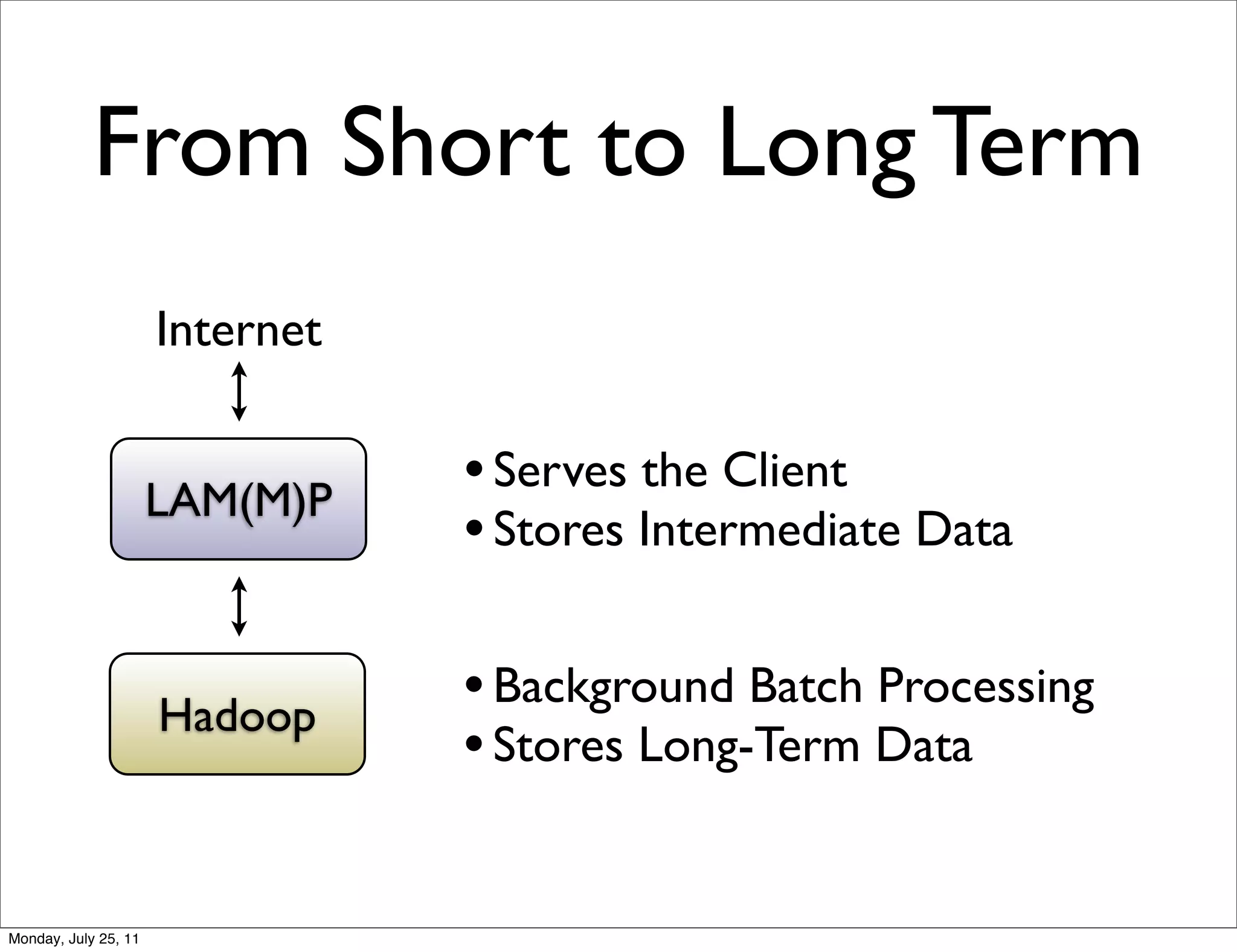
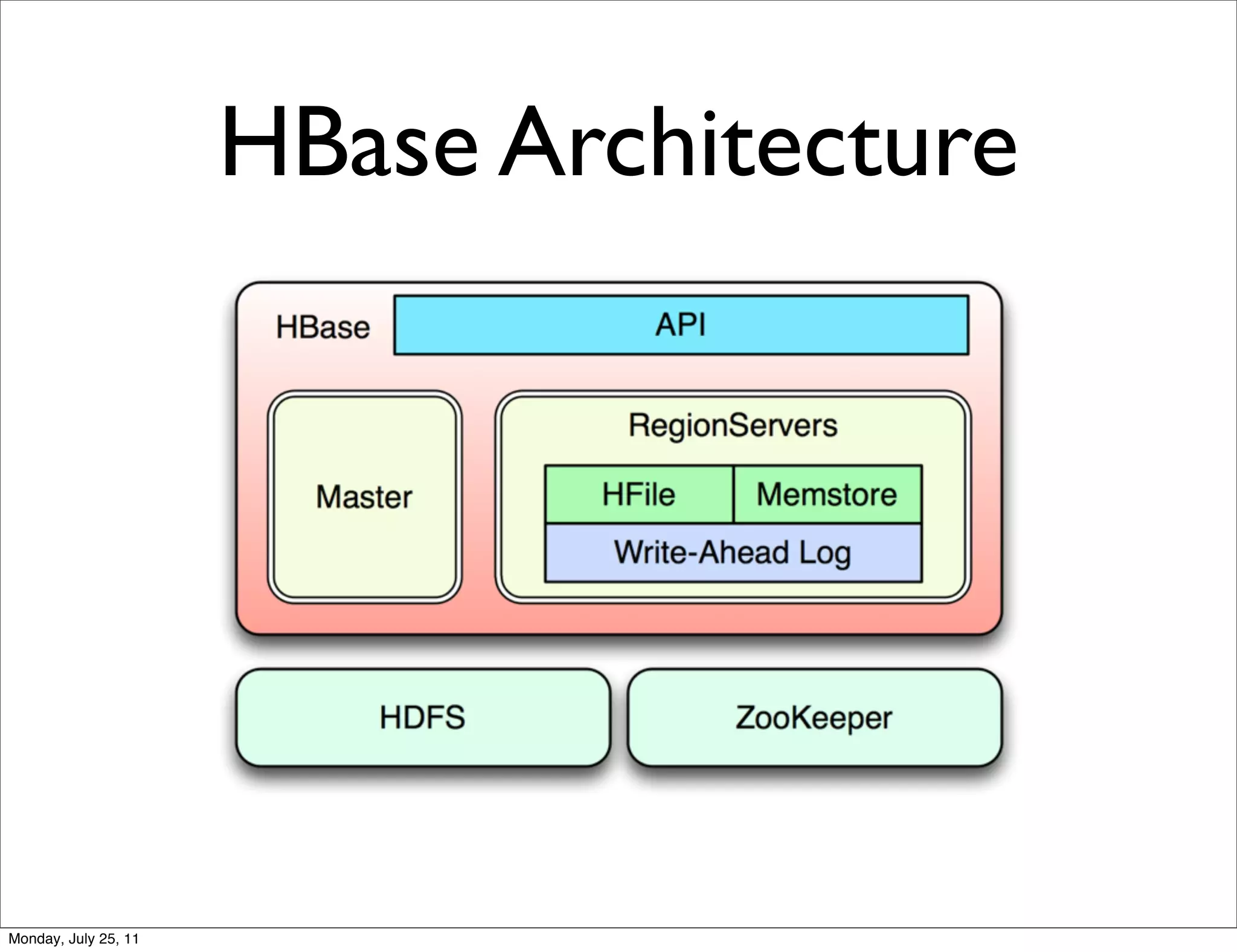
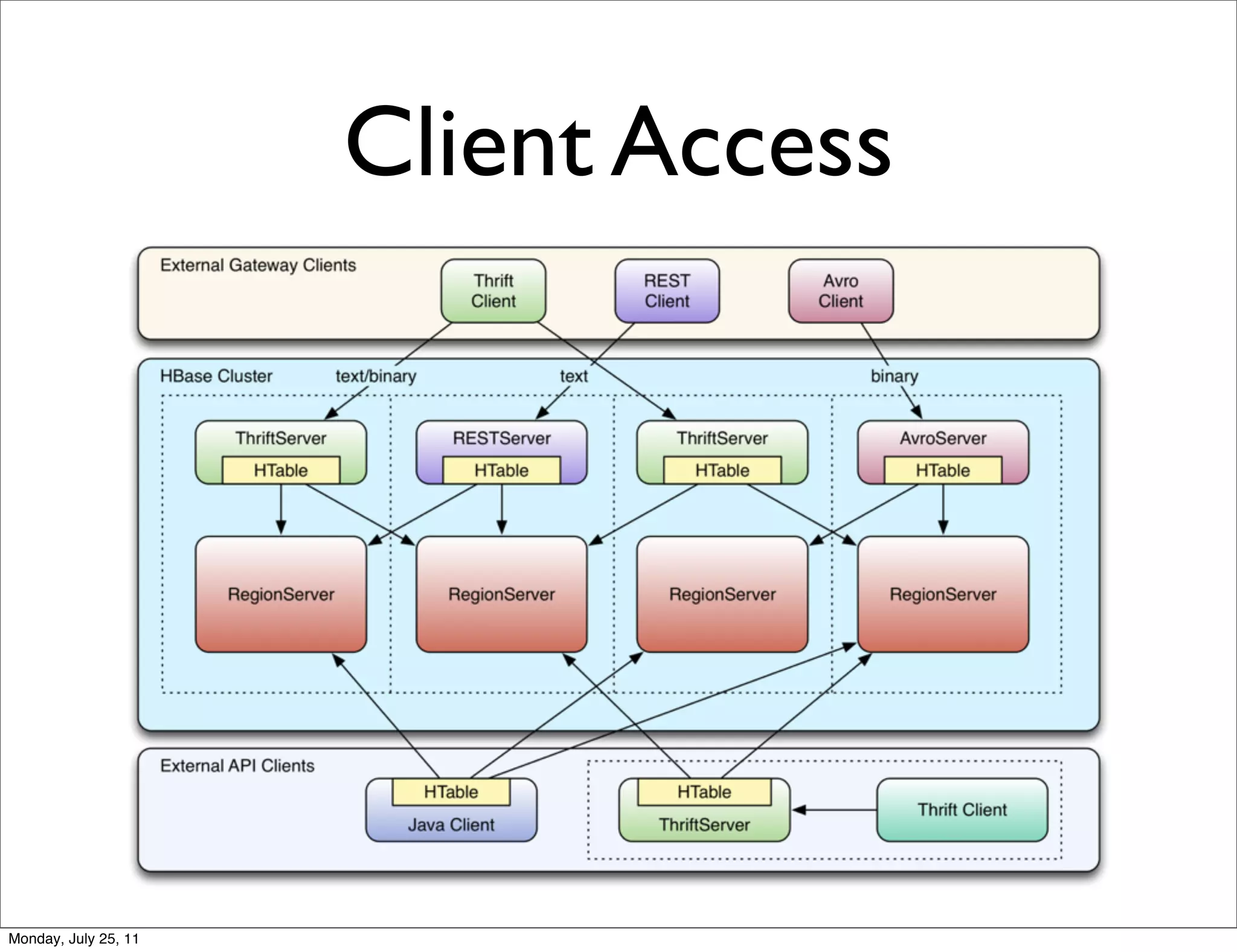
