
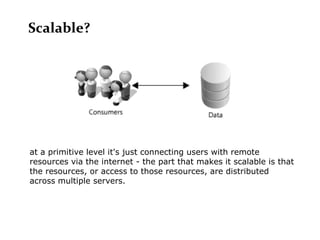
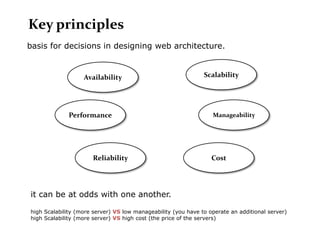
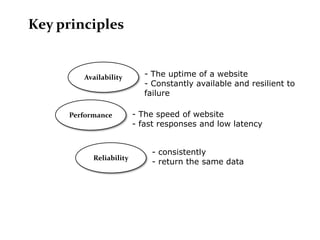
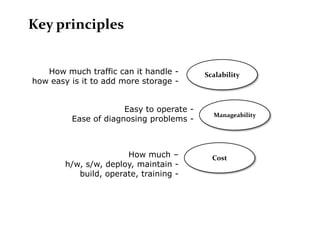

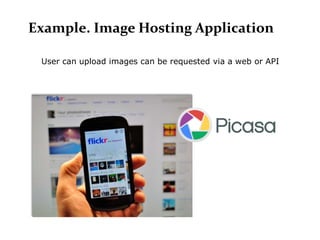
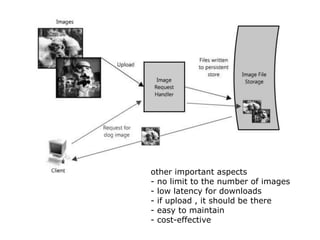
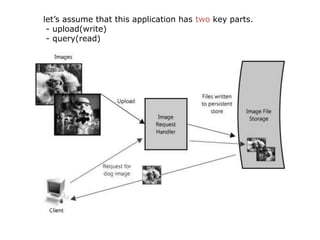
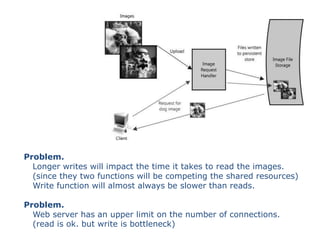
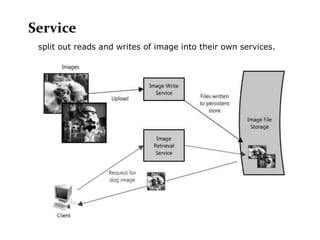


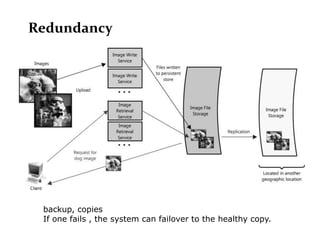

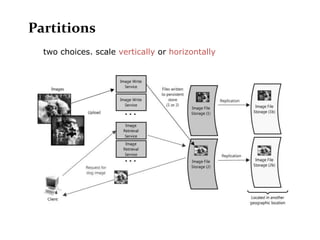


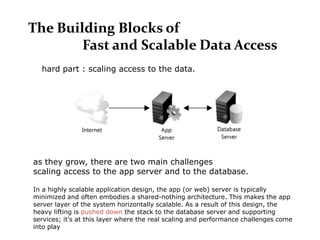
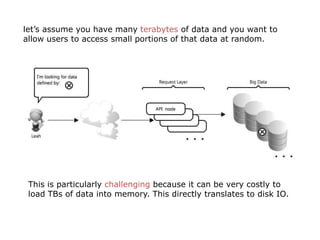


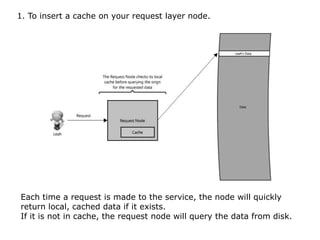
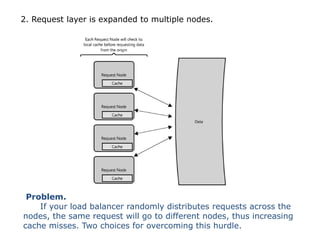
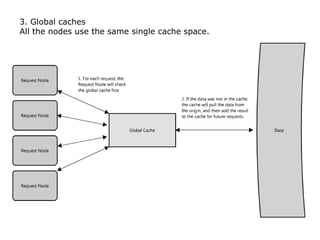

