Downloaded 32 times





![Why do we need regular expressions
(in programming)
Many reasons but most of them are in their base
finding strings in text .
Preferably without reading it
^(?("")(""[^""]+?""@)|(([0-9a-z]((.(?!.))|[-
!#$%&'*+/=?^`{}|~w])*)(?<=[0-9a-
z])@))(?([)([(d{1,3}.){3}d{1,3}])|(([0-9a-z][-
w]*[0-9a-z]*.)+[a-z0-9]{2,17}))$
^(?=.*[^a-zA-Z])(?=.*[a-z])(?=.*[A-Z])S{8,}$](https://image.slidesharecdn.com/regularexpressions-130111001242-phpapp02/85/Regular-expressions-5-320.jpg)
![Regular Expressions Syntax
meta characters
Grouping
. – match any other character
[ ] – grouping, match single character that is inside the group
[^ ] – grouping, match single character that is not inside the group
( ) – sub expression, in Perl can be recalled later from special variables
Quantifier
{m,n} –specifies that the character/sub expression before need to be matched
at least m times and no more than n times
* - derived from Kleene star in formal logic, matches 0 or more amount of the
character before it.
? –matches zero or one of the preceding elements
+ - derived from Kleene cross in formal logic, matches 1 or more of the
character before it.
Location
^ - Marking start of line
$ - Marking end of line](https://image.slidesharecdn.com/regularexpressions-130111001242-phpapp02/85/Regular-expressions-6-320.jpg)
![Regular Expressions Syntax
Character groups
[:alpha:] - Any alphabetical character - [A-Za-z]
[:alnum:] - Any alphanumeric character - [A-Za-z0-9]
[:ascii:] - Any character in the ASCII character set.[:blank:] - A GNU
extension, equal to a space or a horizontal tab ("t")
[:cntrl:] - Any control character
[:digit:] - Any decimal digit - [0-9], equivalent to "d“
[:graph:] - Any printable character, excluding a space
[:lower:] - Any lowercase character - [a-z]
[:print:] - Any printable character, including a space
[:punct:] - Any graphical character excluding "word" characters
[:space:] - Any whitespace character. "s" plus the vertical tab ("cK")
[:upper:] - Any uppercase character - [A-Z]
[:word:] - A Perl extension - [A-Za-z0-9_], equivalent to "w“
[:xdigit:] - Any hexadecimal digit - [0-9a-fA-F].](https://image.slidesharecdn.com/regularexpressions-130111001242-phpapp02/85/Regular-expressions-7-320.jpg)








![Some examples of Regex
• ([^s]+(.(?i)(jpg|png|gif|bmp))$)
– Match file with specific extentions
• ^(https?://)?([da-z.-]+).([a-z.]{2,6})([/w
.-]*)*/?$
– Match URL
• /^#?([a-f0-9]{6}|[a-f0-9]{3})$/
– Match a hex value
• [ -~]
– An interesting one.](https://image.slidesharecdn.com/regularexpressions-130111001242-phpapp02/85/Regular-expressions-21-320.jpg)

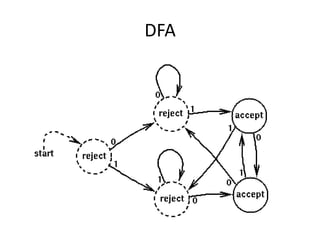
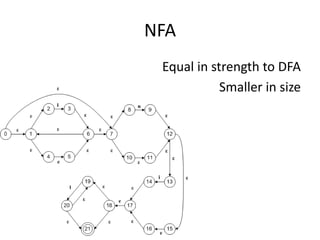
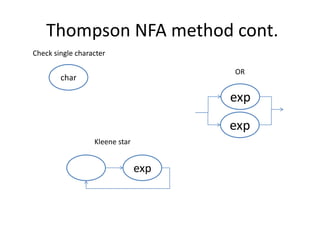
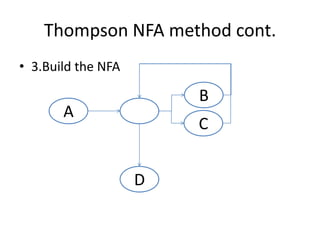
Regular expressions provide a concise way to match patterns in text. They work by converting the regex into a state machine that can efficiently search a string to find matches. Important regex syntax includes quantifiers like *, +, ?, character classes like [a-z], and anchors like ^ and $. Regular expression engines turn the regex pattern into a program that can search strings. Thompson's NFA construction algorithm is commonly used to build the state machine from a regex for efficient matching.






































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)