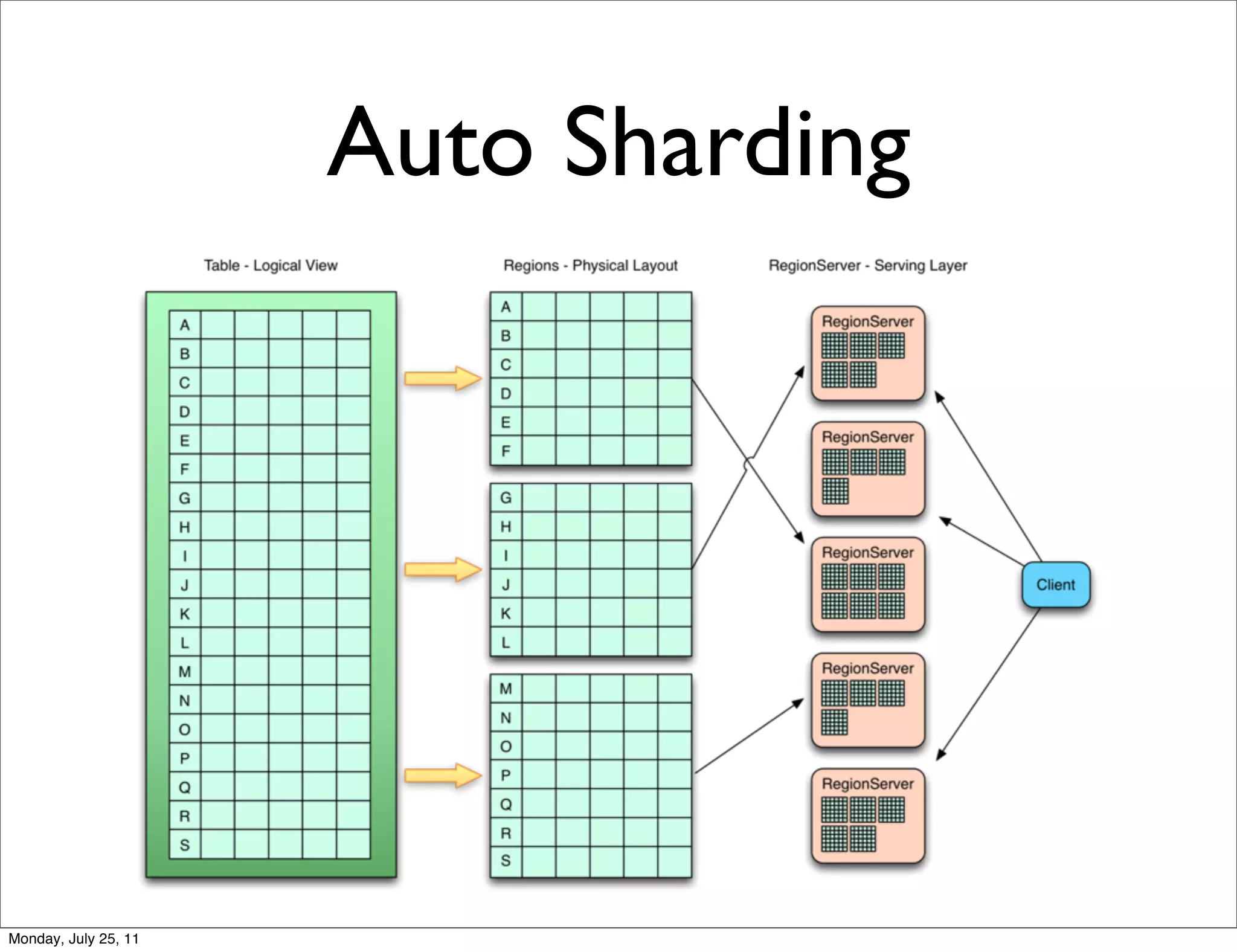
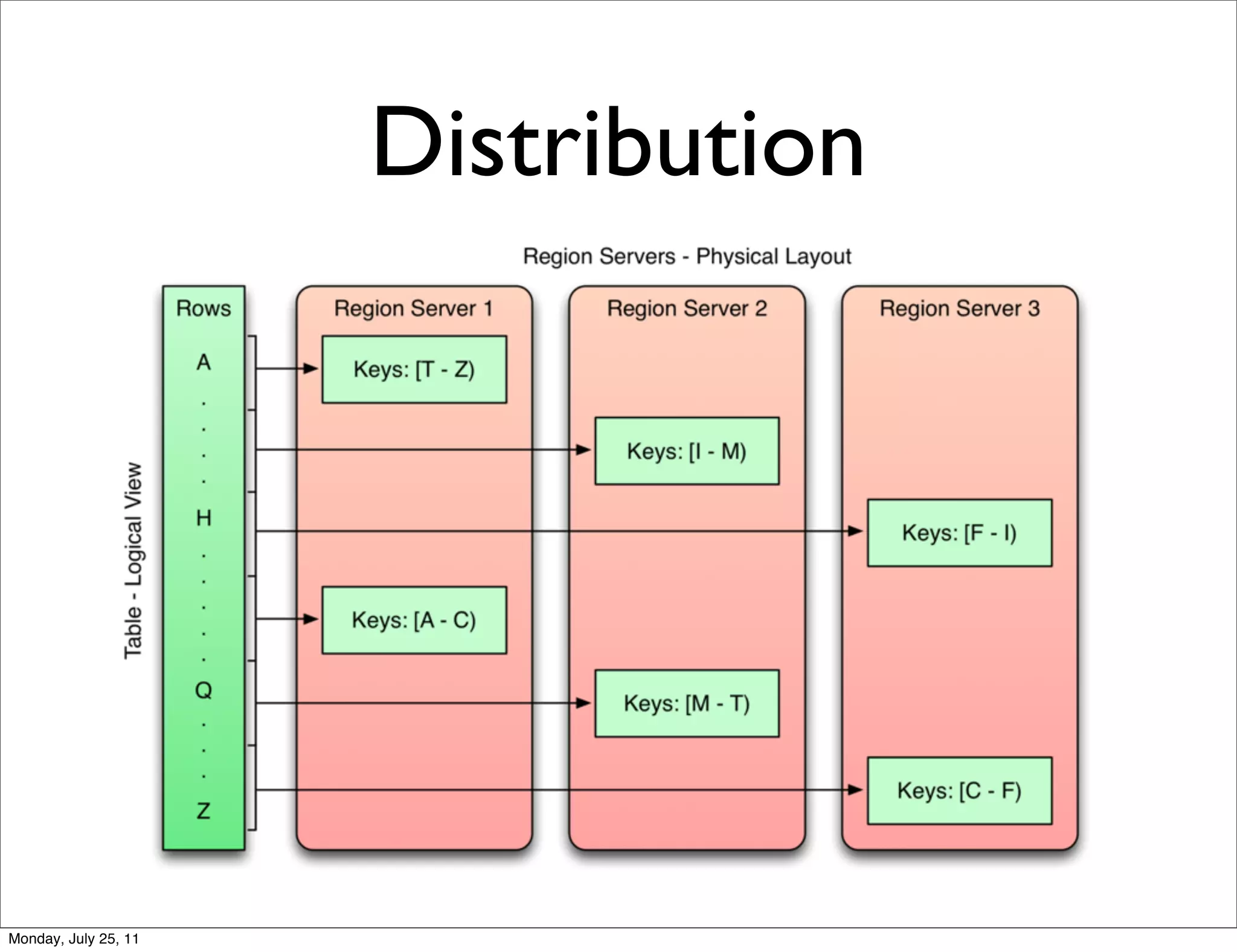
