Unit II
• BasicIR Models - Boolean Model - TF-IDF
(Term Frequency/Inverse Document
Frequency) Weighting - Vector Model –
Probabilistic Model – Latent Semantic
Indexing Model – Neural Network Model –
Retrieval Evaluation – Retrieval Metrics –
Precision and Recall – Reference Collection –
User-based Evaluation – Relevance Feedback
and Query Expansion – Explicit Relevance
Feedback.
3.
IR Models
• Modelingin IR is a complex process aimed at
producing a ranking function
– Ranking function: a function that assigns scores to
documents with regard to a given query
• Process consists of two main tasks:
– The conception of a logical framework for
representing documents and queries
– The definition of a ranking function that allows
quantifying the similarities among documents and
queries.
4.
Modeling and Ranking
•IR systems usually adopt index terms to index
and retrieve documents.
– Index term:
• In a restricted sense: it is a keyword that has some
meaning on its own; usually plays the role of a noun
• In a more general form: it is any word that appears in a
document Process consists of two main tasks:
– Retrieval based on index terms can be
implemented Efficiently Also, index terms are
simple to refer to in a query
– Simplicity is important because it reduces the
effort of query formulation
5.
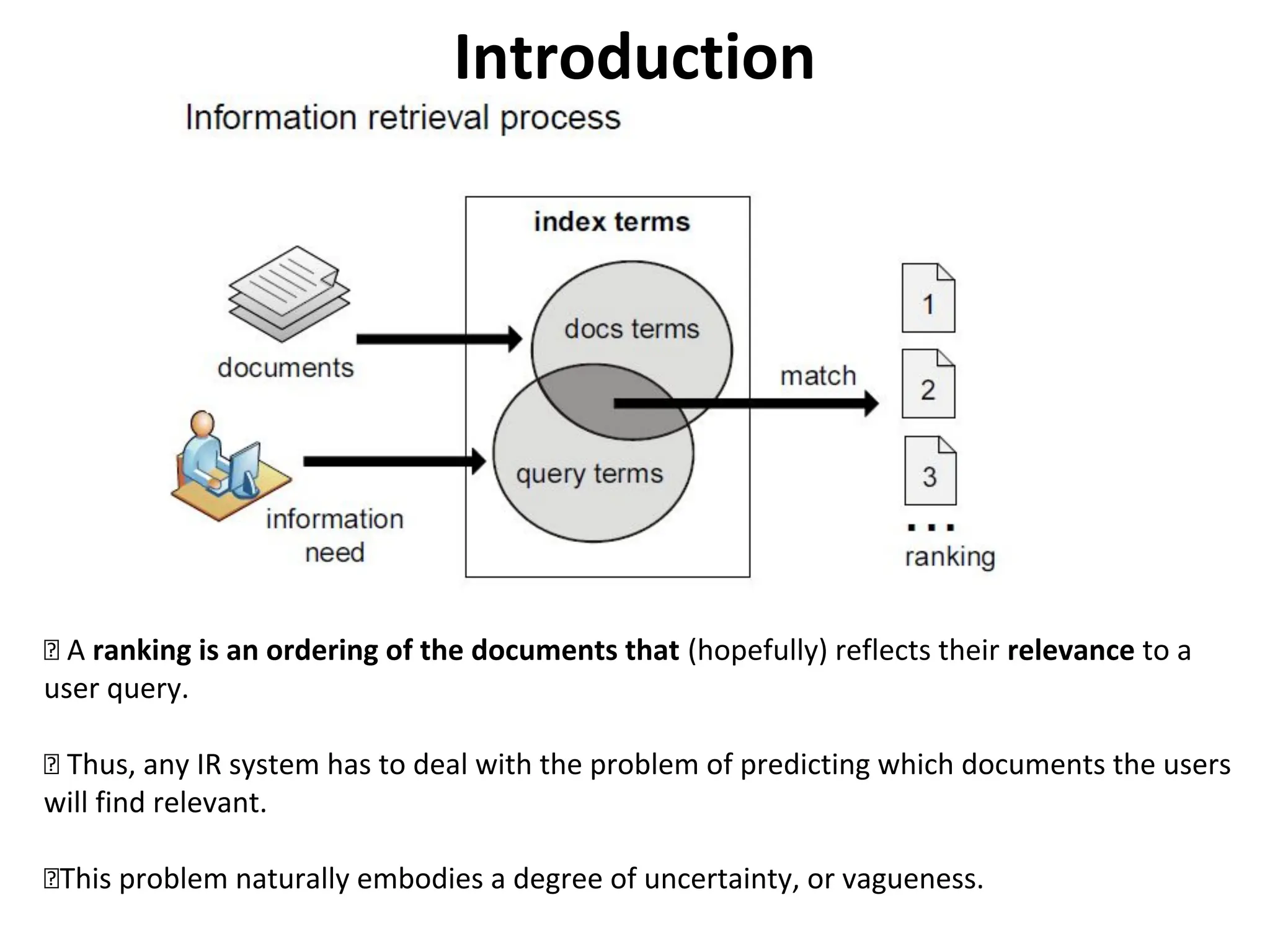
Introduction
A ranking isan ordering of the documents that (hopefully) reflects their relevance to a
user query.
