

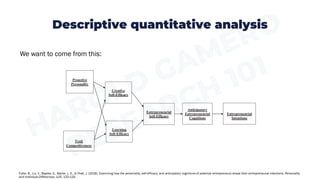








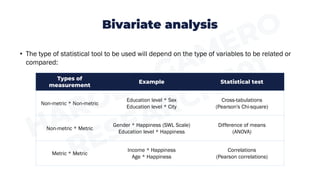

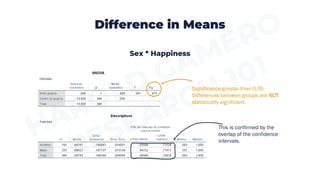




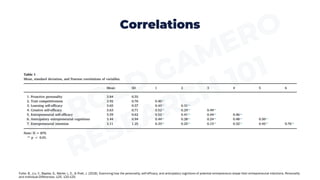


This document provides an overview of descriptive statistics and quantitative analysis. Descriptive statistics are used to describe and summarize data, and include frequency distributions, measures of central tendency (mean, median, mode), and measures of dispersion (range, standard deviation, variance). Univariate analysis examines one variable at a time using these descriptive statistics. Bivariate analysis examines the relationship between two variables using statistical tests like cross-tabulations, difference of means tests, and correlations depending on the type of variables. Specialized software is required to perform these analyses to gain insights from data in research studies.



































































