Downloaded 10 times


![Recap
if condition:
statements
[elif condition:
statements] ...
else:
statements
while condition:
statements
for var in sequence:
statements
break
continue
Strings](https://image.slidesharecdn.com/p32017pythonregexes-171016214505/75/P3-2017-python_regexes-4-2048.jpg)
![Lists
• Flexible arrays, not Lisp-like linked
lists
• a = [99, "bottles of beer", ["on", "the",
"wall"]]
• Same operators as for strings
• a+b, a*3, a[0], a[-1], a[1:], len(a)
• Item and slice assignment
• a[0] = 98
• a[1:2] = ["bottles", "of", "beer"]
-> [98, "bottles", "of", "beer", ["on", "the", "wall"]]
• del a[-1] # -> [98, "bottles", "of", "beer"]](https://image.slidesharecdn.com/p32017pythonregexes-171016214505/75/P3-2017-python_regexes-5-2048.jpg)
![Dictionaries
• Hash tables, "associative arrays"
• d = {"duck": "eend", "water": "water"}
• Lookup:
• d["duck"] -> "eend"
• d["back"] # raises KeyError exception
• Delete, insert, overwrite:
• del d["water"] # {"duck": "eend", "back": "rug"}
• d["back"] = "rug" # {"duck": "eend", "back":
"rug"}
• d["duck"] = "duik" # {"duck": "duik", "back":
"rug"}](https://image.slidesharecdn.com/p32017pythonregexes-171016214505/75/P3-2017-python_regexes-6-2048.jpg)
![if condition:
statements
[elif condition:
statements] ...
else:
statements
while condition:
statements
for var in sequence:
statements
break
continue
Strings
REGULAR EXPRESSIONS](https://image.slidesharecdn.com/p32017pythonregexes-171016214505/75/P3-2017-python_regexes-8-2048.jpg)


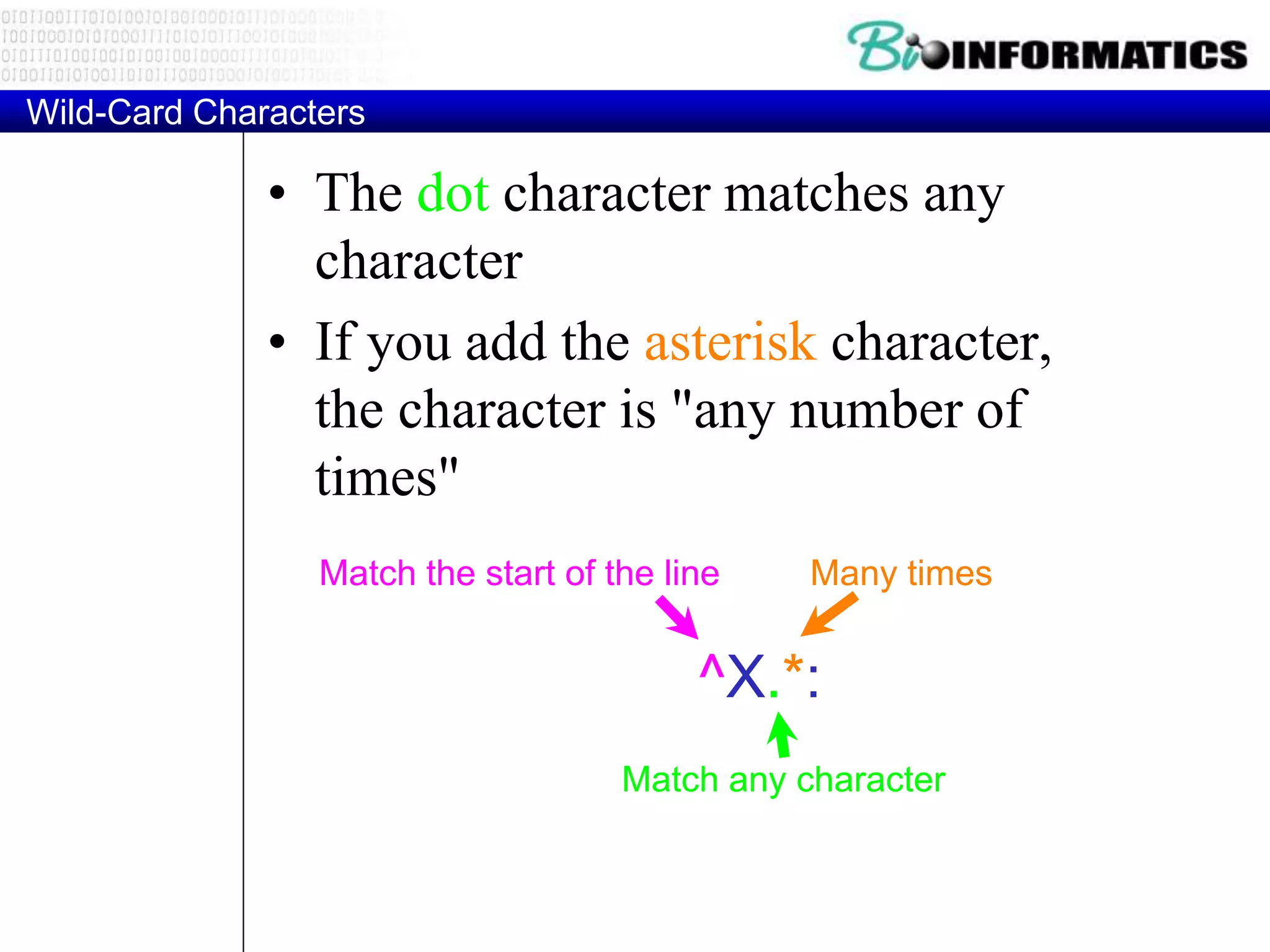
![Regular Expression Quick Guide
^ Matches the beginning of a line
$ Matches the end of the line
. Matches any character
s Matches whitespace
S Matches any non-whitespace character
* Repeats a character zero or more times
*? Repeats a character zero or more times (non-greedy)
+ Repeats a chracter one or more times
+? Repeats a character one or more times (non-greedy)
