Delphix allows databases to run as software rather than hardware, using less space while maintaining full functionality and performance. It turns database servers into a single, virtual authority that can consolidate databases and instantly provision copies for development, testing, and other non-production uses. This cuts capital expenses by 50% and operational expenses by 90% while accelerating innovation by eliminating the time and costs associated with copying and moving databases between environments.
Confidentiality
The information presented here is
confidential and proprietary to Delphix
Corp.
Please do not share the information
contained herein with other vendors or
potential competitors.
In case you have received a copy of this
presentation without prior authorization
from Delphix Corp. please do not read,
duplicate, or distribute this presentation
and contact us at: legal@delphix.com.
2 >> Strictly Confidential
3.
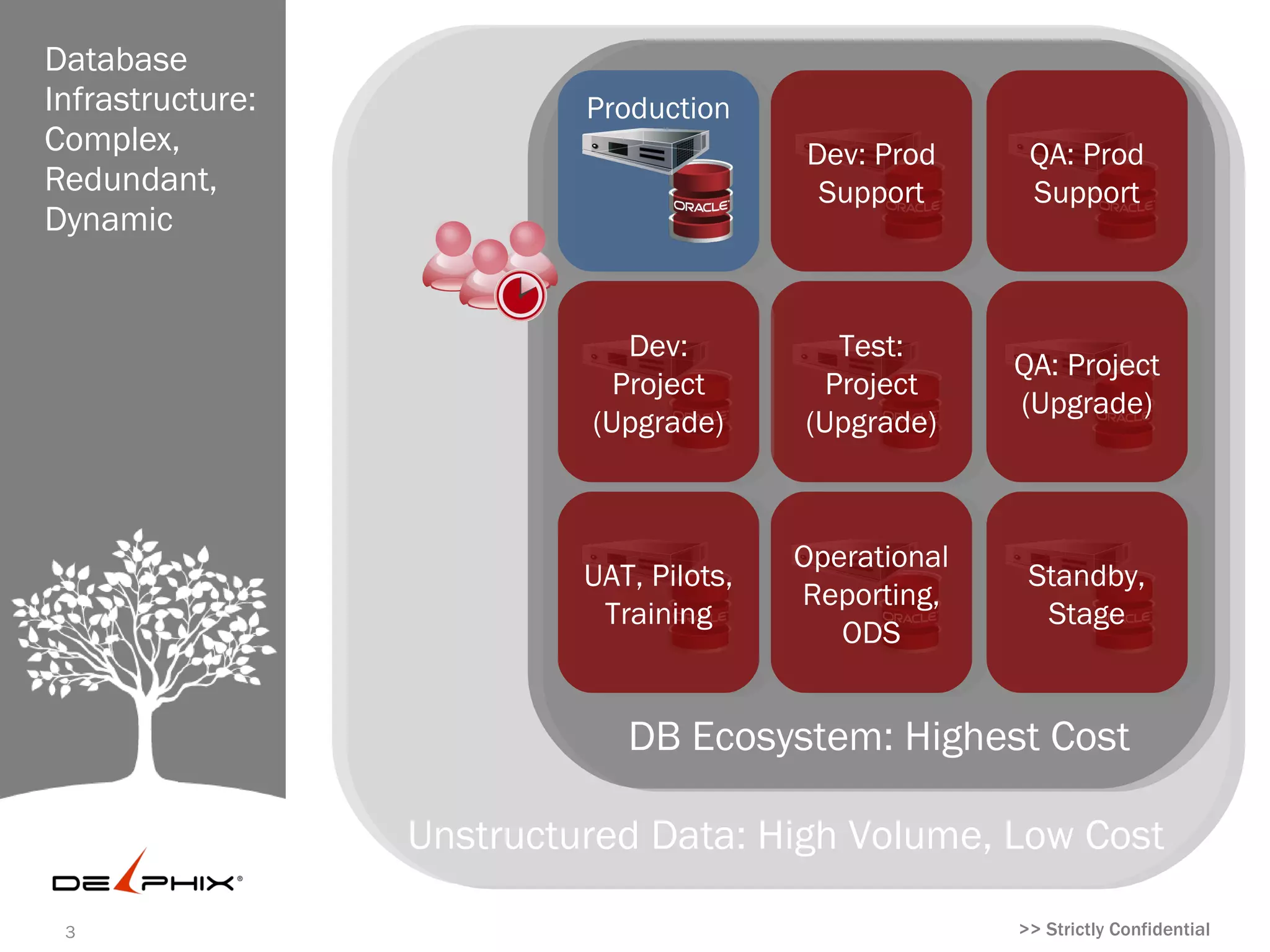
Database Business Critical Applications: Change
Infrastructure: Happens
Complex,
Redundant, Production
Dynamic Dev: Prod QA: Prod
Support Support
Dev: Test: QA:
Project Project Project
(Upgrade) (Upgrade) (Upgrade)
Operation
UAT,
al Standby,
Pilots,
Reporting, Stage
Training
ODS
DB Ecosystem: Highest Cost
Unstructured Data: High Volume, Low Cost
3 >> Strictly Confidential
4.