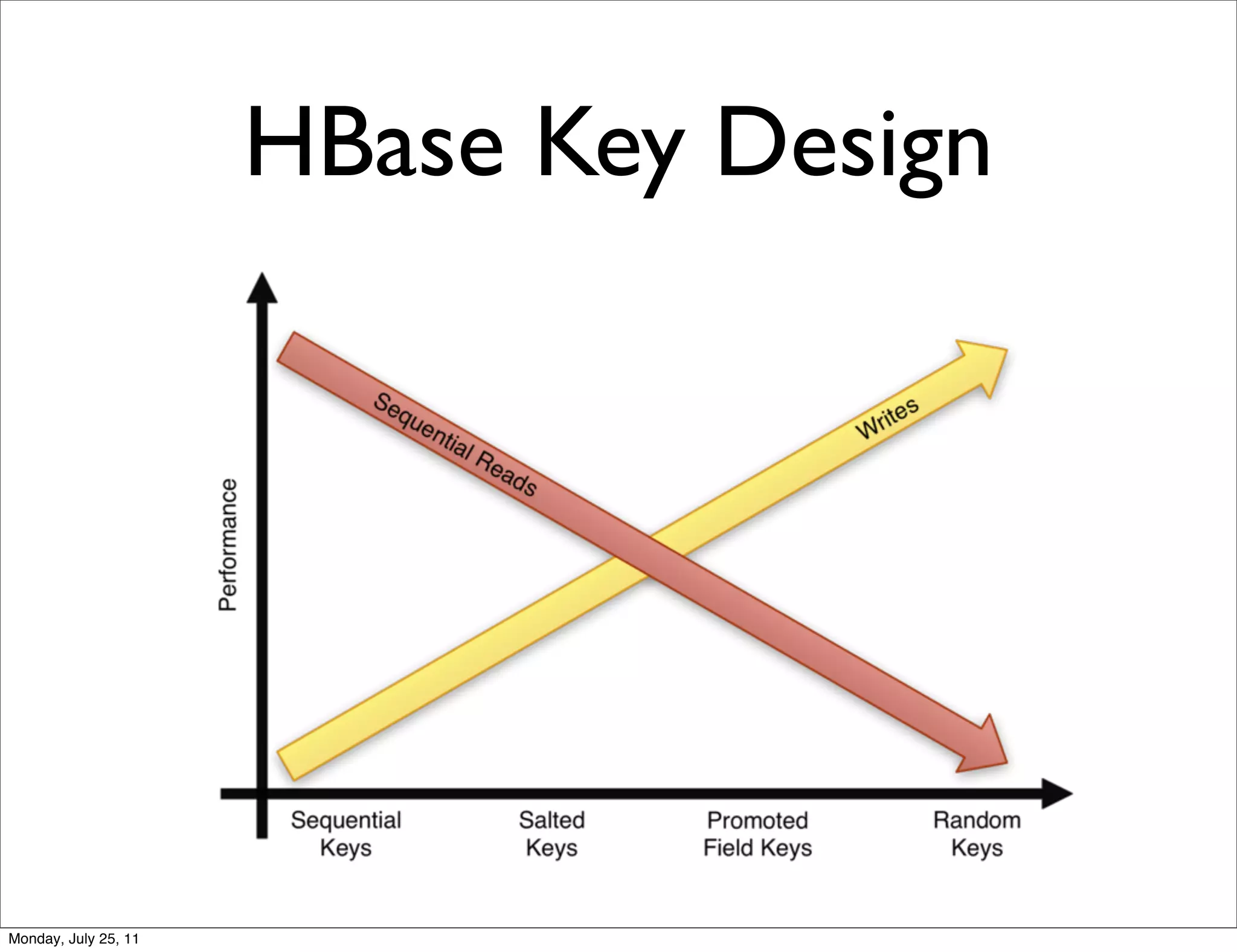
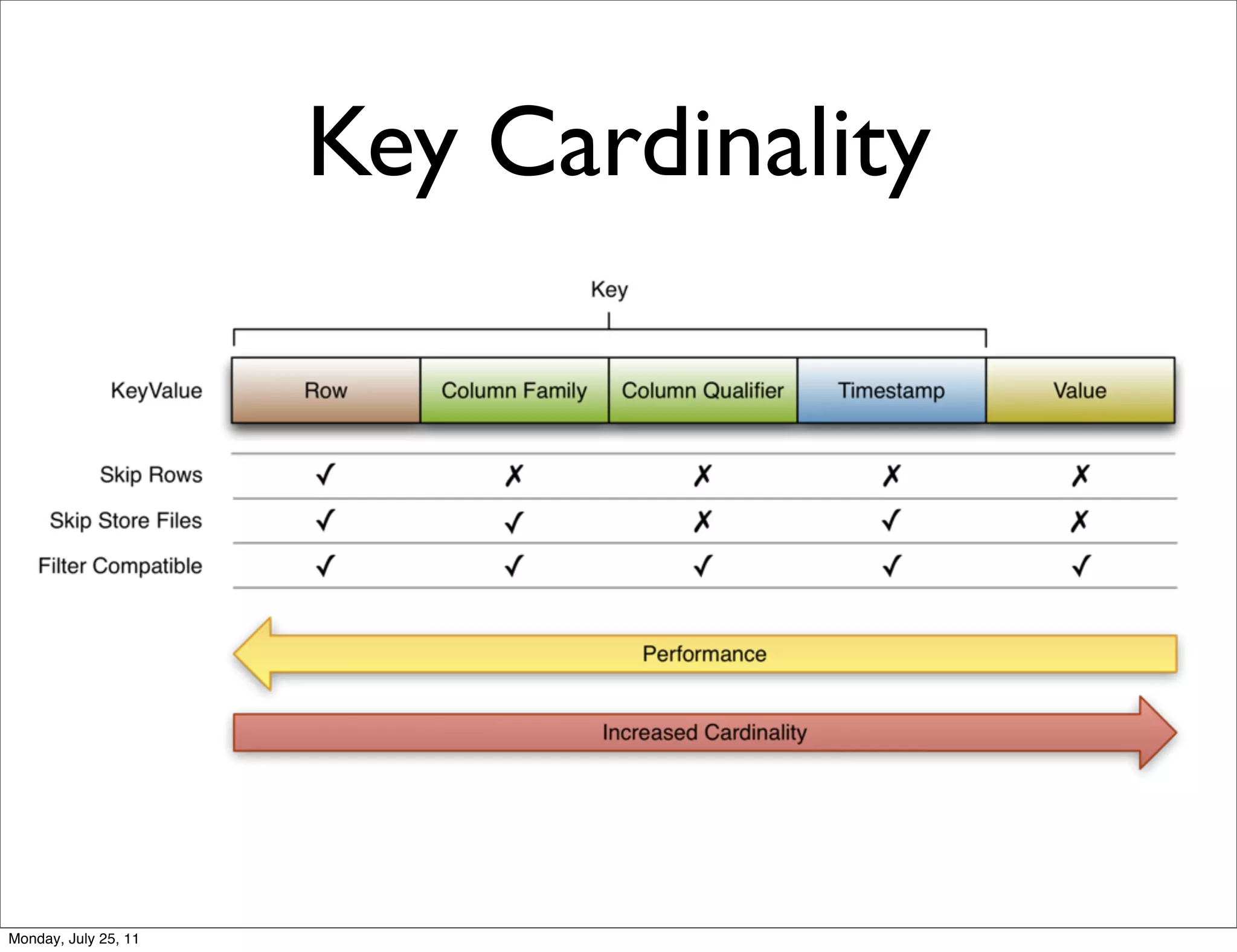
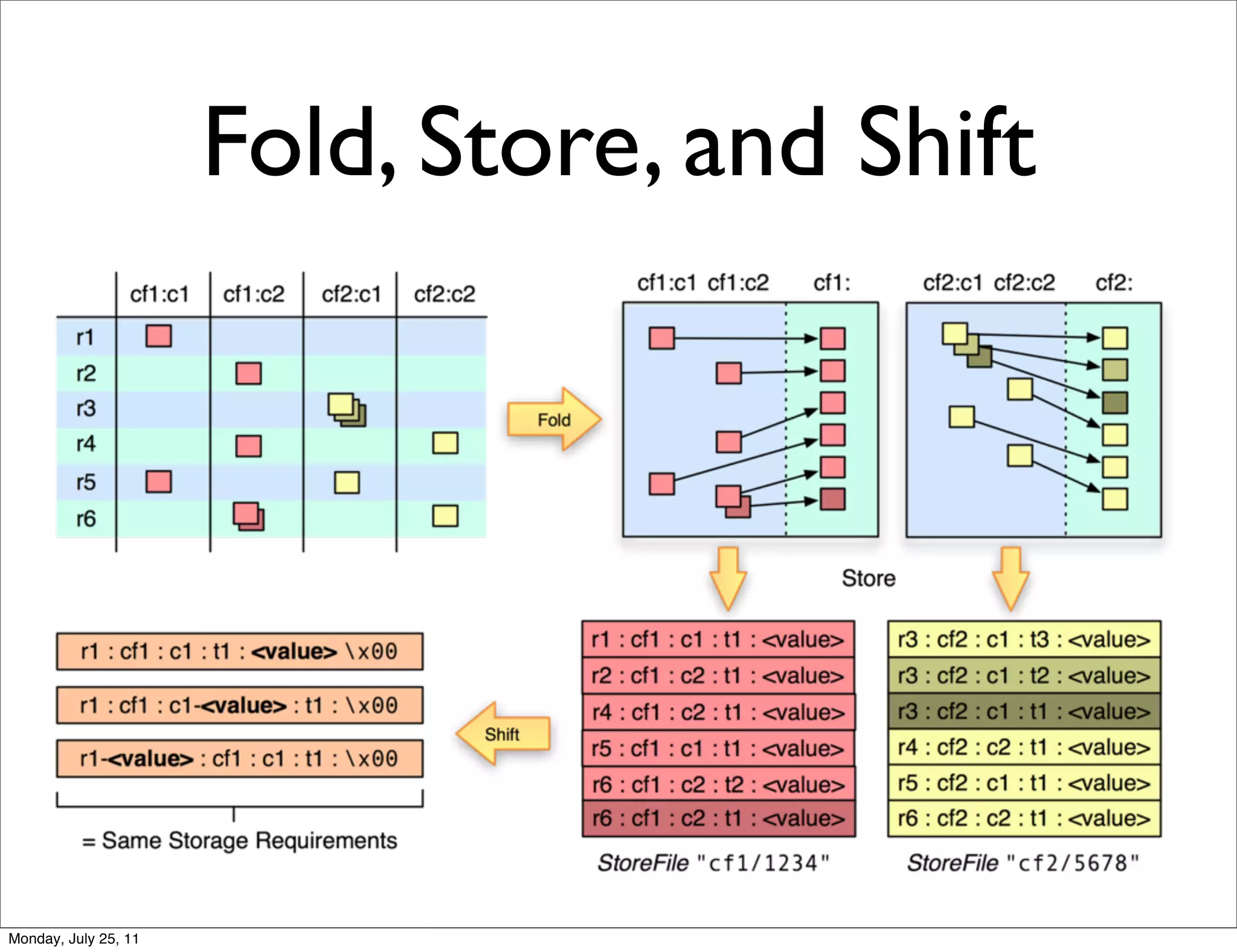