Thus, any IR system has to deal with the problem of predicting which documents the users
will find relevant.
This problem naturally embodies a degree of uncertainty, or vagueness.
6.
IR Models
• AnIR model is a quadruple [D, Q, F, R(qi, dj)]
where
– D is a set of logical views for the documents in the
collection
– Q is a set of logical views for the user queries
– F is a framework for modeling documents and
queries
– R(qi, dj) is a ranking function
7.
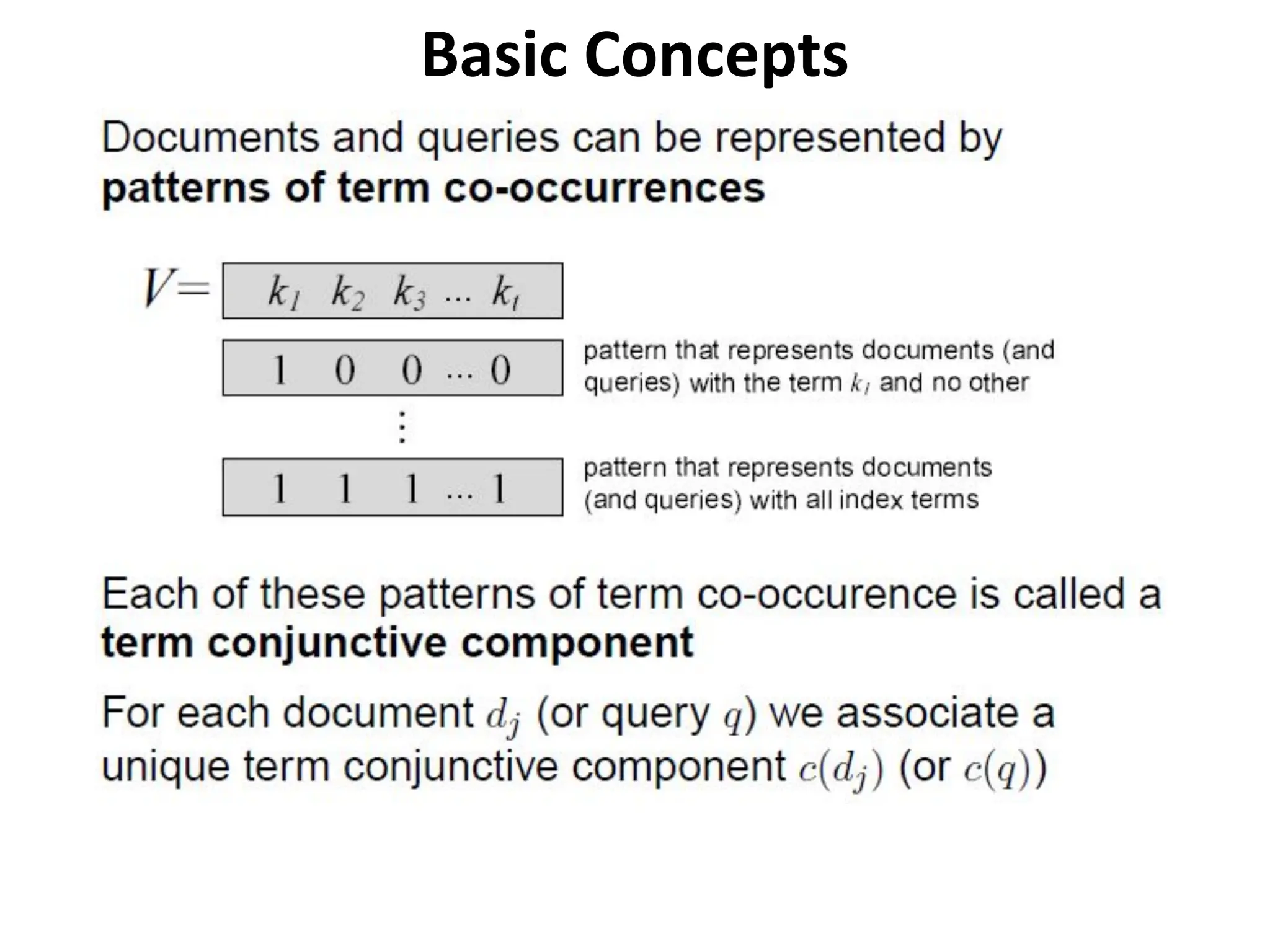
Basic Concepts
• Eachdocument is represented by a set of representative
keywords or index terms
• An index term is a word or group of consecutive words in a
document