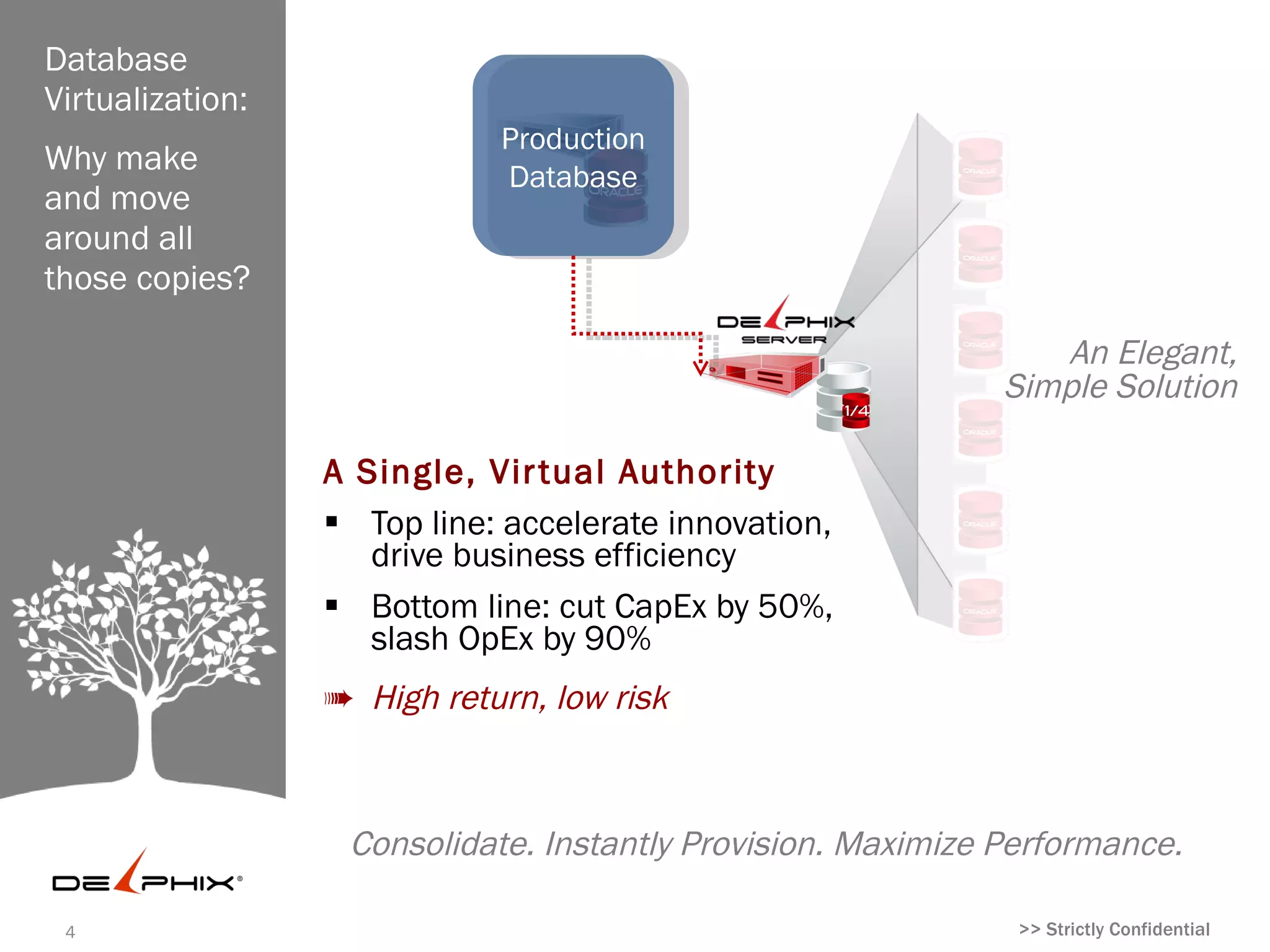
Database
Virtualization:
Production Dev: Prod QA: Prod
Why make Database Support Support
and move
around all
those copies?
Dev: Test: QA:
Project Project Project An Elegant,
Simple Solution
(Upgrade) (Upgrade) (Upgrade)
A Single, Virtual Authority
Top line: accelerate innovation,
Operation
UAT,efficiency
drive business al Standby,
Pilots,
Bottom line: cut CapEx by 50%,
Training
Reporting, Stage
slash OpEx by 90% ODS
➠ High return, low risk
Consolidate. Instantly Provision. Maximize Performance.
4 >> Strictly Confidential
5.
