Downloaded 228 times





eBay has been using MongoDB to power several large scale applications due to its ability to scale horizontally and handle high volumes of data and queries. Some key applications summarized include search suggestions which handles high volume lookups, a cloud manager which tracks resource states, and a media metadata store which will store tens of terabytes of image data partitioned across multiple shards. MongoDB provides benefits like flexible schemas, automatic shard rebalancing, and proximity-aware replication which help eBay meet performance and scalability needs for these systems.
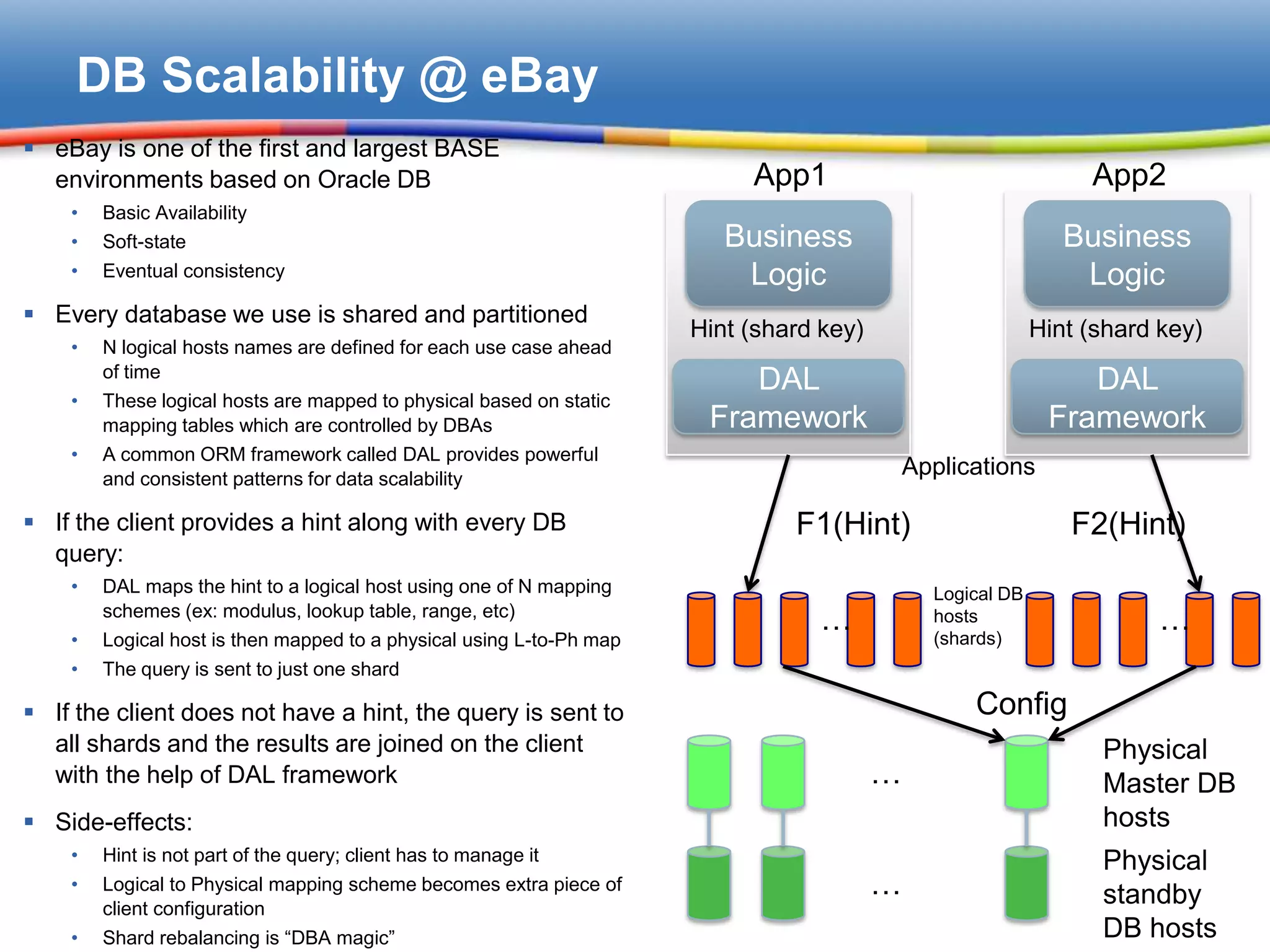
Introduction by Yuri Finkelstein, detailing eBay's good scalability practices with Oracle DB.
eBay identifies key improvements in ORM, schema, and performance for database operations.
