency Analysis
• Document-Term Matrix
– politi.dtm <- DocumentTermMatrix(politi.corpus_stemmed,
control = list(wordLengths=c(4,Inf)))
• Frequent and co-occurring terms
– findFreqTerms(politi.dtm, 5000)
[1] "2011" "also" "announc" "area" "around"
[6] "auckland" "better" "bill" "build" "busi"
– findAssocs(politi.dtm, "smoke", 0.5)
smoke tobacco quit smokefre smoker 2025 cigarett
1.00 0.74 0.68 0.62 0.62 0.58 0.57](https://image.slidesharecdn.com/textanalyticsfortobaccocontrolslideshare-130919043258-phpapp01/75/Text-analytics-in-Python-and-R-with-examples-from-Tobacco-Control-13-2048.jpg)



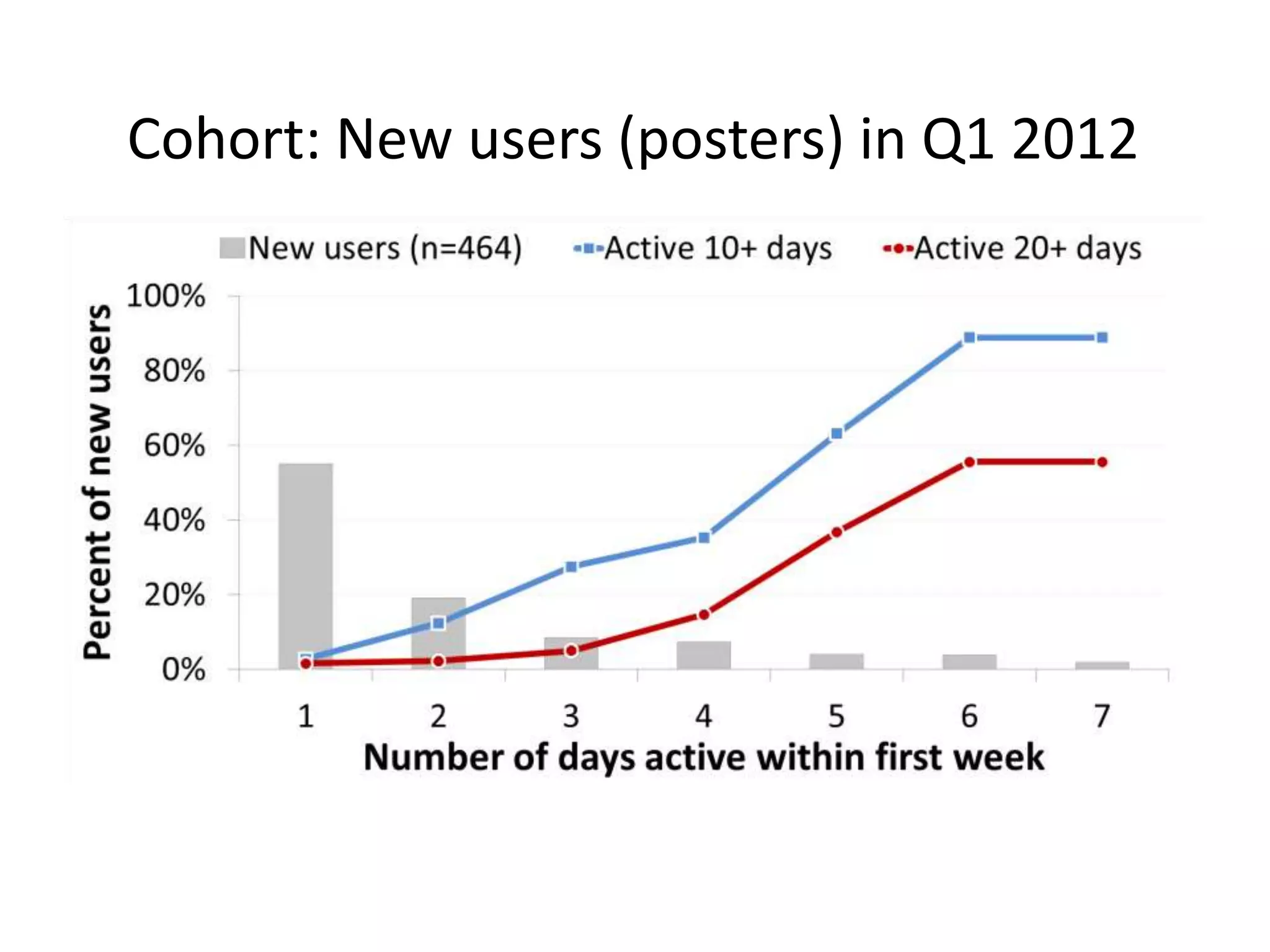




This document discusses text analytics techniques for summarizing and analyzing unstructured text documents, with examples from analyzing documents related to tobacco control. It covers data cleaning and standardization steps like removing punctuation, stopwords, stemming, and deduplication. It also discusses frequency analysis using document-term matrices, topic modeling using LDA, and unsupervised and supervised classification techniques. The document provides examples analyzing posts from new users versus highly active users on an online forum, identifying topics and comparing topic distributions between different user groups.









![[Yang, Downey and Boyd-Graber 2015] Efficient Methods for Incorporating Knowl...](https://cdn.slidesharecdn.com/ss_thumbnails/sparse-constrained-lda-151024072334-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)




![ACL2014 Reading: [Zhang+] "Kneser-Ney Smoothing on Expected Count" and [Pickh...](https://cdn.slidesharecdn.com/ss_thumbnails/kneser-neyacl2014-140711113350-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)








































