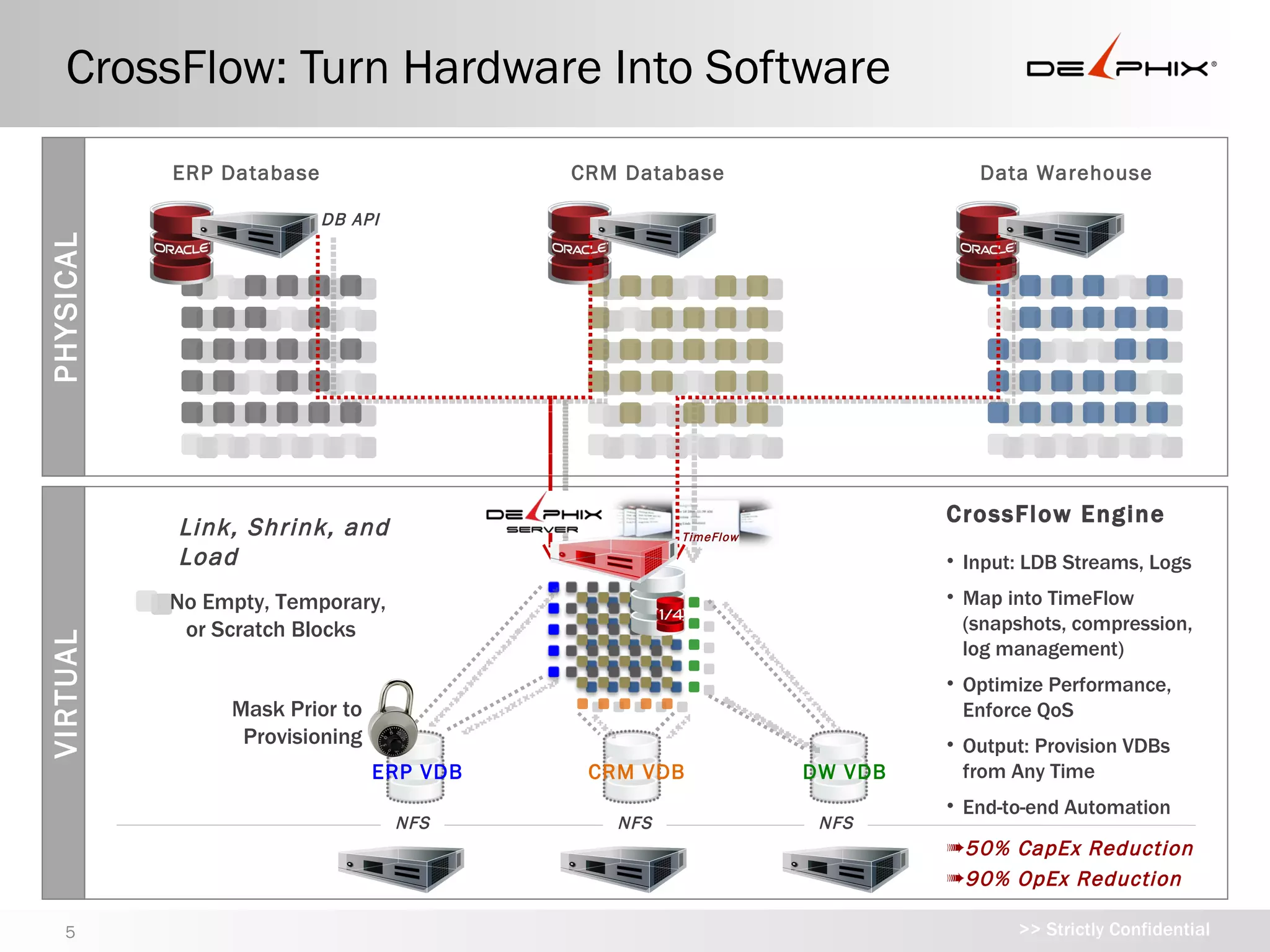
CrossFlow: Turn HardwareInto Software
ERP Database CRM Database Data Warehouse
DB API
PHYSICAL
CrossFlow Engine
Link, Shrink, and TimeFlow
Load • Input: LDB Streams, Logs
No Empty, Temporary, • Map into TimeFlow
or Scratch Blocks (snapshots, compression,
VIRTUAL
log management)
• Output: Provision VDBs
Mask Prior to from Any Time
Provisioning • Optimize Performance,
ERP VDB CRM VDB DW VDB Enforce QoS
• End-to-end Automation
NFS NFS NFS
➠ 50% CapEx Reduction
➠ 90% OpEx Reduction
5 >> Strictly Confidential
6.
Market Opportunity
2007 Storage Software Revenue: $10.9 Billion
(Source: IDC) • TAM (2007): $10.93 billion,
10.4% growth/year
$2,867, 26% $2,825, 26%
• SAM (2007): $4.373 billion,
>10% growth/year
• Database only and
related applications
$483, 4%
$521, 5% $1,930, 18%
$887 , 8% $1,418, 13%
EMC Symantec IBM NetApp Hewlett-Packard CA Other
• 2010 target market: 280,000 Oracle customers
• Additional market drivers
• Datacenter OpEx for DBs
• Elimination of downstream solutions (de-dupe)