[aeiou] Matches a single character in the listed set
[^XYZ] Matches a single character not in the listed set
[a-z0-9] The set of characters can include a range
( Indicates where string extraction is to start
) Indicates where string extraction is to end](https://image.slidesharecdn.com/p32017pythonregexes-171016214505/75/P3-2017-python_regexes-11-2048.jpg)
![The Regular Expression Module
• Before you can use regular expressions in
your program, you must import the library
using "import re"
• You can use re.search() to see if a string
matches a regular expression similar to
using the find() method for strings
• You can use re.findall() extract portions of
a string that match your regular expression
similar to a combination of find() and
slicing: var[5:10]](https://image.slidesharecdn.com/p32017pythonregexes-171016214505/75/P3-2017-python_regexes-12-2048.jpg)
![Matching and Extracting Data
• The re.search() returns a True/False
depending on whether the string matches
the regular expression
• If we actually want the matching strings
to be extracted, we use re.findall()
>>> import re
>>> x = 'My 2 favorite numbers are 19 and 42'
>>> y = re.findall('[0-9]+',x)
>>> print y
['2', '19', '42']](https://image.slidesharecdn.com/p32017pythonregexes-171016214505/75/P3-2017-python_regexes-14-2048.jpg)
![Warning: Greedy Matching
• The repeat characters (* and +) push outward in both directions
(greedy) to match the largest possible string
>>> import re
>>> x = 'From: Using the : character'
>>> y = re.findall('^F.+:', x)
>>> print y
['From: Using the :']
^F.+:
One or more
characters
First character in the
match is an F
Last character in the
match is a :](https://image.slidesharecdn.com/p32017pythonregexes-171016214505/75/P3-2017-python_regexes-15-2048.jpg)
![Non-Greedy Matching
• Not all regular expression repeat codes are
greedy! If you add a ? character - the + and *
chill out a bit...
