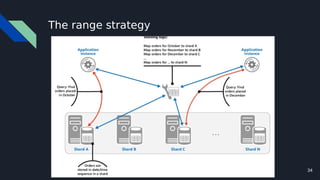
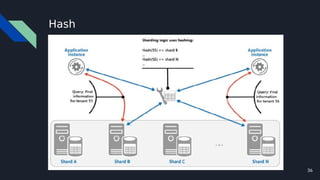
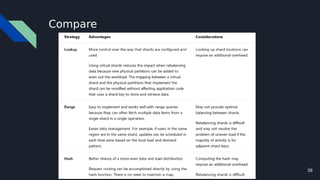
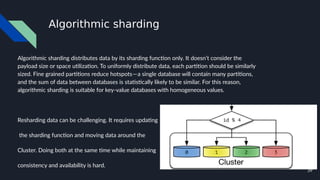
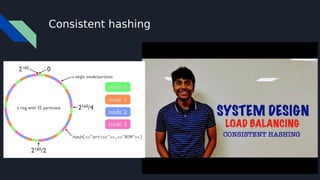
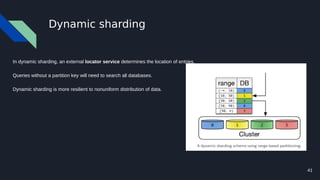
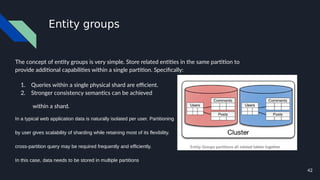
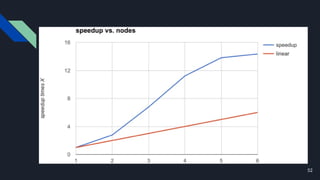
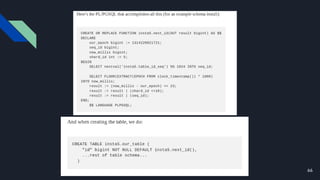
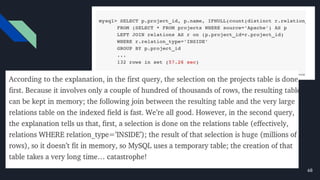
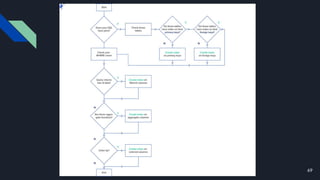
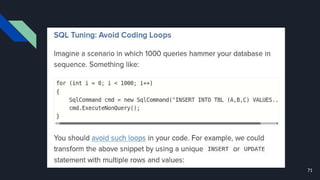
The document discusses various techniques for scaling databases and applications, including caching, replication, functional partitioning, sharding, batching, buffering, queuing, and background processing. It provides examples of when and how to implement these techniques, as well as considerations around caching policies, data distribution strategies, and managing asynchronous replication. The goal is to optimize performance and scalability through techniques that reduce round trips, parallelize operations, and distribute load across servers and databases.