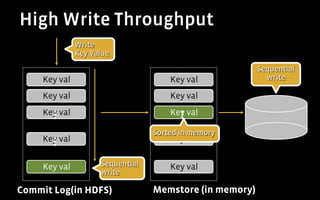
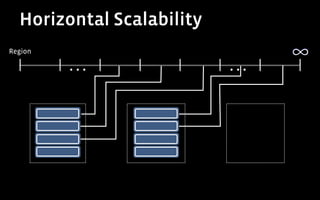
1) HBase satisfied Facebook's requirements for a real-time data store by providing excellent write performance, horizontal scalability, and features like atomic operations.
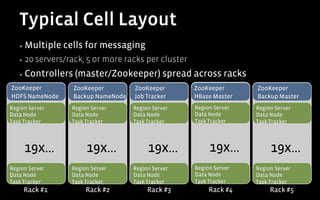
2) At Facebook, HBase is used for messaging and user activity tracking applications that involve massive write-throughput and petabytes of data.
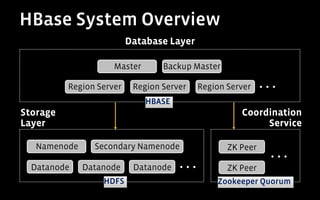
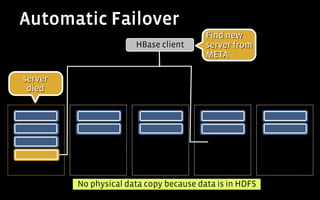
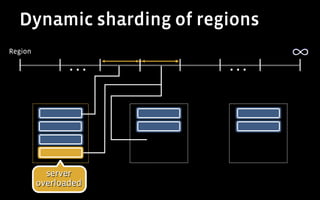
3) HBase's integration with HDFS provides fault tolerance and scalability, while its column orientation enables complex queries on user activity data.




































































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)
















