Downloaded 163 times




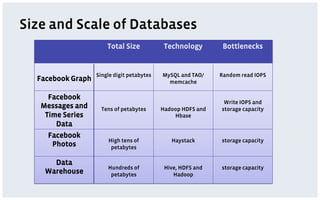
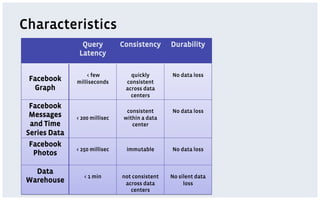

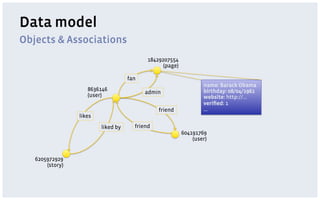

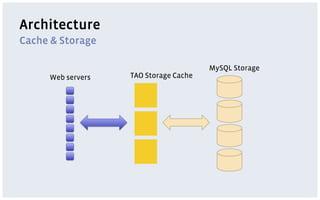
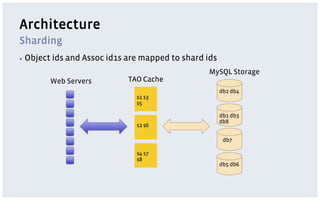


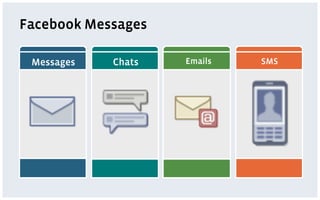





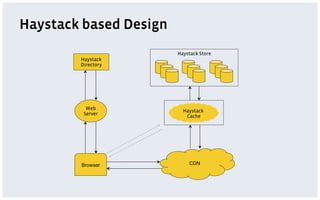


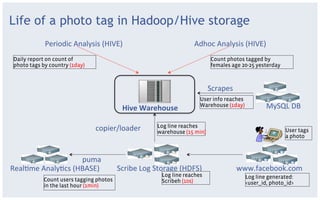
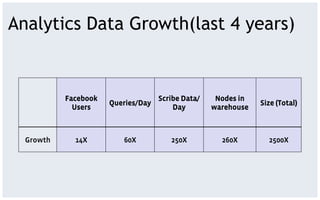









The document discusses various storage systems and data models used by Facebook, focusing on their petabyte-scale data management strategies. It covers OLTP and SLTP workloads, the use of Hadoop and HDFS for analytics, and the architecture of Facebook's social graph and photo storage systems. Key highlights include the performance characteristics of different databases, data growth metrics, and the advantages of using Hadoop for data experiments and crowd-sourced analytics.























































![[Hi c2011]building mission critical messaging system(guoqiang jerry)](https://cdn.slidesharecdn.com/ss_thumbnails/hic2011buildingmissioncriticalmessagingsystemguoqiangjerry-111206111202-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)





