• Replacement of DB features
>> Strictly Confidential for Deutsche Bank
6 >> Strictly Confidential
7.
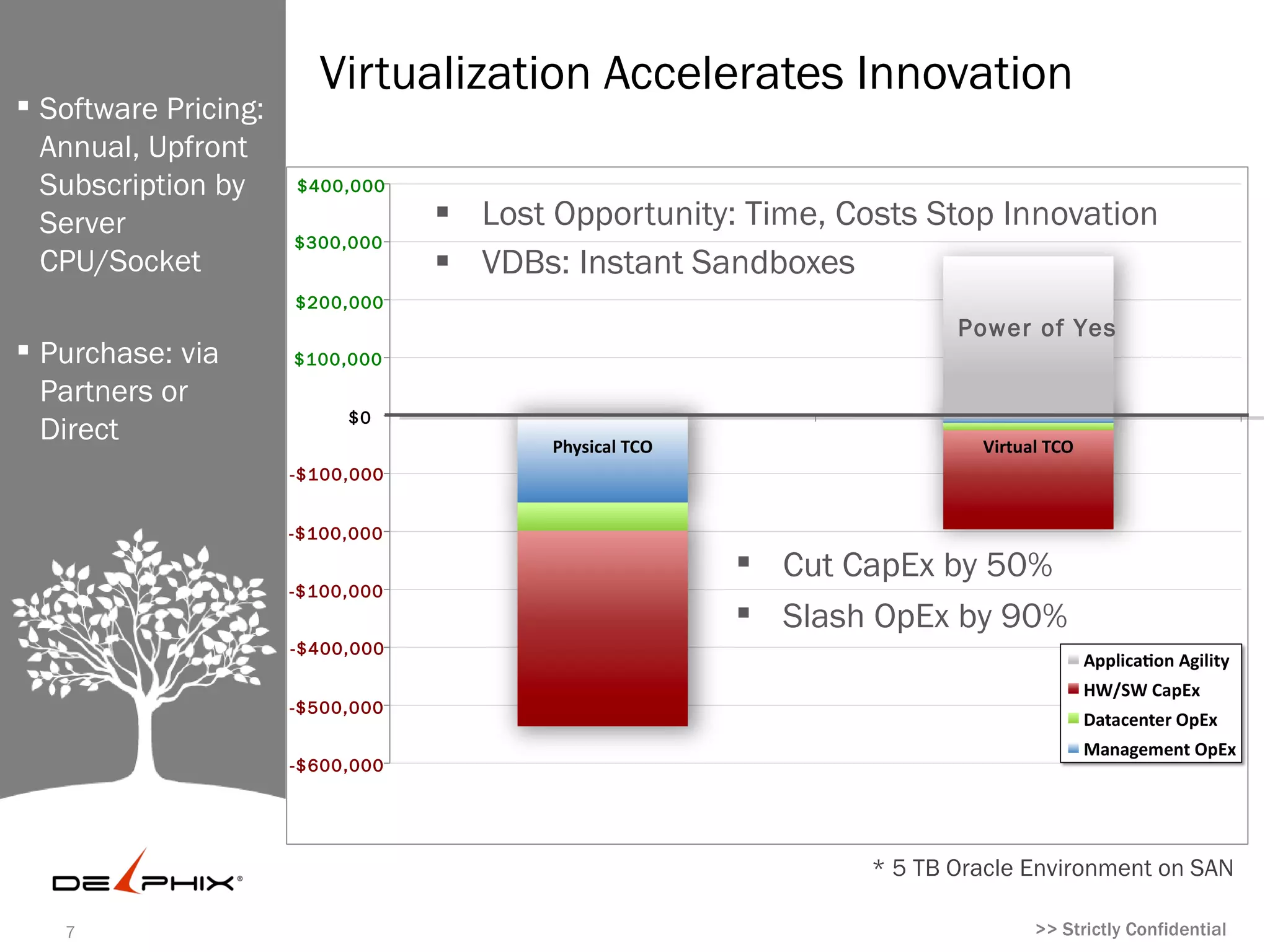
Virtualization Accelerates Innovation
Software
Pricing: Annual,
Upfront $400,000
Subscription by Lost Opportunity: Time, Costs Stop Innovation
$300,000
Server VDBs: Instant Sandboxes
CPU/Socket $200,000
Innovation
$100,000 Value
Purchase: via
$0
Partners or
Direct -$100,000
-$100,000
Cut CapEx by 50%
-$100,000
Slash OpEx by 90%
-$400,000
-$500,000
-$600,000
* 5 TB Oracle Environment on SAN
7 >> Strictly Confidential for Lightspeed
>> Strictly Confidential
8.
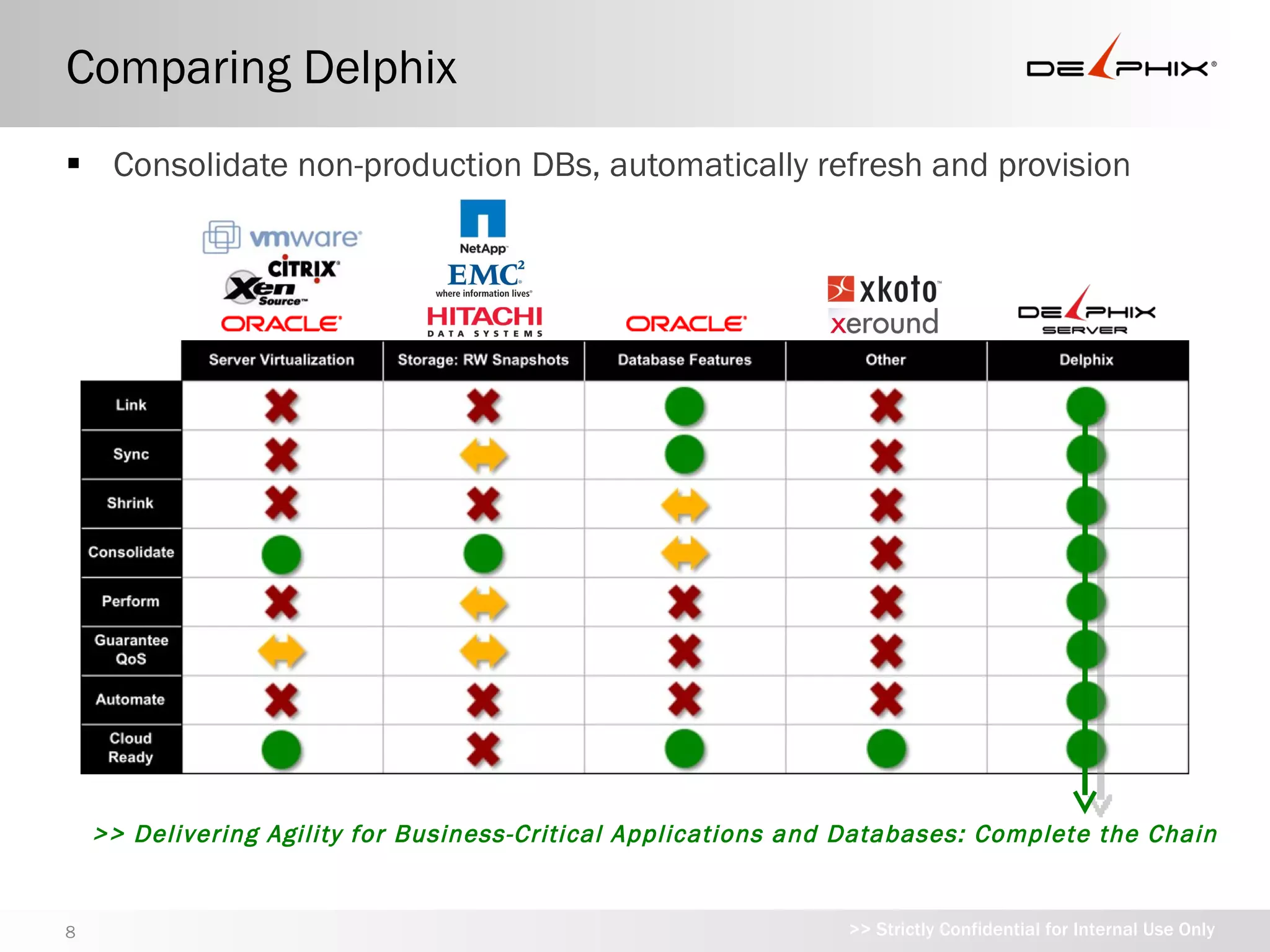
Comparing Delphix
Consolidatenon-production DBs, automatically refresh and provision
>> Delivering Agility for Business-Critical Applications and Databases: Complete the Chain
8 >> Strictly Confidential for Internal Use Only
Team, Board, Advisors
Jedidiah Yueh, President and CEO
Founded Avamar in 1999, sold to EMC in 2006, VP Product Management at EMC
Pioneered de-duplication industry (>$1 billion ’09, Avamar >$1 billion lifetime revenue ‘11)