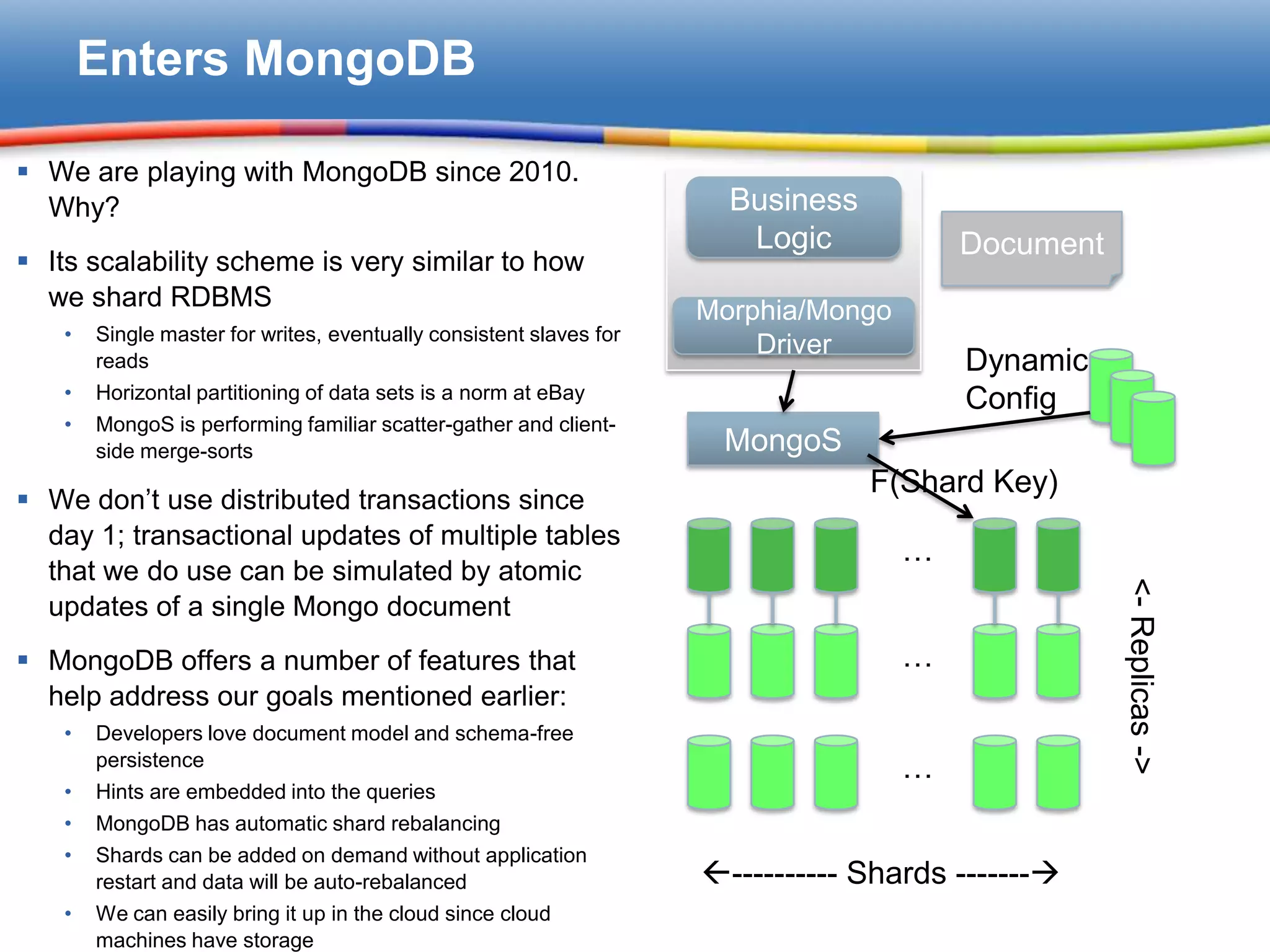
Overview of MongoDB's features aligning with eBay's needs for scalability, including sharding and document modeling.