• A pre-selected set of index terms can be used to summarize the
document contents
• However, it might be interesting to assume that all words are
index terms (full text representation)
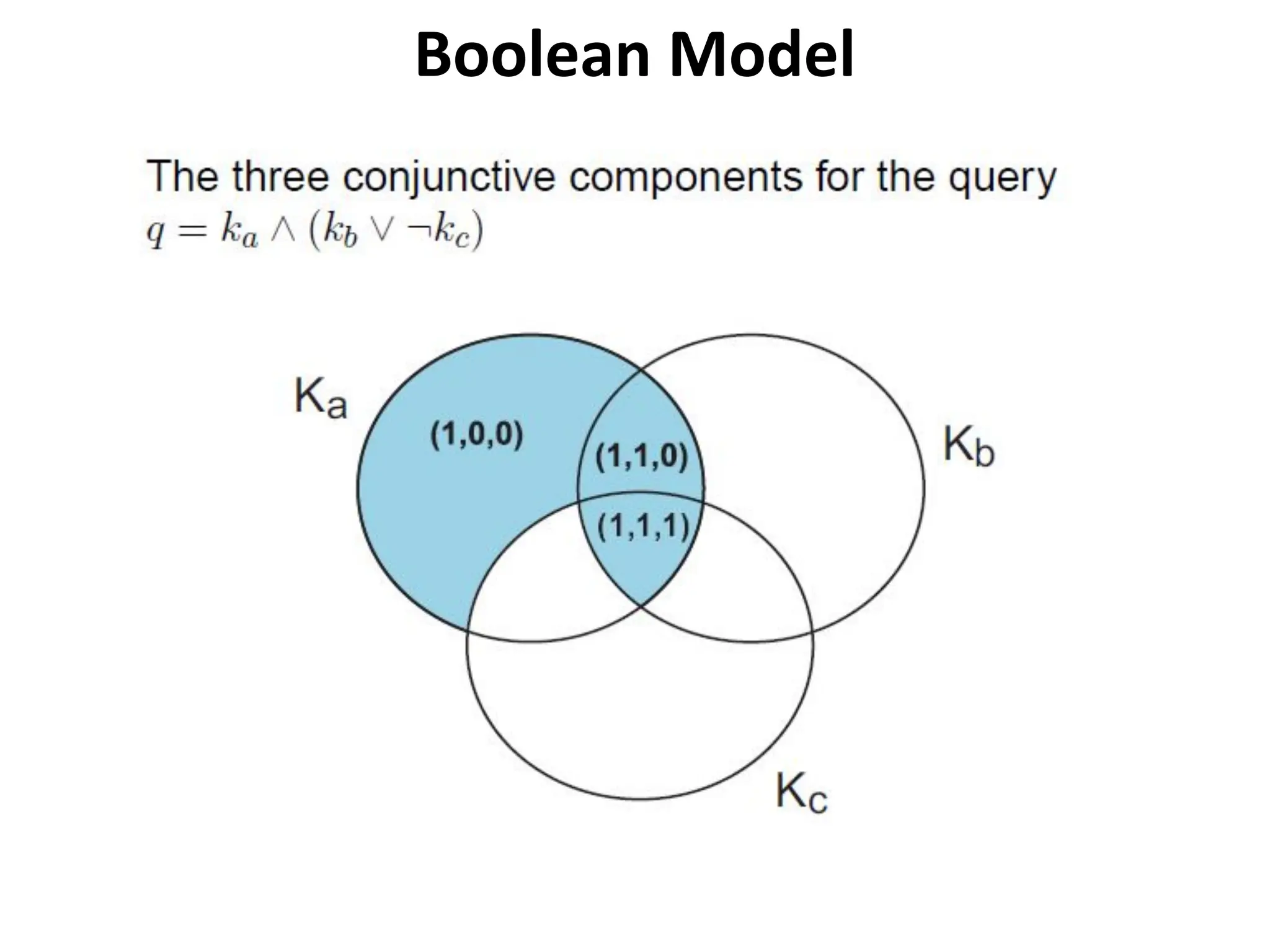
Drawbacks of theBoolean Model
• Retrieval based on binary decision criteria with no
notion of partial matching
• No ranking of the documents is provided (absence
of a grading scale)
• Information need has to be translated into a
Boolean expression, which most users find
awkward
• The Boolean queries formulated by the users are
most often too simplistic
• The model frequently returns either too few or
too many documents in response to a user query
17.
