Download as PDF, PPTX





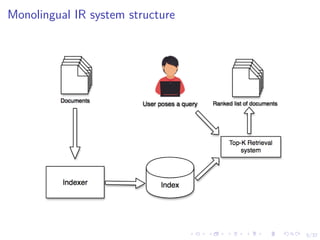




































This document discusses cross-lingual information retrieval. It presents approaches for translating queries from other languages to the document language, including using online machine translation systems and developing a statistical machine translation system. It describes experiments on reranking translations to select the one most effective for retrieval and on adapting the reranking model to new languages. Results show the reranking approach improves over baselines and online translation systems. The document also explores document translation and query expansion techniques.



































