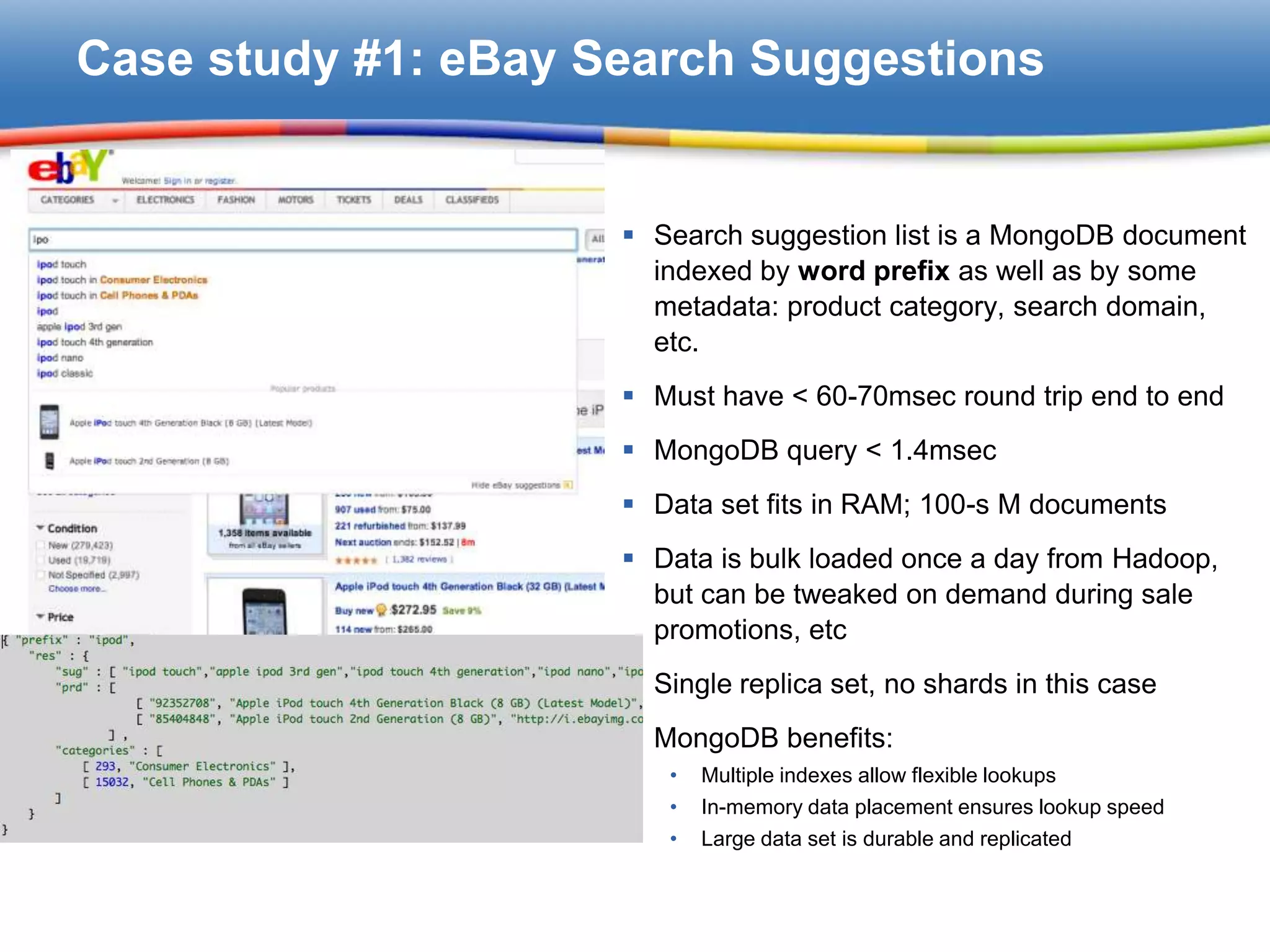
Implementation of MongoDB for efficient search suggestion lists, meeting performance metrics like <1.4msec query time.