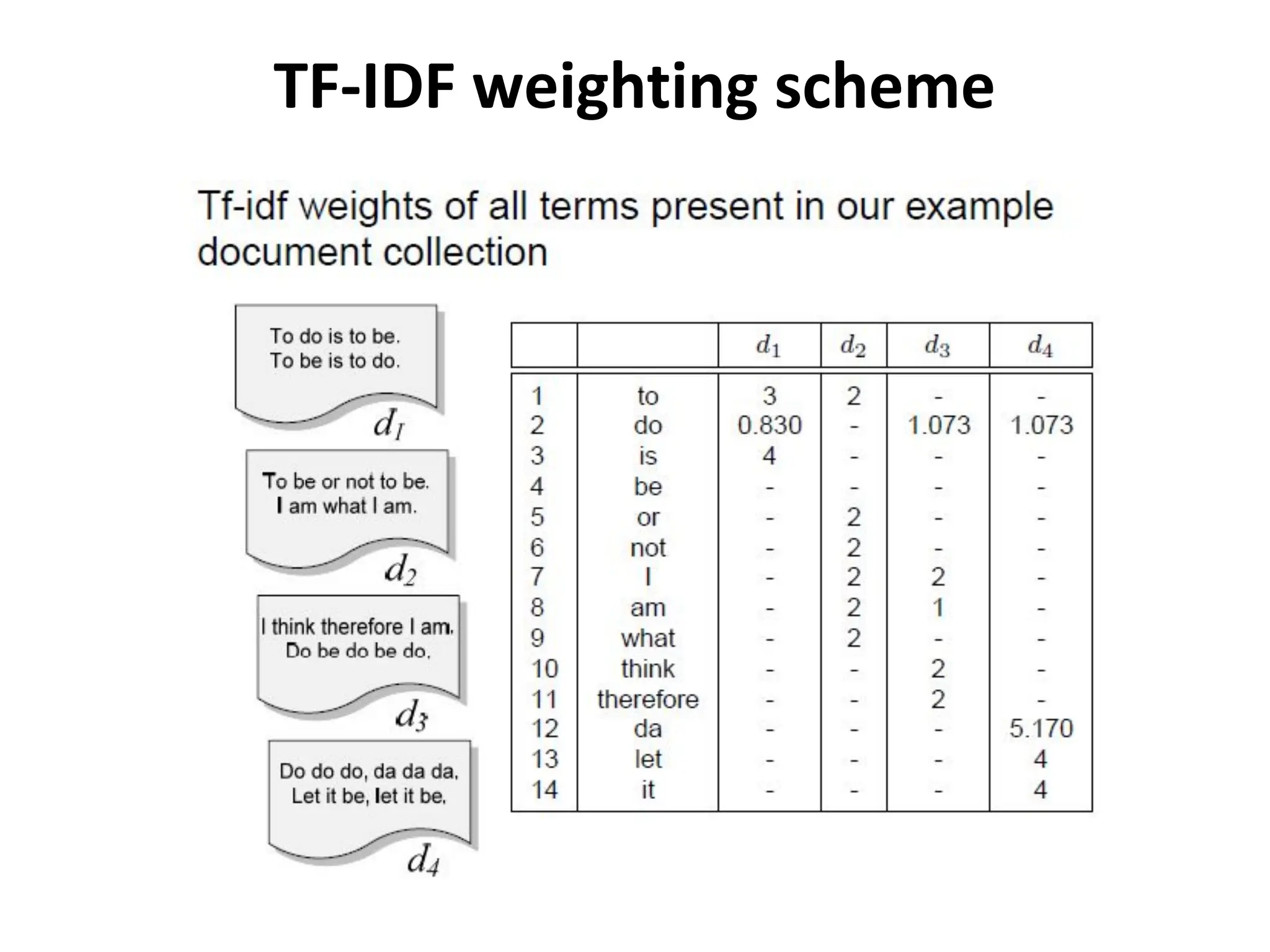
TF-IDF Weights
• TF-IDFterm weighting scheme:
– Term frequency (TF)
– Inverse document frequency (IDF)
– Foundations of the most popular term weighting
scheme in IR
Inverse Document Frequency
•We call document exhaustivity the number of
index terms assigned to a document
• The more index terms are assigned to a
document, the
• higher is the probability of retrieval for that
document If too many terms are assigned to a
document, it will be retrieved by queries for which
it is not relevant
• Optimal exhaustivity. We can circumvent this
problem by optimizing the number of terms per
document
• Another approach is by weighting the terms
differently, by exploring the notion of term
specificity
Document Length Normalization
•Document sizes might vary widely
• This is a problem because longer documents are
more likely to be retrieved by a given query
• To compensate for this undesired effect, we can
divide the rank of each document by its length
• This procedure consistently leads to better
ranking, and it is called document length
normalization
33.
Document Length Normalization
•Methods of document length normalization
depend on the
• representation adopted for the documents:
– Size in bytes: consider that each document is
represented simply as a stream of bytes
– Number of words: each document is represented as a
single string, and the document length is the number
of words in it
– Vector norms: documents are represented as vectors
of weighted terms
VECTOR MODEL -Overview
• Boolean matching and binary weights is too
limiting
• The vector model proposes a framework in which
partial matching is possible
• This is accomplished by assigning non-binary
weights to index terms in queries and in
documents
• Term weights are used to compute a degree of
similarity between a query and each document
• The documents are ranked in decreasing order of
their degree of similarity
39.
Overview
• The VectorSpace Model (VSM) is a way of
representing documents through the words
that they contain
• It is a standard technique in Information
Retrieval
• The VSM allows decisions to be made about
which documents are similar to each other
and to keyword queries
40.
