Download as PDF, PPTX

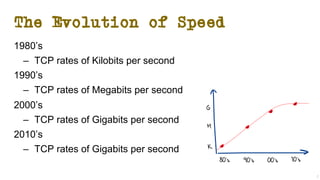
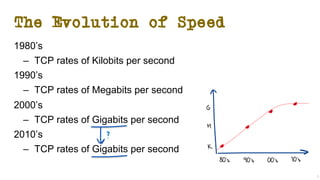
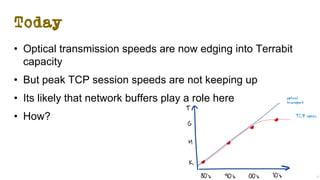



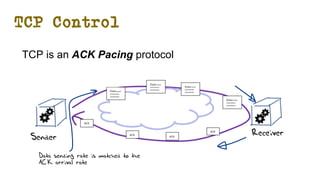



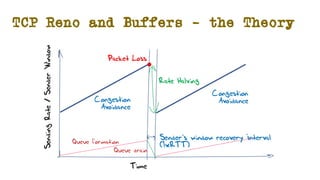



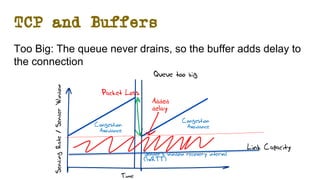


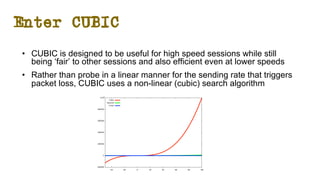
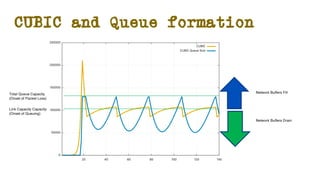


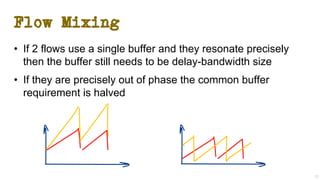






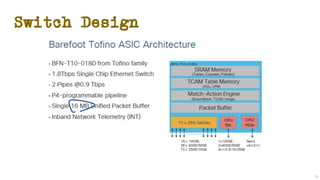

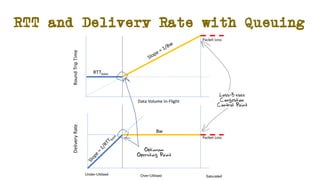



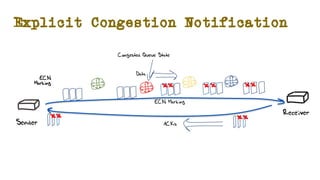


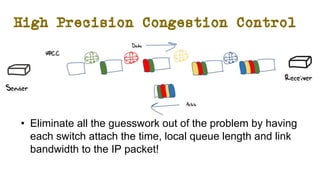



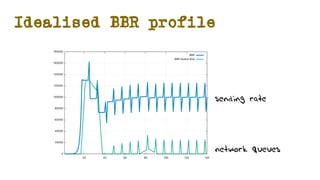






The document discusses the evolution of Transmission Control Protocol (TCP) speeds and the impact of network buffers on these speeds, highlighting the historical progression from kilobits to terabits while detailing TCP's flow control mechanisms. It explains various TCP algorithms, such as Reno and Cubic, and their adaptations to manage buffer sizes and improve network efficiency. The document emphasizes current challenges in networking and stresses the need for further research to address unsolved issues and enhance high-speed data transmission.









































