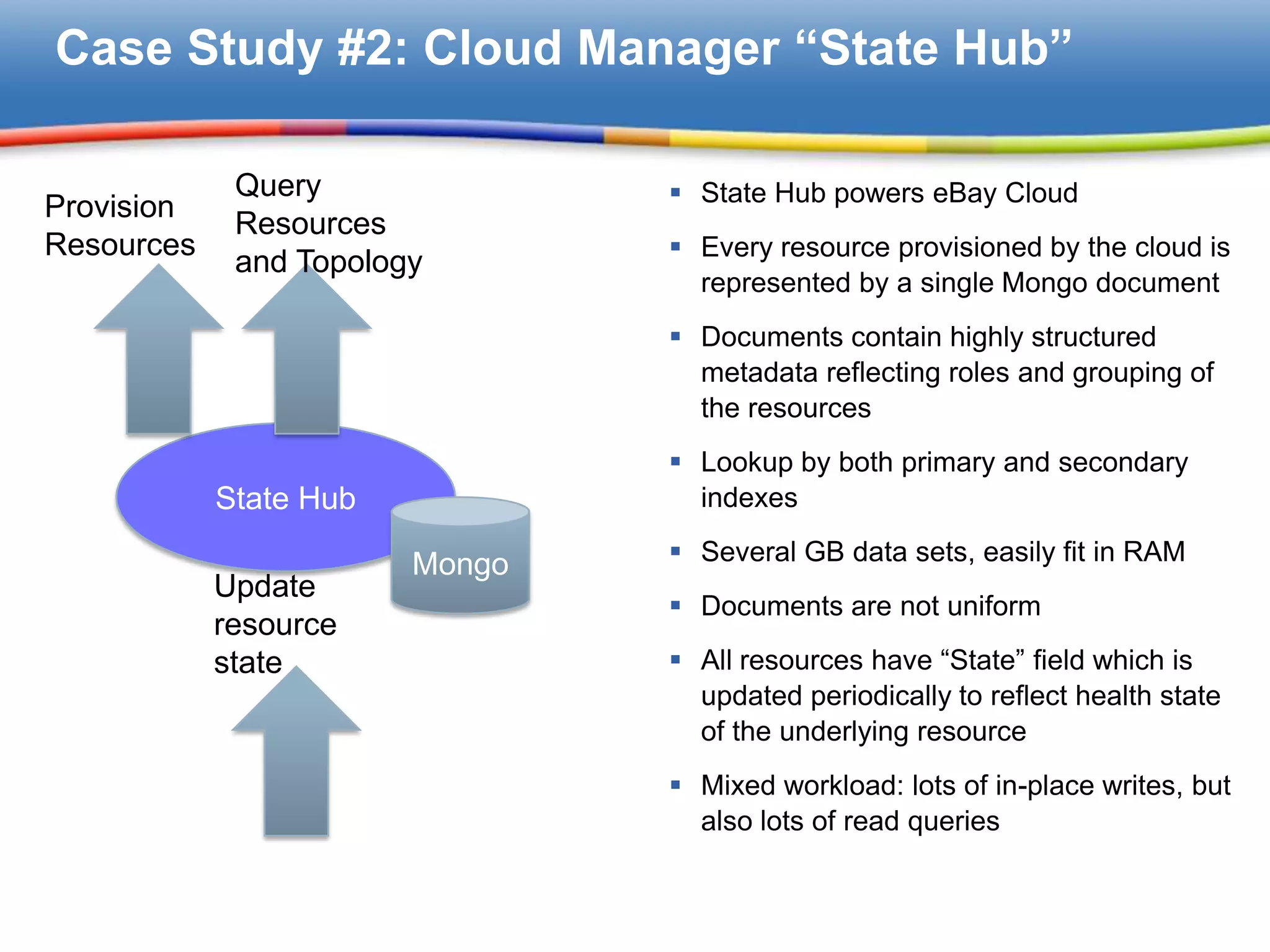
State Hub uses MongoDB for resource representation with structured metadata, accommodating mixed workloads.