How it works:Overview
• Each document is broken down into a word
frequency table
• The tables are called vectors and can be
stored as arrays
• A vocabulary is built from all the words in all
documents in the system
• Each document is represented as a vector
based against the vocabulary.
41.
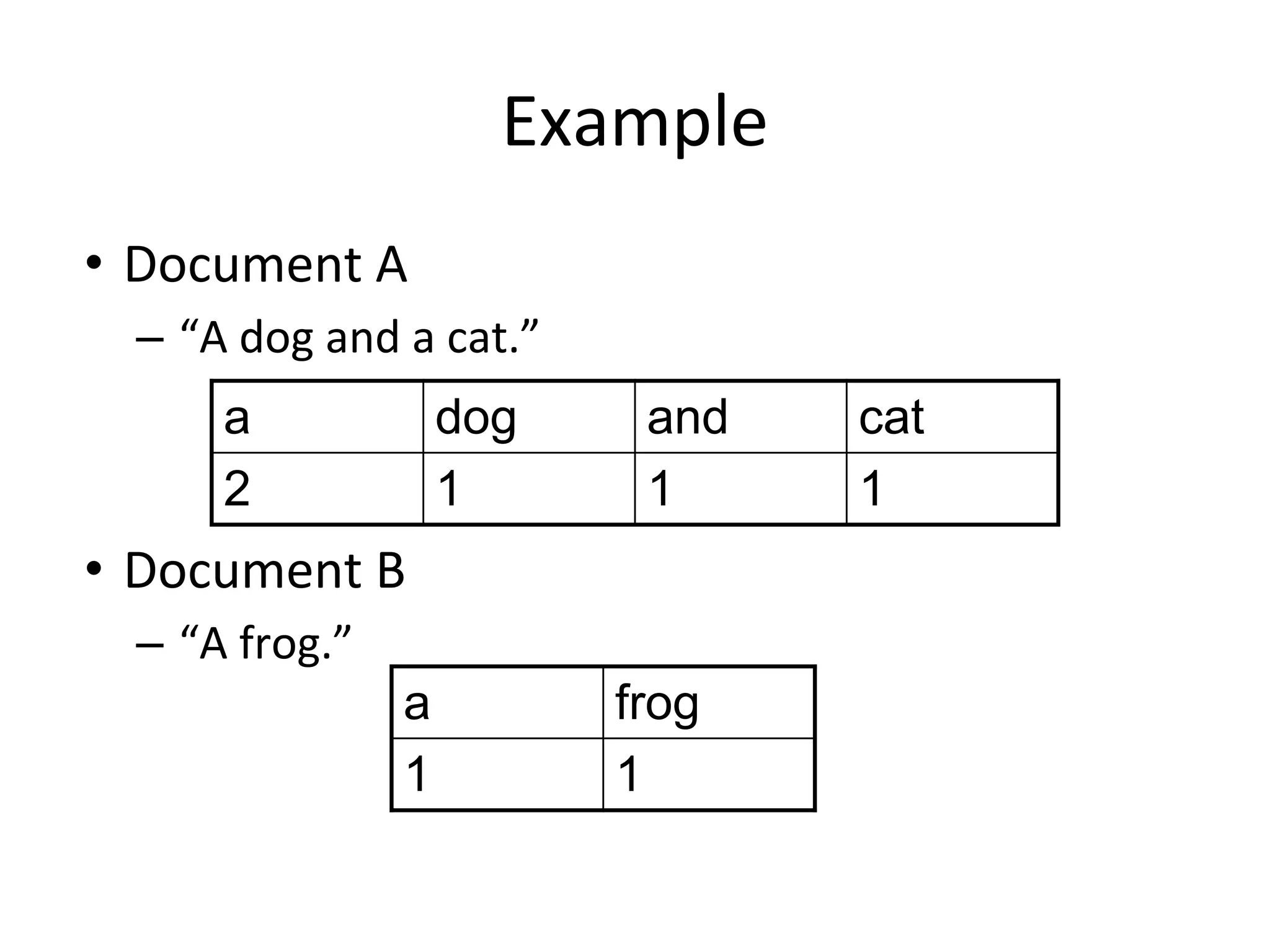
Example
• Document A
–“A dog and a cat.”
• Document B
– “A frog.”
a dog and cat
2 1 1 1
a frog
1 1
42.
Example, continued
• Thevocabulary contains all words used
– a, dog, and, cat, frog
• The vocabulary needs to be sorted
– a, and, cat, dog, frog
43.
Example, continued
• DocumentA: “A dog and a cat.”
– Vector: (2,1,1,1,0)
• Document B: “A frog.”
– Vector: (1,0,0,0,1)
a and cat dog frog
2 1 1 1 0
a and cat dog frog
1 0 0 0 1
44.
