Downloaded 14 times



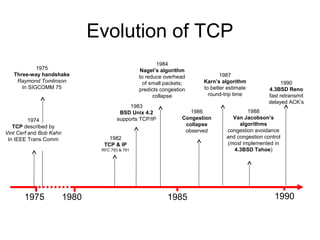
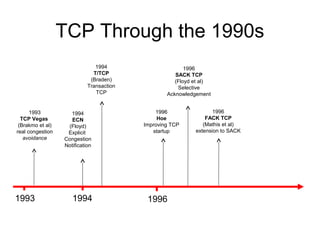





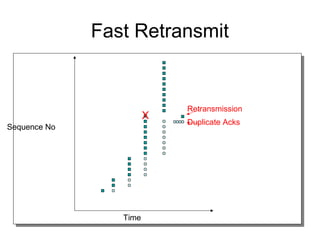
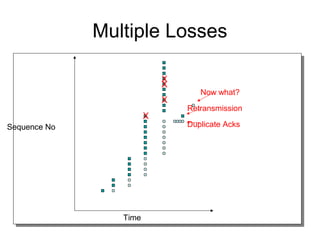
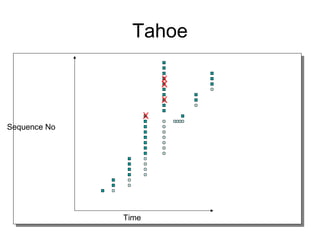

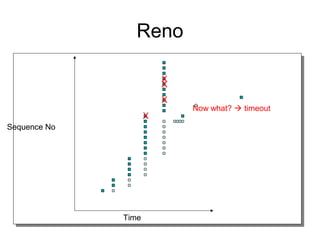

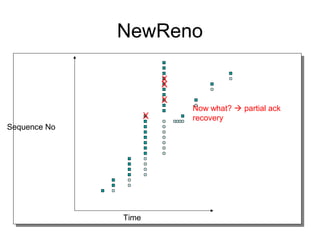








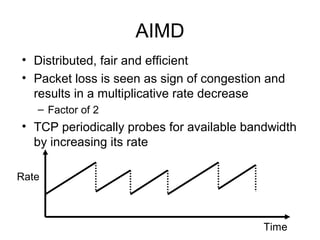


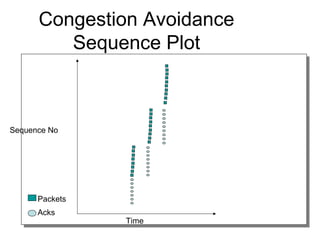
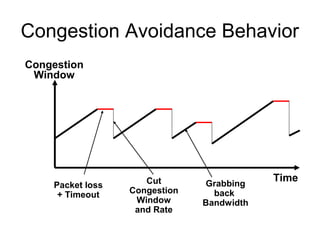

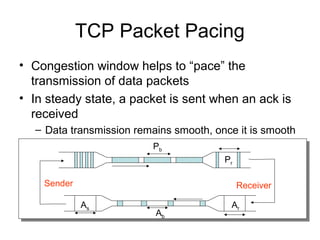

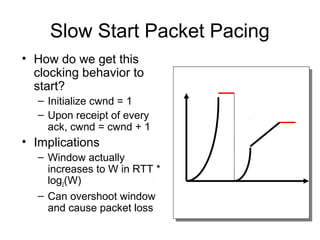
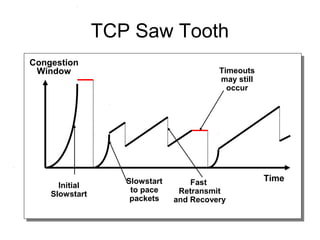

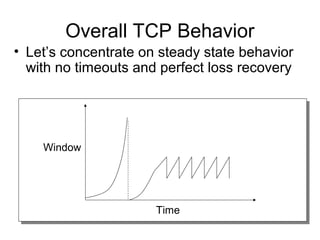









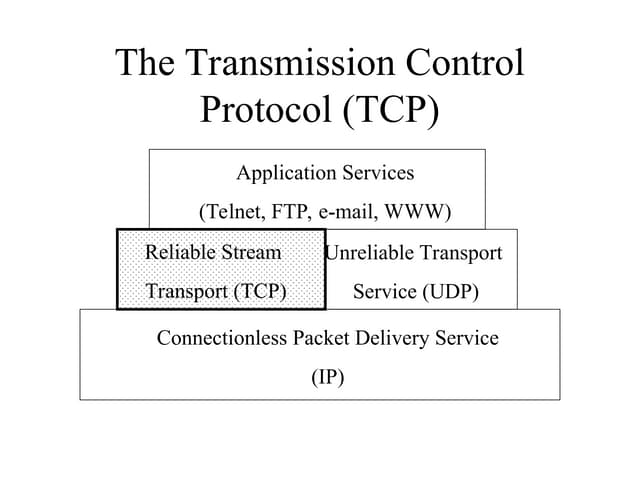
- TCP uses congestion control and avoidance to prevent network congestion collapse. It operates in a distributed manner without centralized control. - TCP's congestion control is based on additive increase, multiplicative decrease (AIMD) and uses a congestion window and packet pacing to smoothly increase and decrease transmission rates in response to packet loss as a signal of congestion. - The key mechanisms are slow start for initial rapid ramp up, congestion avoidance for gradual increase, fast retransmit for quick recovery from single losses, and timeout for recovery from multiple losses or ack losses. These mechanisms work together to keep TCP stable and efficient under different network conditions.