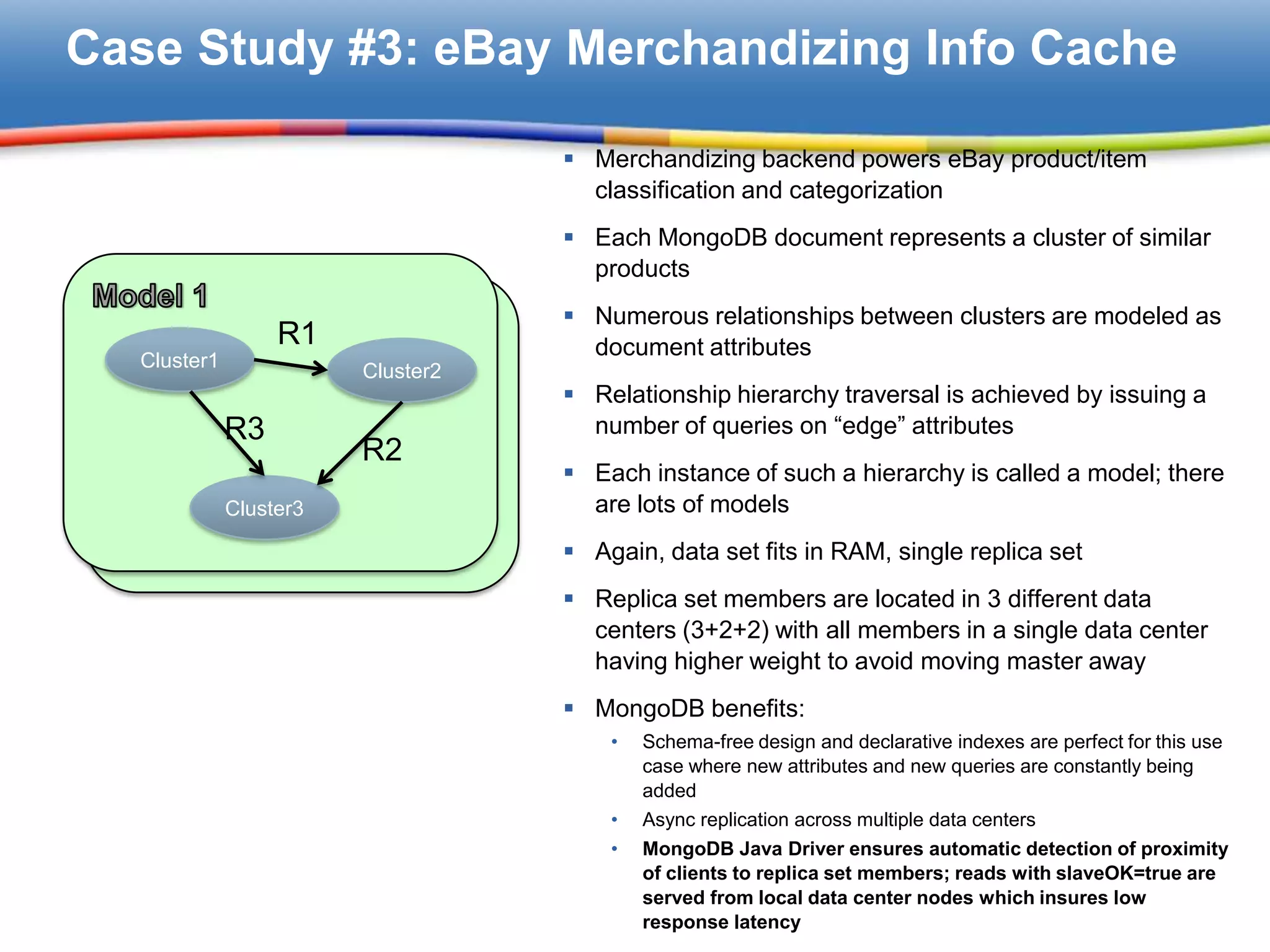
MongoDB stores product classification data with a schema-free design, ensuring low latency and async replication.
Exploratory project using MongoDB to store large media metadata sets while ensuring data reliability and performance.