Queries
• Queries canbe represented as vectors in the
same way as documents:
– Dog = (0,0,0,1,0)
– Frog = ( )
– Dog and frog = ( )
45.
Similarity measures
• Thereare many different ways to measure how
similar two documents are, or how similar a
document is to a query
• The cosine measure is a very common similarity
measure
• Using a similarity measure, a set of documents can
be compared to a query and the most similar
document returned
46.
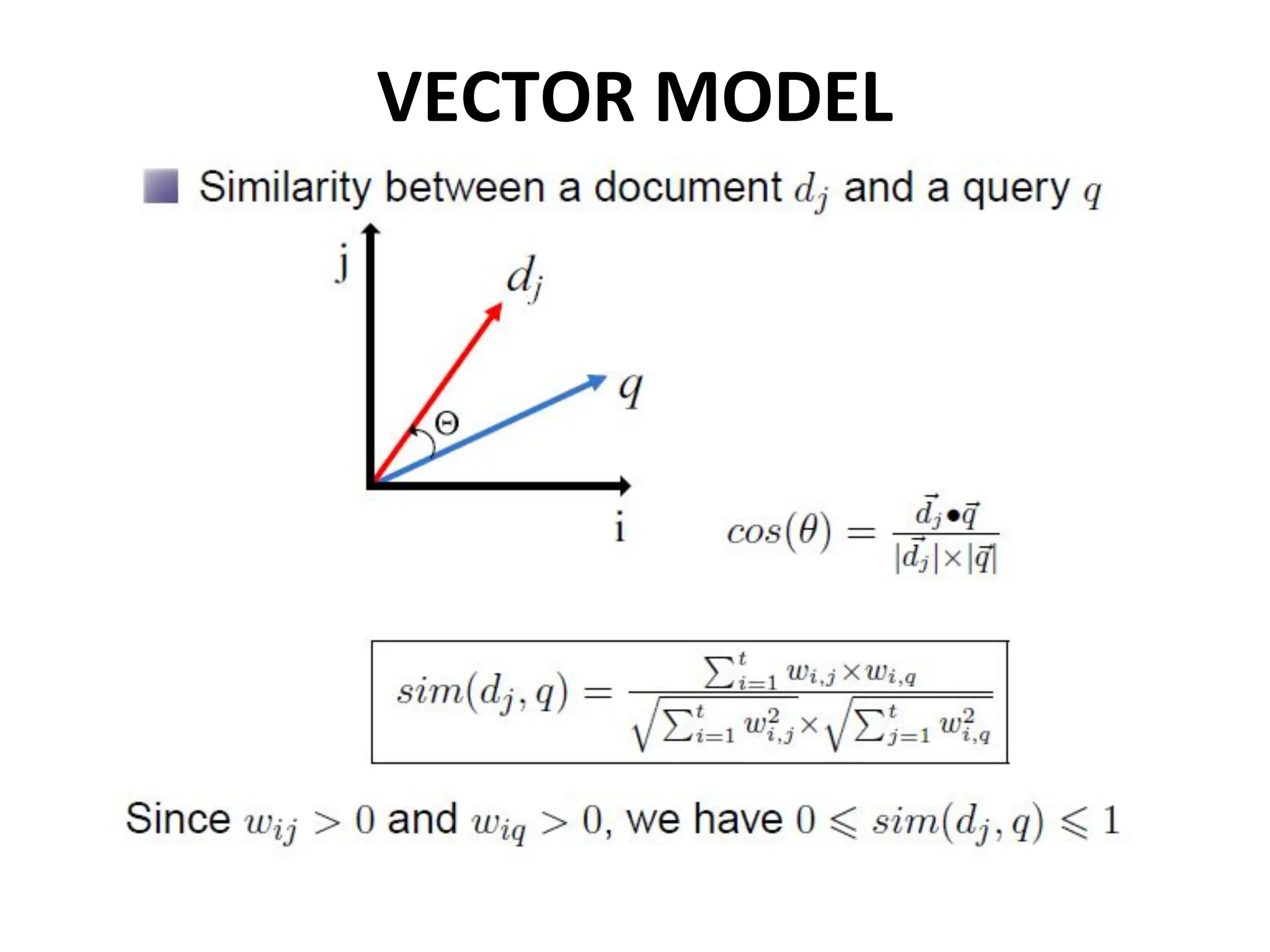
The cosine measure
•For two vectors d and d’ the cosine similarity
between d and d’ is given by:
• Here d X d’ is the vector product of d and d’,
calculated by multiplying corresponding frequencies
together
• The cosine measure calculates the angle between
the vectors in a high-dimensional virtual space
47.
Example
• Let d= (2,1,1,1,0) and d’ = (0,0,0,1,0)
– dXd’ = 2X0 + 1X0 + 1X0 + 1X1 + 0X0=1
– |d| = √(22
+12
+12
+12
+02
) = √7=2.646
– |d’| = √(02
+02
+02
+12
+02
) = √1=1
– Similarity = 1/(1 X 2.646) = 0.378
• Let d = (1,0,0,0,1) and d’ = (0,0,0,1,0)
– Similarity =
48.