Harvard, US Presidential Scholar, 10+ patents and patents pending
Alok Srivastava: VP Engineering
Director of Engineering, Clusters and Parallel Storage Technology (RAC), Oracle
Products responsible for ~$2 billion in revenue for Oracle
IIT BS, Wharton MBA, 30+ patents and patents pending
Boris Klots: Chief Architect
Inventor of Cache Fusion, Oracle; 50+ patents and patents pending
PhD Mathematics, Moscow State University
Arnold Silverman: Independent Board Member
Founding board member, Oracle; Co-founder, Business Objects
Other investments: Informatica, Kiva, TimesTen
Chris Schaepe, Lightspeed Managing Director, Board Member
Founder of Lightspeed; Board member, Riverbed
AsheemChandna, Greylock Parnter, Board Member
First US executive at Checkpoint Software; Board Member, Imperva, etc.
Kirk Bowman, Advisor
EVP Field Operations, VMware and EqualLogic
10 >> Strictly Confidential
11.
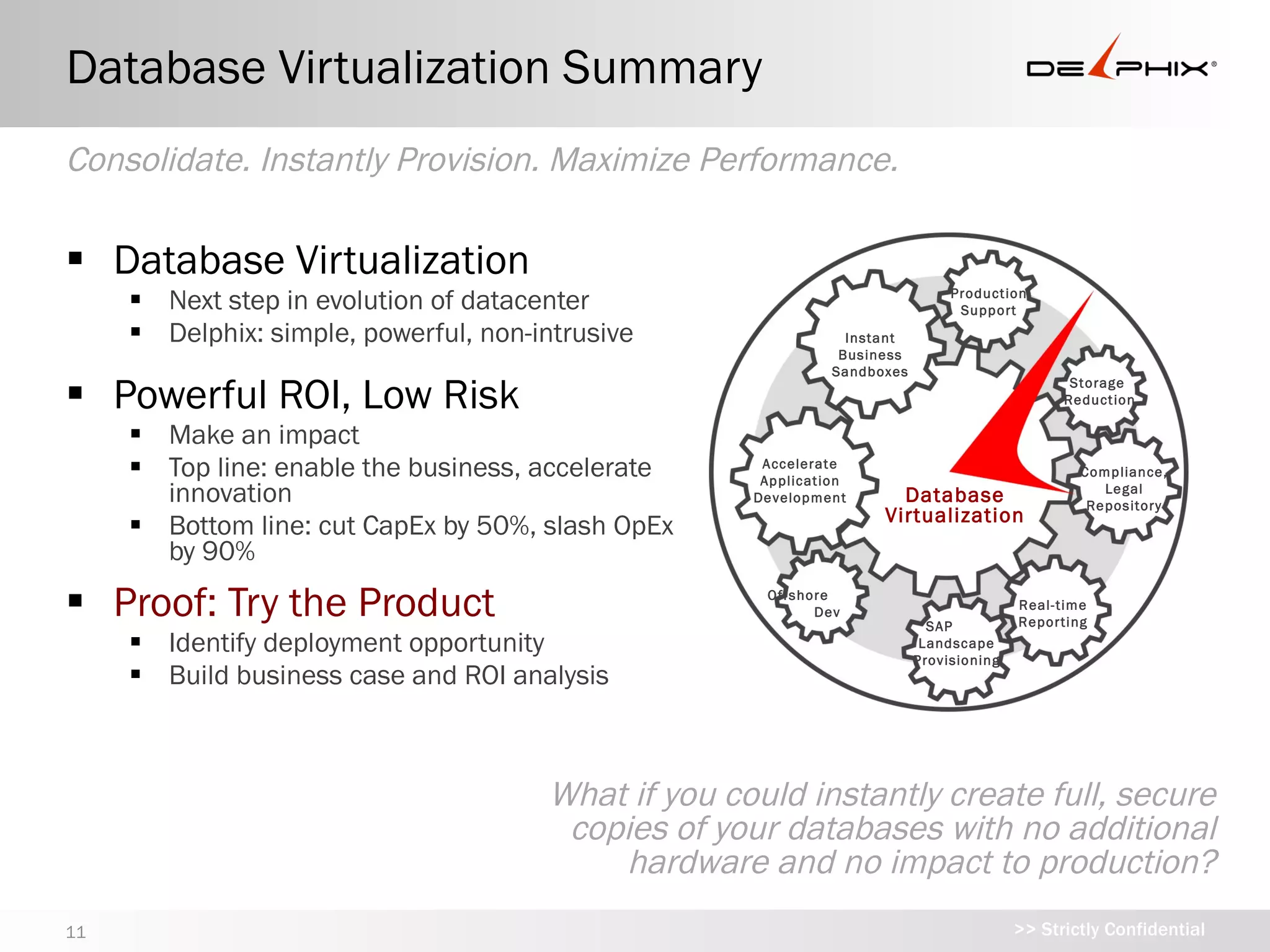
Database Virtualization Summary
Consolidate.Instantly Provision. Maximize Performance.