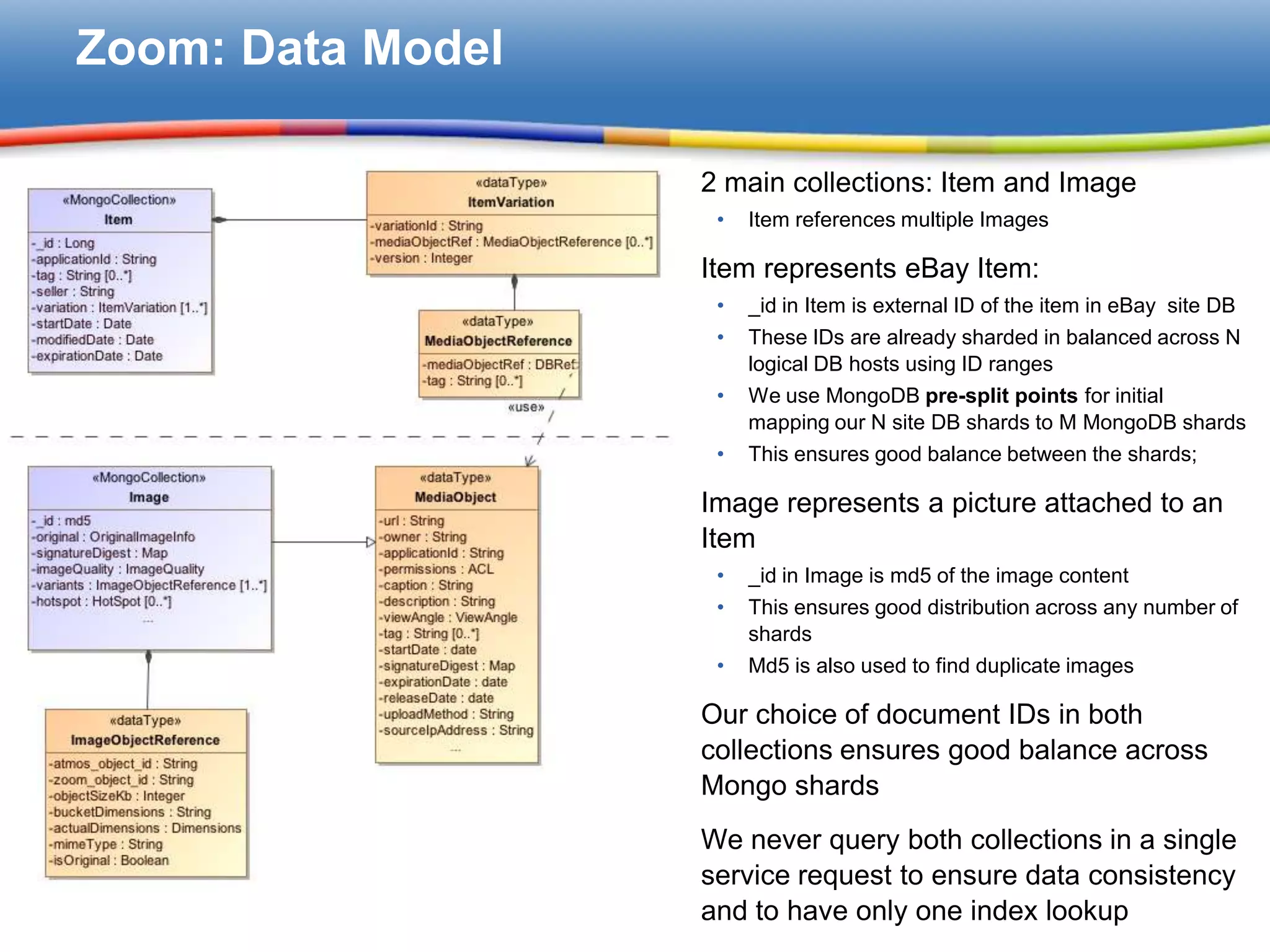
Discussed the data model defining collections and sharding strategies in MongoDB to maintain balance across shards.