Ranking documents
• Auser enters a query
• The query is compared to all documents using
a similarity measure
• The user is shown the documents in
decreasing order of similarity to the query
term
VECTOR MODEL
Advantages:
• Term-weightingimproves quality of the answer set
• Partial matching allows retrieval of docs that
approximate the query conditions
• Cosine ranking formula sorts documents according
to a degree of similarity to the query
• Document length normalization is naturally built-in
into the ranking
Disadvantages:
• It assumes independence of index terms
Vocabulary
• Stopword lists
–Commonly occurring words are unlikely to give
useful information and may be removed from the
vocabulary to speed processing
– Stopword lists contain frequent words to be
excluded
– Stopword lists need to be used carefully
• E.g. “to be or not to be”
56.
Term weighting
• Notall words are equally useful
• A word is most likely to be highly relevant to
document A if it is:
– Infrequent in other documents
– Frequent in document A
• The cosine measure needs to be modified to
reflect this
57.
Normalised term frequency(tf)
• A normalised measure of the importance of a word
to a document is its frequency, divided by the
maximum frequency of any term in the document
• This is known as the tf factor.
• Document A: raw frequency vector: (2,1,1,1,0), tf
vector: ( )
• This stops large documents from scoring higher
58.
Inverse document frequency(idf)
• A calculation designed to make rare words
more important than common words
• The idf of word i is given by
• Where N is the number of documents and ni
is
the number that contain word i
59.
tf-idf
• The tf-idfweighting scheme is to multiply each
word in each document by its tf factor and idf
factor
• Different schemes are usually used for query
vectors
• Different variants of tf-idf are also used
PROBABILISTIC MODEL
• Theprobabilistic model captures the IR problem using a
probabilistic framework
• Given a user query, there is an ideal answer set for this
query
• Given a description of this ideal answer set, we could
retrieve the relevant documents
• Querying is seen as a specification of the properties of this
ideal answer set
• But, what are these properties?
• An initial set of documents is retrieved somehow
• The user inspects these docs looking for the relevant ones
(in truth, only top 10-20 need to be inspected)
• The IR system uses this information to refine the
description of the ideal answer set
• By repeating this process, it is expected that the description
of the ideal answer set will improve
62.
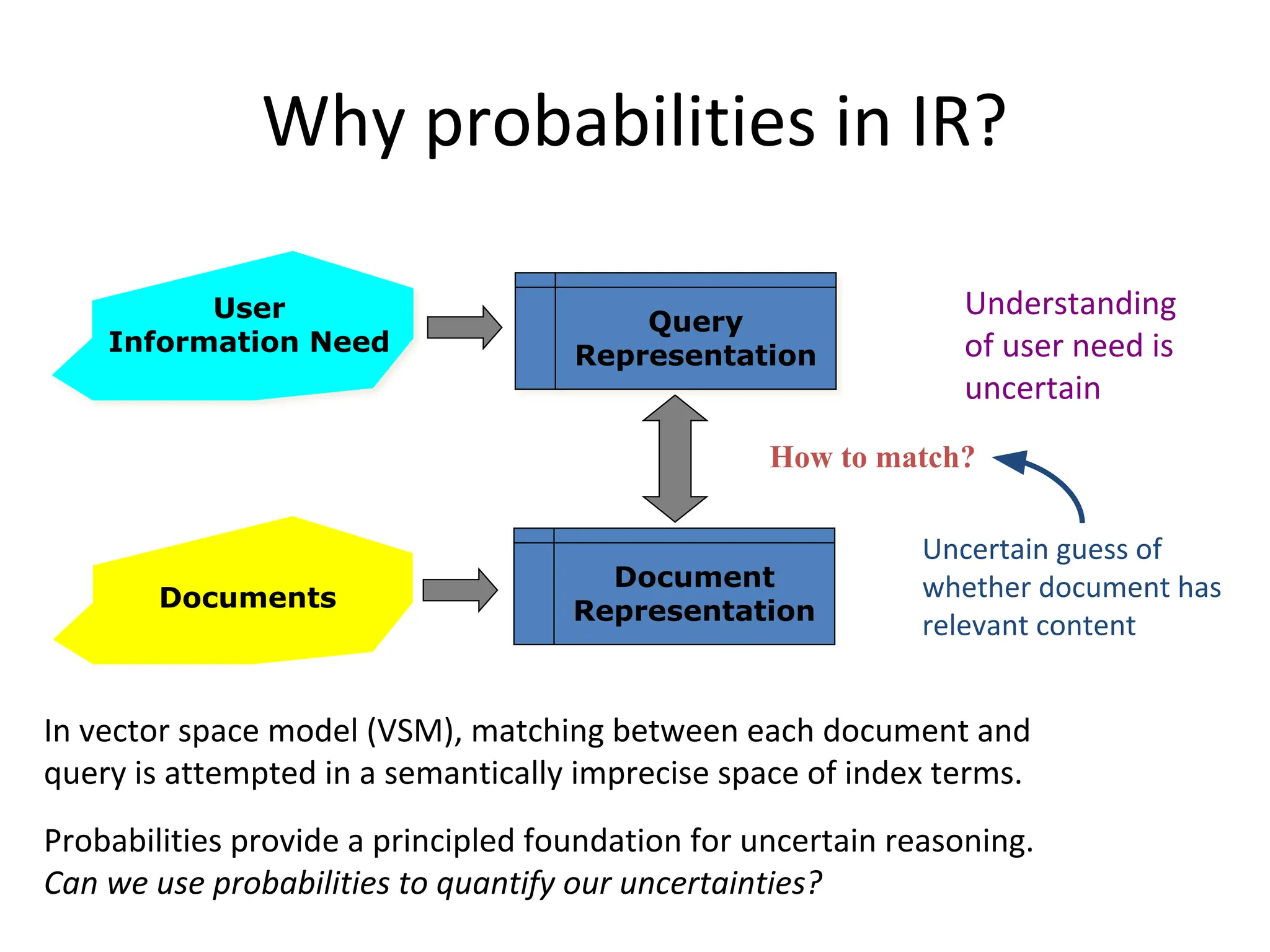
Why probabilities inIR?