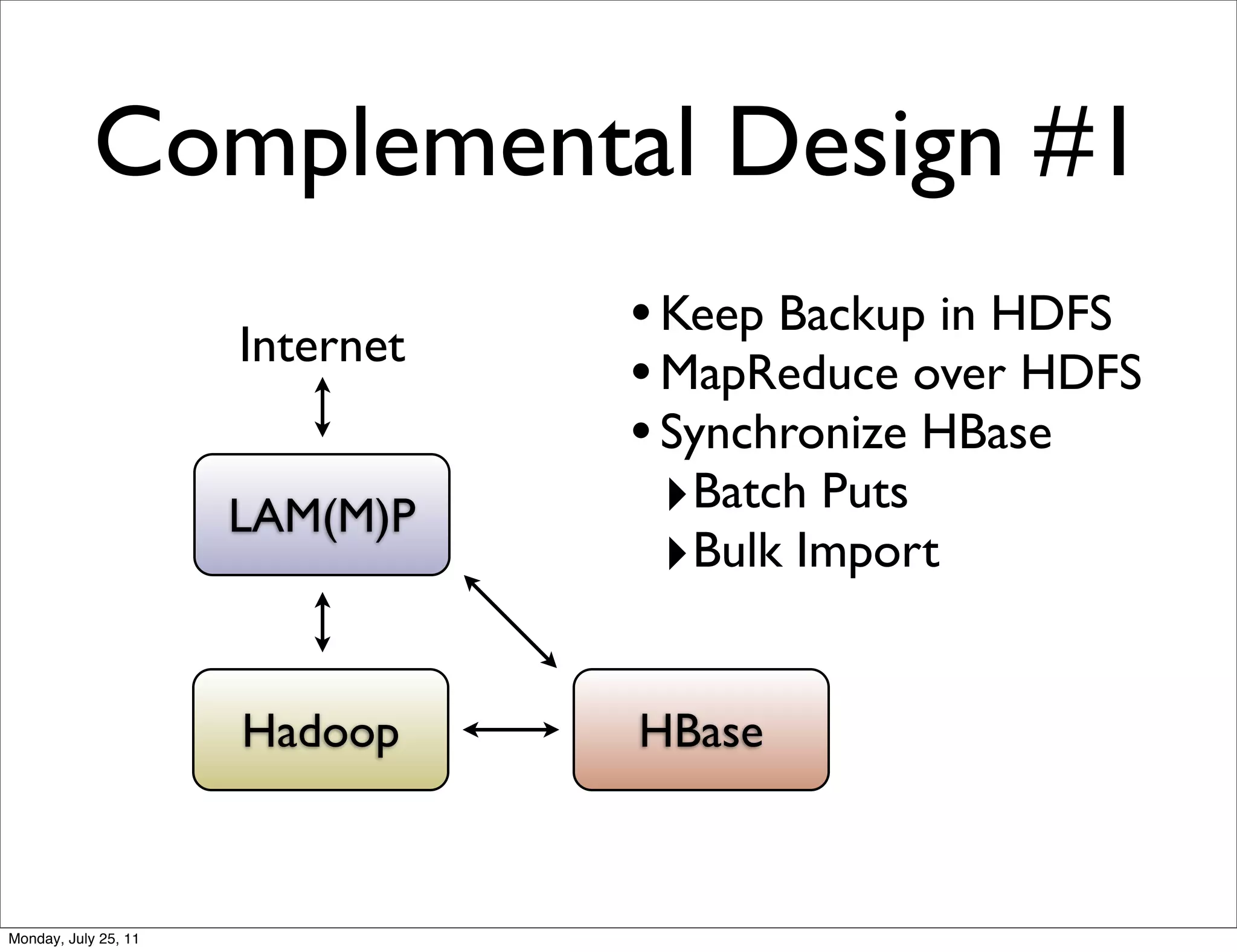
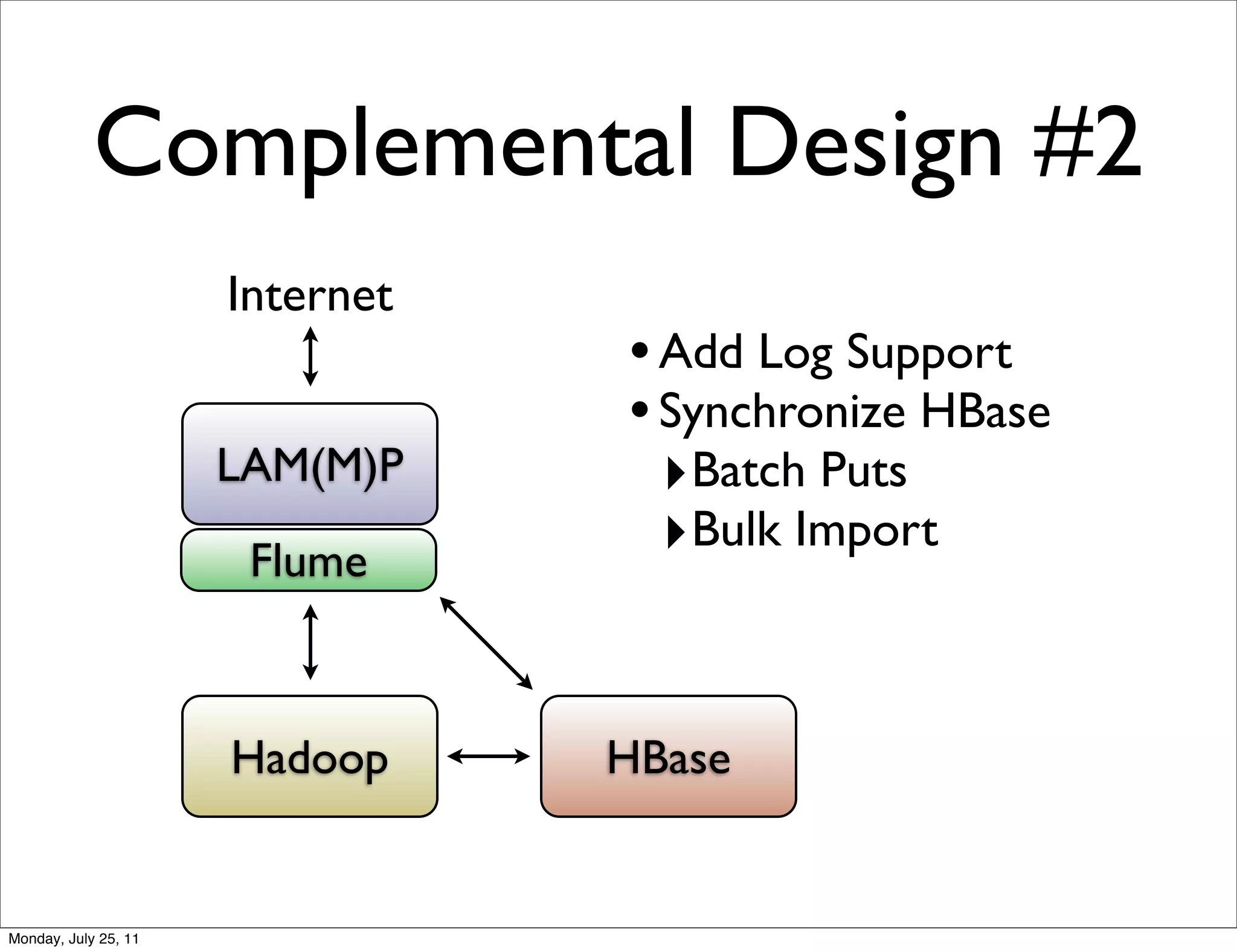
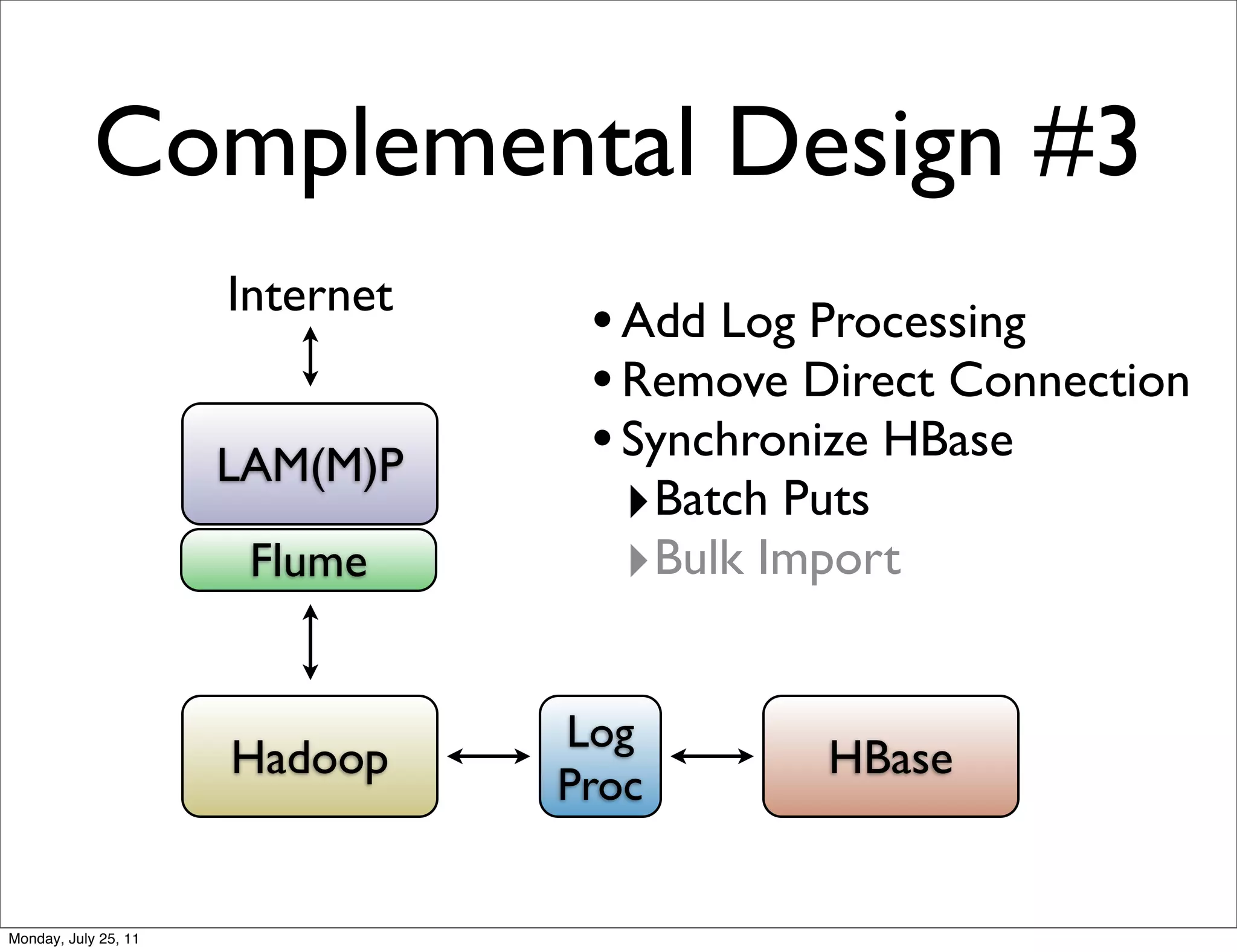
