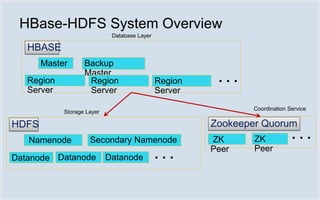
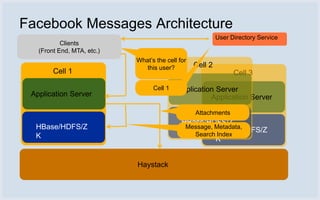
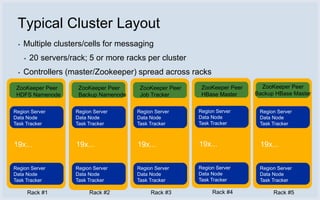
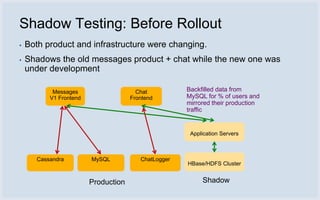
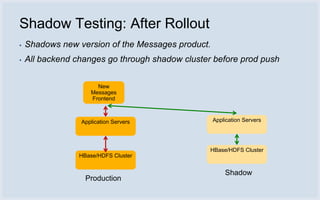
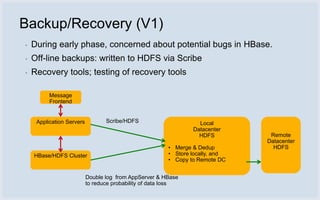
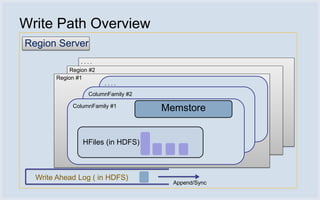
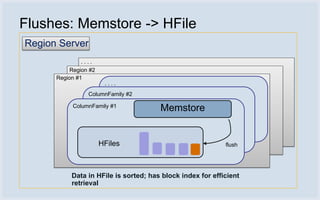
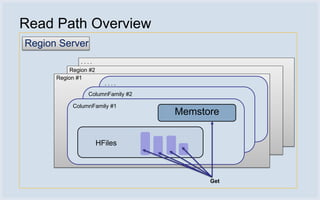
Facebook uses HBase running on HDFS to store messaging data and metadata. Key reasons for choosing HBase include high write throughput, horizontal scalability, and integration with HDFS. Typical clusters have multiple regions and racks for redundancy. Facebook stores small messages, metadata, and attachments in HBase, while larger messages and attachments are stored separately. The system processes billions of read and write operations daily and continues to optimize performance and reliability.








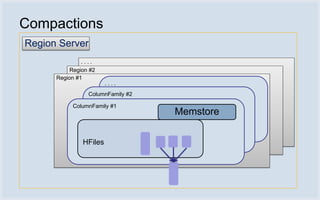



![Performance: Compactions Was
▪ Critical for read performance
▪ Old Algorithm:
#1. Start from newest file (file 0); include next file if:
▪ size[i] < size[i-1] * C (good!)
#2. Always compact at least 4 files, even if rule #1 isn’t met.
Solution:
Now
#1. Compact at least 4 files, but only if eligible files found.
#2. Also, new file selection based on summation of sizes.
size[i] < (size[0] + size[1] + …size[i-1]) * C](https://image.slidesharecdn.com/storageinfrabehindmessages-111128022329-phpapp02/85/Storage-Infrastructure-Behind-Facebook-Messages-23-320.jpg)















![[Hi c2011]building mission critical messaging system(guoqiang jerry)](https://cdn.slidesharecdn.com/ss_thumbnails/hic2011buildingmissioncriticalmessagingsystemguoqiangjerry-111206111202-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)




























































