Downloaded 169 times
![Clusters Paul Krzyzanowski [email_address] [email_address] Distributed Systems Except as otherwise noted, the content of this presentation is licensed under the Creative Commons Attribution 2.5 License.](https://image.slidesharecdn.com/22-clusters-090902071039-phpapp02/85/Clusters-Distributed-computing-1-320.jpg)
![Clusters Paul Krzyzanowski [email_address] [email_address] Distributed Systems Except as otherwise noted, the content of this presentation is licensed under the Creative Commons Attribution 2.5 License.](https://image.slidesharecdn.com/22-clusters-090902071039-phpapp02/75/Clusters-Distributed-computing-1-2048.jpg)








































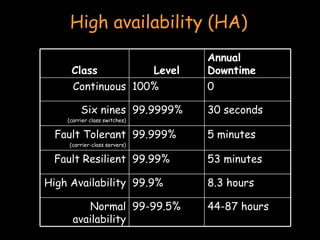














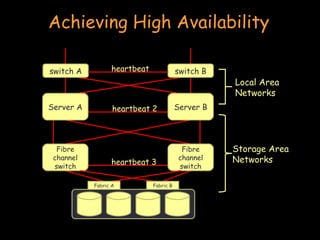
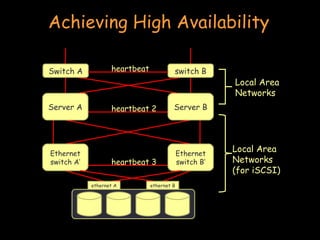




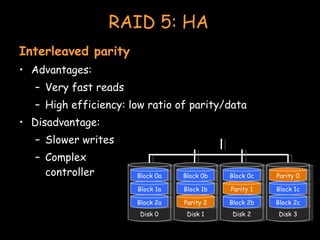



- Clustering involves connecting multiple independent systems together to achieve reliability, scalability, and availability. The systems appear as a single machine to external users. - There are different types of clustering including high performance computing (HPC), batch processing, and high availability (HA). HPC focuses on performance for parallelizable applications. Batch processing distributes jobs like rendering frames. HA aims to provide continuous availability. - Achieving high availability involves techniques like heartbeat monitoring, failover configurations, shared storage, and RAID configurations to ensure redundancy in the event of failures.





































































