Database Virtualization
Next step in evolution of datacenter Production
Support
Delphix: simple, powerful, non-intrusive Instant
Business
Sandboxes
Powerful ROI, Low Risk Storage
Reduction
Make an impact
Top line: enable the business, accelerate Accelerate
Application
Compliance,
Legal
innovation Development Database Repository
Virtualization
Bottom line: cut CapEx by 50%, slash
OpEx by 90%
Proof: Try the Product
Offshore
Real-time
Dev
SAP Reporting
Identify deployment opportunity
Landscape
Provisioning
Build business case and ROI analysis
What if you could instantly create full,
secure copies of your databases with no
additional hardware and no impact to
production?
11 >> Strictly Confidential
#2 Delphix is a database virtualization software company that turns expensive database infrastructure into software that can run in a fraction of the space, while preserving full functionality and performance.
#4 Problem: database ecosystem redundant, dynamic, expensive Most datacenters spend a great deal managing unstructured data, but they spend the most pound-for-pound in the database ecosystem. If you zoom into the database ecosystem, the production application and database is only the tip of the iceberg, as little as 10% of the total infrastructure footprint and costs. Most enterprises are unaware of the full extent of the redundancy and complexity required in regular operations. Due to the high business criticality of applications like ERP and CRM, enterprises generally create multiple copies of their database infrastructure before making even small changes or improvements. For most important applications, a full copy of infrastructure exists for development and QA for production support—to help troubleshoot problems if errors occur in the database or application. In addition, typical environments will create two more copies for dev and QA for projects—such as an application or database upgrade, update, or patch, which come out from vendors monthly or quarterly. In enterprises that develop or customize applications, even more copies are created in non-production environment for dev, test, QA, and staging. Even worse, all this redundancy gets magnified by the need to constantly move the data. As applications grow and change, databases have to be refreshed in development, then moved to testing, QA, staging, and back to production. For projects, which come regularly, development has to be frequently refreshed and moved through the cycle; using stale or partial data can prolong timelines or impede proper testing. Other copies, such as staging for data warehouses, have to be refreshed weekly, nightly, or even more frequently. It takes the average IT organization 10 hours to 10 weeks to provision a new copy of a database from one environment to another, navigating internal procurement processes and coordinating among DBAs, server, storage, and backup teams—an enormous operational expense.
#5 Solution and benefits: database virtualization At Delphix, we asked a simple question: why make and move around all these copies? What if you could have a single virtual authority that stayed synchronized with production? You could then serve all the copies needed in enterprises off a single shared footprint. If you could do that, you could really empower IT to better service the business—delivering on critical requests from lines of business to improve applications that drive sales or operational efficiency. You could spend less on infrastructure, while simplifying operational IT complexity. Best of all, if you designed the solution correctly, you could achieve all of this with no changes required to production, so you could get a high return on investment, at very low risk.
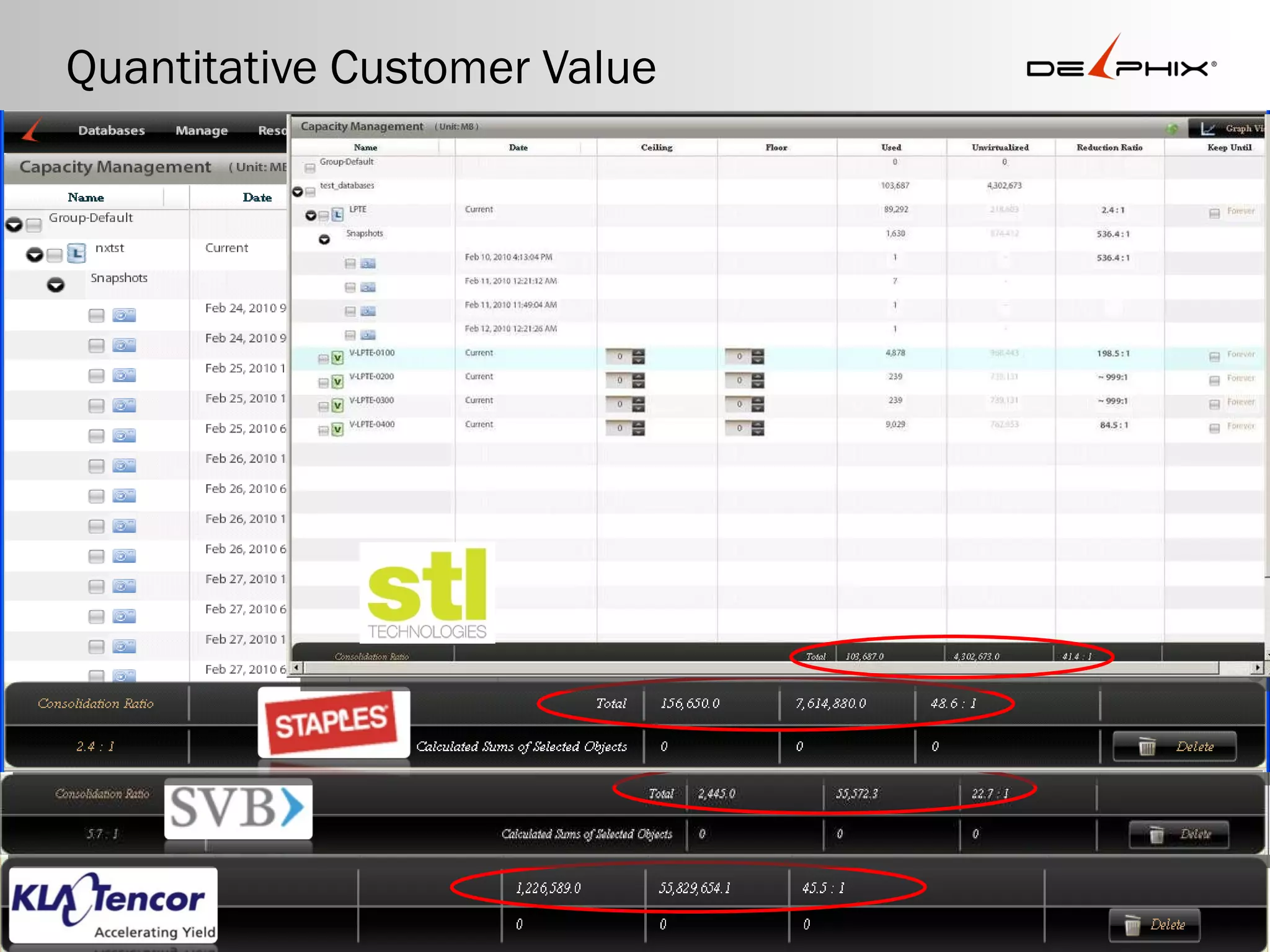