User
Information Need
Documents
Document
Representation
Query
Representation
How to match?
In vector space model (VSM), matching between each document and
query is attempted in a semantically imprecise space of index terms.
Probabilities provide a principled foundation for uncertain reasoning.
Can we use probabilities to quantify our uncertainties?
Uncertain guess of
whether document has
relevant content
Understanding
of user need is
uncertain
63.
Probabilistic IR topics
•Classical probabilistic retrieval model
– Probability ranking principle, etc.
– Binary independence model (≈ Naïve Bayes text cat)
– (Okapi) BM25
• Bayesian networks for text retrieval
• Language model approach to IR
– An important emphasis in recent work
• Probabilistic methods are one of the oldest but
also one of the currently hottest topics in IR.
64.
The document rankingproblem
• We have a collection of documents
• User issues a query
• A list of documents needs to be returned
• Ranking method is the core of an IR system:
– In what order do we present documents to the user?
– We want the “best” document to be first, second best
second, etc….
• Idea: Rank by probability of relevance of the
document w.r.t. information need
– P(R=1|documenti
, query)
65.
• For eventsA and B:
• Bayes’ Rule
• Odds:
Prior
Recall a few probability basics
Posterior
66.
Probability Ranking Principle(PRP)
“If a reference retrieval system’s response to each
request is a ranking of the documents in the
collection in order of decreasing probability of
relevance to the user who submitted the request,
where the probabilities are estimated as
accurately as possible on the basis of whatever
data have been made available to the system
for this purpose, the overall effectiveness of the
system to its user will be the best that is
obtainable on the basis of those data.”
Probability Ranking Principle
Letx represent a document in the collection.
Let R represent relevance of a document w.r.t. given (fixed)
query and let R=1 represent relevant and R=0 not relevant.
p(x|R=1), p(x|R=0) - probability that if a
relevant (not relevant) document is
retrieved, it is x.
Need to find p(R=1|x) - probability that a document x is relevant.
p(R=1),p(R=0) - prior probability
of retrieving a relevant or non-relevant
document
69.
Probability Ranking Principle
•How do we compute all those probabilities?
– Do not know exact probabilities, have to use
estimates
– Binary Independence Model (BIM) – which we
discuss next – is the simplest model
• Questionable assumptions
– “Relevance” of each document is independent of
relevance of other documents.
• Really, it’s bad to keep on returning duplicates
– “term independence assumption”
• terms’ contributions to relevance are treated as
independent events.
70.
Probabilistic Retrieval Strategy
•Estimate how terms contribute to relevance
– How do things like tf, df, and document length influence
your judgments about document relevance?
• A more nuanced answer is the Okapi formulae
– Spärck Jones / Robertson
• Combine to find document relevance probability
• Order documents by decreasing probability
71.
Probabilistic Ranking
Basic concept:
“Fora given query, if we know some documents that are relevant, terms that
occur in those documents should be given greater weighting in searching for
other relevant documents.
By making assumptions about the distribution of terms and applying Bayes
Theorem, it is possible to derive weights theoretically.”
Van Rijsbergen




![IR Models
• An IR model is a quadruple [D, Q, F, R(qi, dj)]
where
– D is a set of logical views for the documents in the
collection
– Q is a set of logical views for the user queries
– F is a framework for modeling documents and
queries
– R(qi, dj) is a ranking function](https://image.slidesharecdn.com/modelingandretrieval4-250812090951-4559b278/75/MODELING-AND-RETRIEVAL-4-pdfMODELING-AND-RETRIEVAL-EVALUATION-6-2048.jpg)