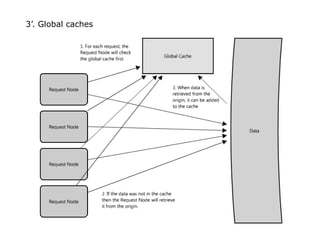

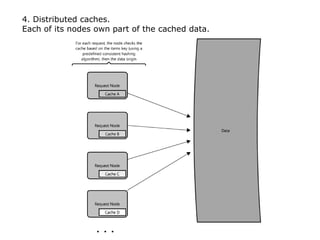


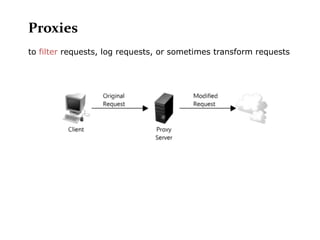
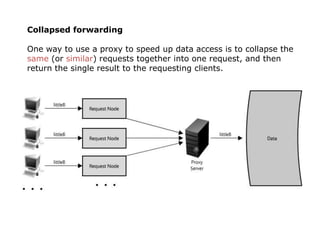

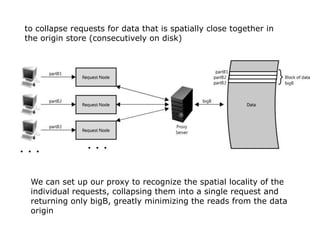

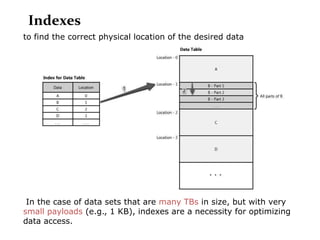
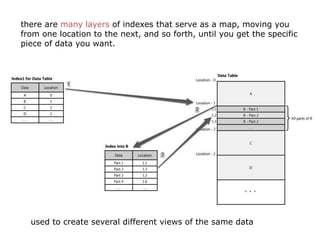
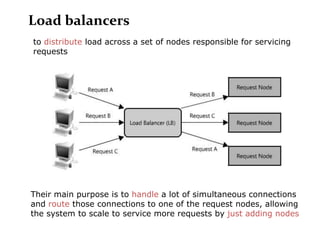

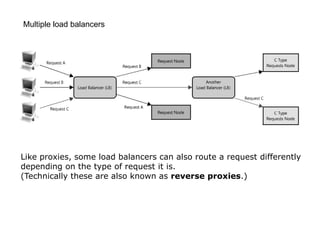

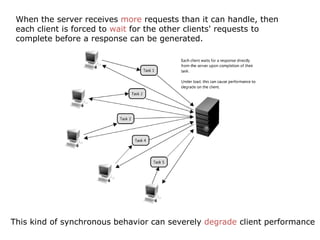
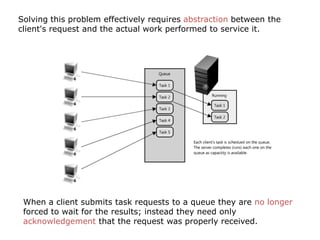





Scalable web architectures distribute resources across multiple servers to improve availability, performance, reliability, and scalability. Key principles for designing scalable systems include availability, performance, reliability, scalability, manageability, and cost. These principles sometimes conflict and require tradeoffs. To improve scalability, services can be split and data distributed across partitions or shards. Caches, proxies, indexes, load balancers, and queues help optimize data access and manage asynchronous operations in distributed systems.


![[웨비나] Follow me! 클라우드 인프라 구축 기본편 - 강지나 테크 에반젤리스트](https://cdn.slidesharecdn.com/ss_thumbnails/follow-mecloudinfra-210723044820-thumbnail.jpg?width=640&height=640&fit=bounds)








![[236] 카카오의데이터파이프라인 윤도영](https://cdn.slidesharecdn.com/ss_thumbnails/236-161025031702-thumbnail.jpg?width=640&height=640&fit=bounds)



















































![[페차쿠차] 배움의 기술](https://cdn.slidesharecdn.com/ss_thumbnails/artoflearningupload-100901083140-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)