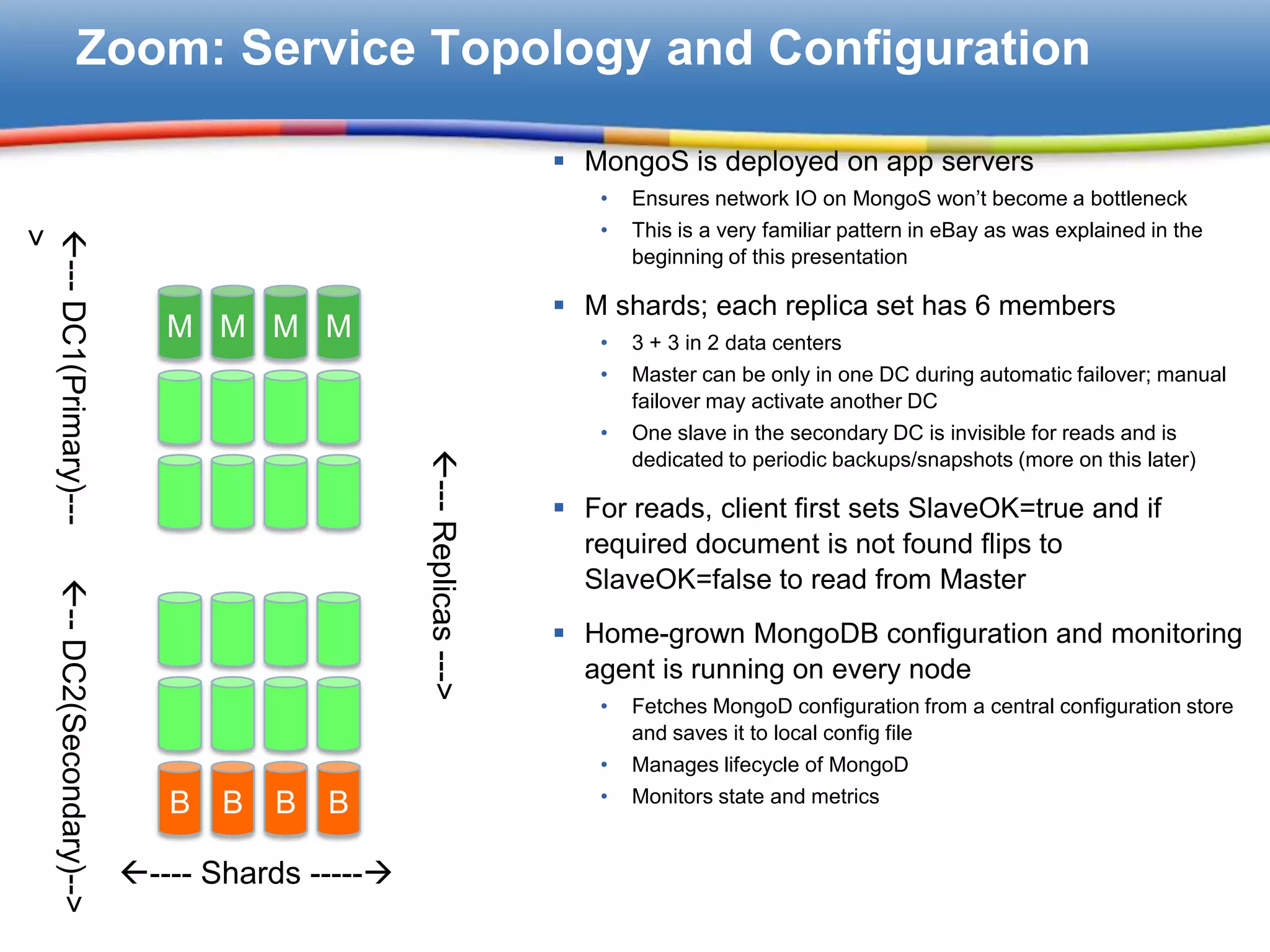
MongoDB's deployment structure, focusing on shard and replica configuration for high availability and performance.