#6 Technology: CrossFlow Engine—turn hardware into software The CrossFlow Engine sits at the heart of the Delphix Server. CrossFlow takes streams from physical databases and turns them into software virtual databases that can sit in a fraction of the space, but with full functionality and performance. CrossFlow dynamically maps file changes and database logs into a TimeFlow—a rolling window of changes recorded for an LDB that is always application consistent. With content aware reduction, Delphix compresses and eliminates unnecessary, empty, and transient data blocks that are not used—shrinking even the first copy of an LDB by up to 75%. Underneath TimeFlow, Delphix leverages highly mature snapshot and cloning technologies to present VDBs to target servers as a set of pointers that map to already existing blocks, eliminating the need to create new, physical copies. Snapshots have been in existence for several years but have lacked the application awareness to fully harness their power for the database ecosystem. Changes to Delphix VDBs are written as new, compressed blocks and maintained transparently by the Delphix Server. Once opened, VDBs are not updated by Delphix—they are only changed by database users and applications. Only the TimeFlow for the LDB continues to be updated, and new VDBs can be instantly provisioned from that TimeFlow, or open VDBs can be refreshed in place. [Primary Confusion] Even VDBs can have their own TimeFlow, and VDBs can be easily provisioned from VDBs, enabling users to promote databases from development to testing. In some environments, data security may be a concern, so users can automatically mask sensitive data, such as Social Security Numbers, through integrated support for pre and post scripting—obfuscating private information before VDBs become accessible by users. Importantly, Delphix automates all of the highly complex, fault prone parameterization required to provision copies of databases, from changing Oracle SIDs to editing cache settings. The end result is a technology engine that is designed to consolidate all the dynamic, lifecycle copies of databases created in enterprise environments, while reducing the time and complexity of provisioning to nearly zero.
#7 Served Addressable Market (SAM): Bottoms Up Assumptions: Database or structured market for storage software only Unstructured vs. structured data in general: 90:10 to 70:30. Most unstructured data not in corporate data centers, etc. Most unstructured data (media, etc.) not on enterprise storage (grid, commodity architectures like GooglePlex). Estimated storage software for file system vs. database data at major hardware manufacturers: 60:40. File servers: 70:30; mid-tier arrays: 50:50, high-end arrays: 25:75, but spending skewed toward higher end arrays: total spend estimated at 50:50 Storage management, storage device management, storage infrastructure, file system, and other non addressable markets total: 20% of storage software revenue. Hence, 80% and then 50% of storage software market: $4.373 billion, growing at 10.4% annually 75% of respondents in Forrester survey say critical databases growing 10 to 49% annually. Trend of moving unstructured data into structured databases for better manageability (e.g. MS SharePoint) Market Size for Delphix Server 1.0 TAM Oriented for mid-market and departmental or test/development enterprise sales Same TAM as Overall Market Size SAM $1 billion, growing >10% annually ($1.63 billion with Microsoft) Oracle only for 1.0: 38% DBMS Market Shares Oracle: 38% IBM: 32% Microsoft: 24% Sybase: 2% Others: 5% Market Shares by Size of Database Under 2 TB databases: 60% More than 5 TB: 21% 2 TB to 5 TB: 19% 1 TB to <2 TB: 7% 500 GB to <1 TB: 24% 100 GB to 499 GB: 17% <100 GB: 12% Overall SAM: $4.373 billion, growing at 10.4% annually $4.373 billion time 38% (Oracle only) times 60% (under 2TB): $1 billion With Microsoft: $1.627 billion
#8 Return on investment (ROI): business enablement, OpEx, and CapEx By combining consolidation and data reduction technologies, Delphix cuts capital expenditures by over 50% and can even pay for itself instantly if new database storage needs to be procured in the same quarter. Many IT organizations have been forced to do more with less; the ability to slash complexity and time for provisioning by over 90% allows IT personnel to focus on higher priorities and projects with higher returns. Finally, by reducing the time and cost of provisioning database sandboxes to nearly zero, Delphix enables IT to better service business needs. Today, many business ideas—like an end-of-quarter adjustment to a CRM application to drive sales efficiency—never become reality due to the hurdles posed by physical infrastructure. Software infrastructure like VMware and Delphix, however, facilitate innovation, allowing businesses to capture potentially lost opportunity value. With Delphix, enterprises can spend less and move faster than the competition.
