Download as PDF, PPTX




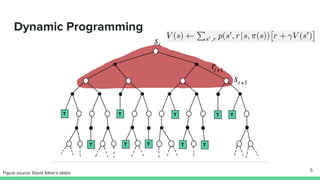





















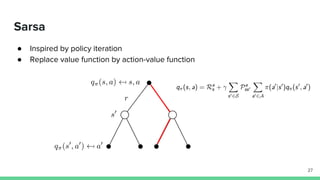































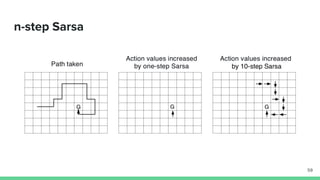
































The document provides an overview of temporal-difference (TD) learning in reinforcement learning, detailing its differences from Monte Carlo methods and highlighting key concepts like SARSA and Q-learning. It explains various TD methods including one-step TD, n-step bootstrapping, and eligibility traces, and discusses their advantages and applications. Additionally, it contrasts on-policy and off-policy methods, emphasizing the use of function approximators to address challenges in high-dimensional environments.



































