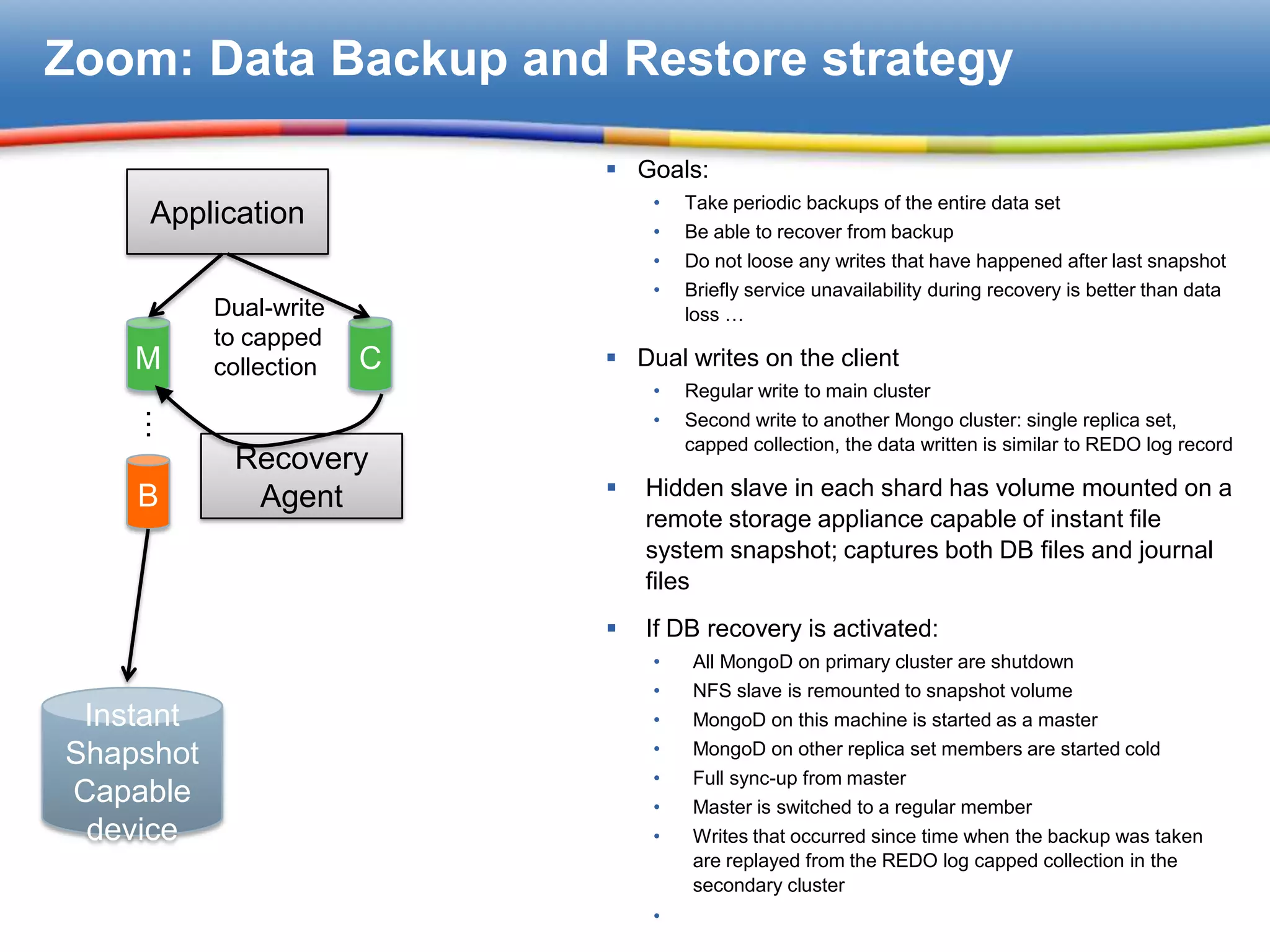
Outlined methods for data backup and recovery through dual writes and instant snapshot capabilities.
Best practices for efficient MongoDB use, including query optimization and handling deletes.
Closing remarks by Yuri with an invitation for questions.










































































![MongoDB .local San Francisco 2020: Powering the new age data demands [Infosys]](https://cdn.slidesharecdn.com/ss_thumbnails/315pminfosysfinalsfoversionvocalpart1-200120221508-thumbnail.jpg?width=640&height=640&fit=bounds)














![[BDD 2025 - Artificial Intelligence] Building AI Systems That Users (and Comp...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-buildingaisystemsthatusersandcompanieslove-251124030845-038f7732-thumbnail.jpg?width=640&height=640&fit=bounds)

















![[BDD 2025 - Artificial Intelligence] AI for the Underdogs: Innovation for Sma...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-aifortheunderdogsinnovationforsmallbusinesses-251124030839-72a599a4-thumbnail.jpg?width=640&height=640&fit=bounds)