#12 Summary Database virtualization is the next logical step in the evolution of the datacenter. In many environments, it may be the single largest opportunity for operational and capital cost savings available. By designing a solution that targets non-production infrastructure, a Delphix investment can provide high returns with very low risk. With Delphix, enterprises can move faster and spend less than the competition. Delphix can be deployed in less than an hour—less time than it takes to provision a single physical database—so schedule a free trial with sales today. Contact us by email at [email_address] .
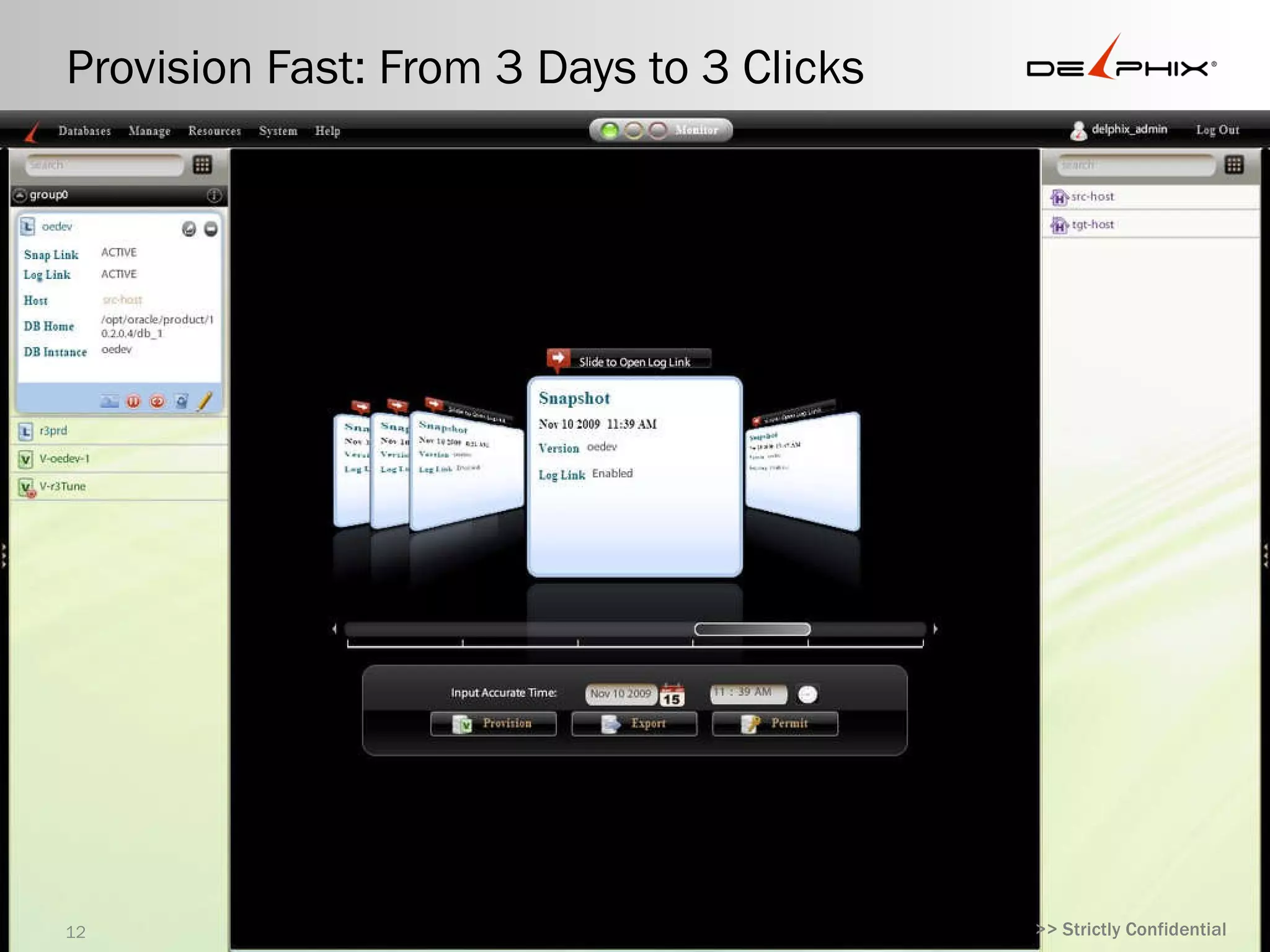
#13 Usability and simplicity: 3 clicks to provisioning Most enterprise software products build their user interfaces last, so they reflect the mechanics of the technology. At Delphix, we believe in building interfaces around users, providing intuitive usability and enabling end-user self service. Usability isn’t just about elegant interfaces—it reduces the long term operational cost and complexity of a product, increasing customer value over time. After selecting an LDB in Delphix, it takes only three clicks to provision a VDB with no additional hardware required—a dramatic improvement over the days and weeks often required with physical infrastructure.




























































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)


