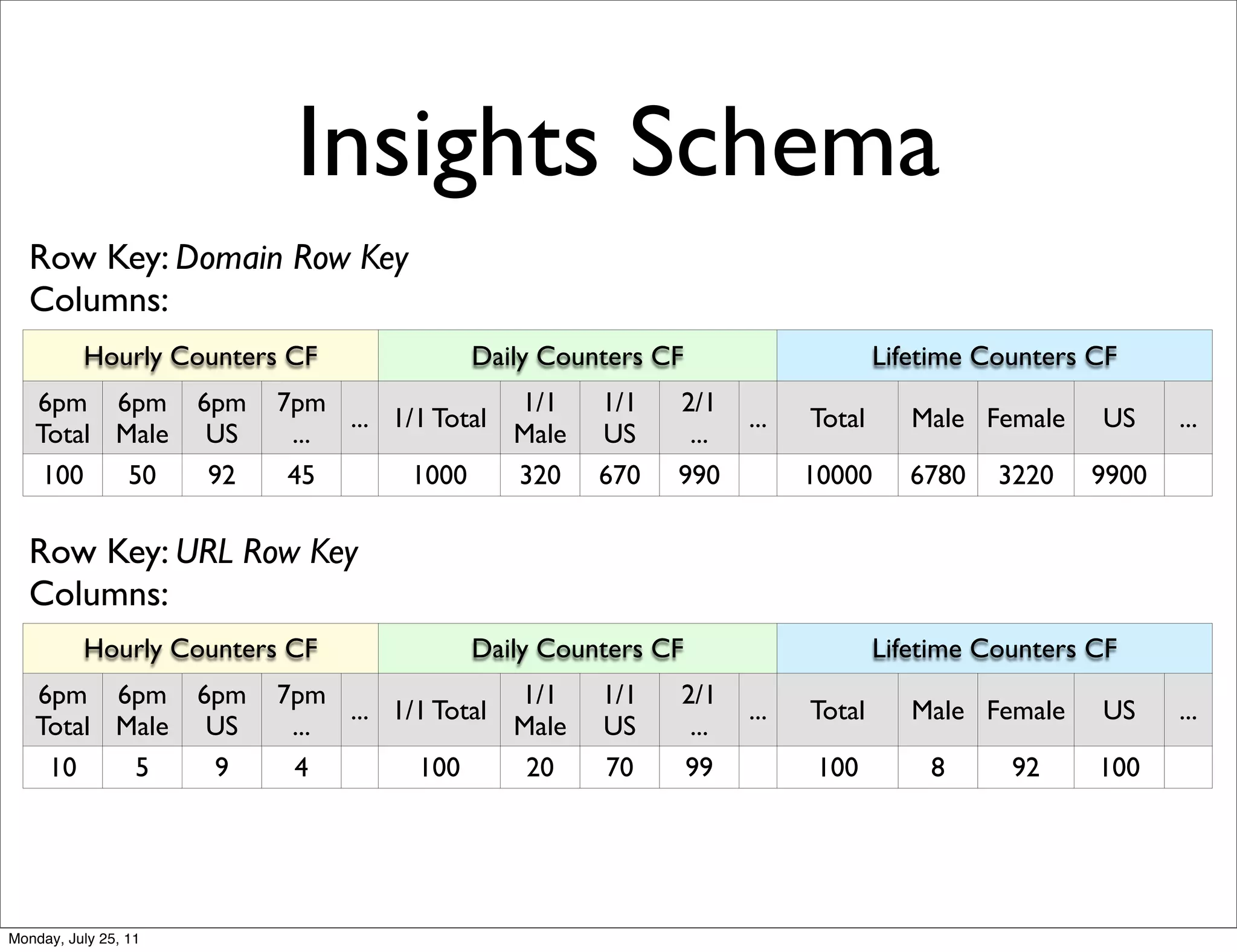
The document discusses realtime analytics using Hadoop and HBase. It begins by introducing the speaker and their experience. It then discusses moving from batch processing with Hadoop to more realtime needs, and how systems like HBase can help bridge that gap. Several designs are presented for using HBase and Hadoop together to enable both realtime and batch analytics on large datasets.