Downloaded 448 times














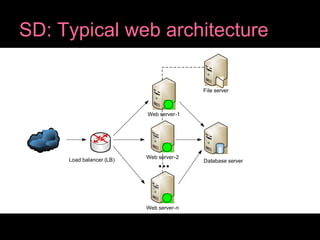



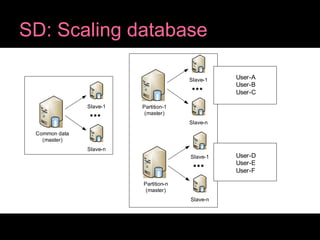







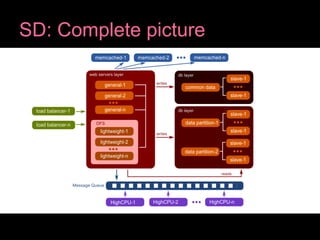









The document discusses scalable web architecture using the LAMP stack and AWS infrastructure, highlighting its flexibility, cost-effectiveness, and widespread adoption by major websites. Key concepts of system design such as scalability, high availability, fault tolerance, and load balancing are explained, along with database scaling strategies like sharding and caching. It also emphasizes the advantages of using AWS services like EC2, S3, and CloudFront for efficient cloud infrastructure management.














