>>> import re
>>> x = 'From: Using the : character'
>>> y = re.findall('^F.+?:', x)
>>> print y
['From:']
^F.+?:
One or more
characters but
not greedily
First character in the
match is an F
Last character in the
match is a :](https://image.slidesharecdn.com/p32017pythonregexes-171016214505/75/P3-2017-python_regexes-16-2048.jpg)
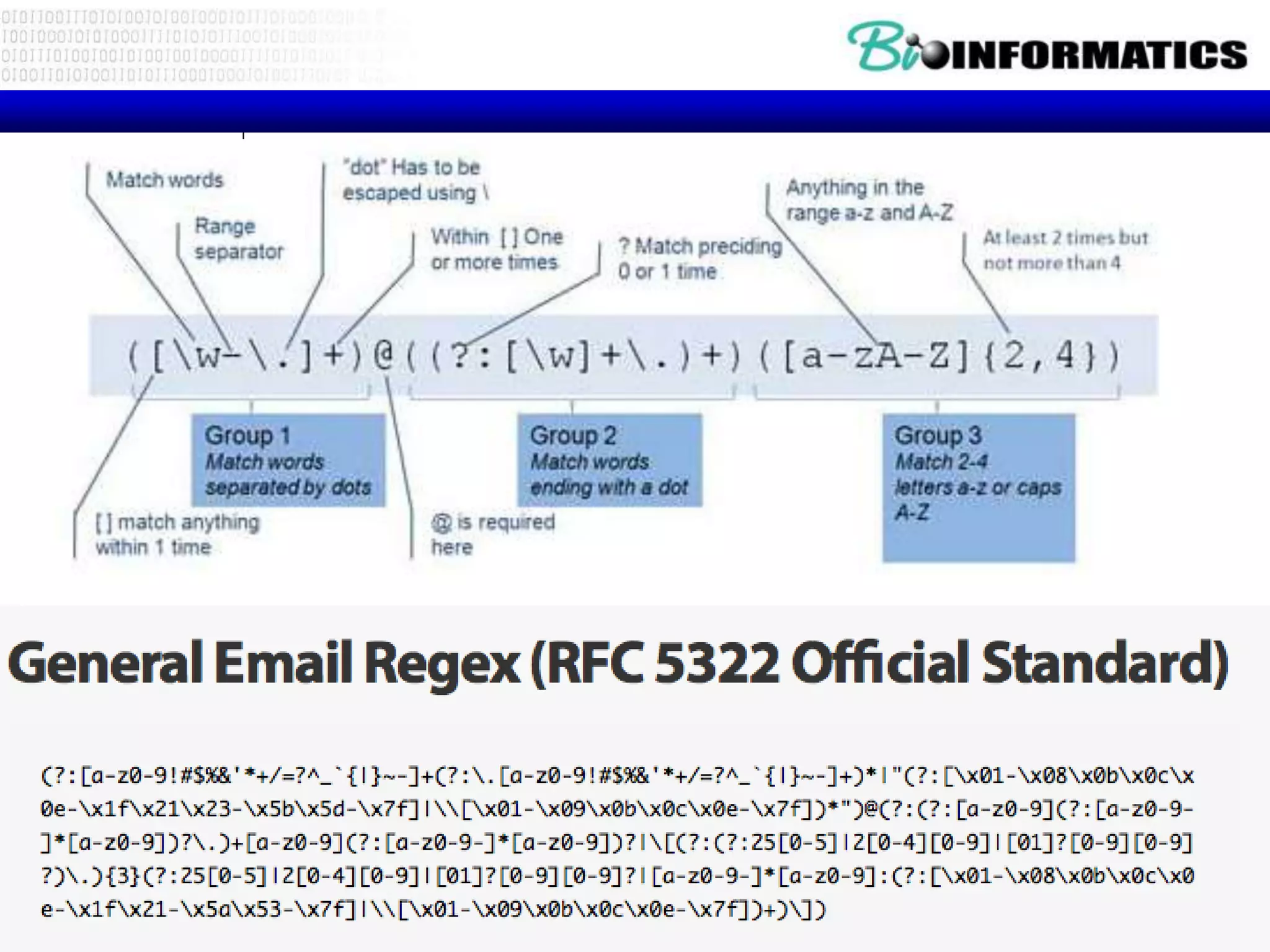
![Fine Tuning String Extraction
• Parenthesis are not part of the match -
but they tell where to start and stop what
string to extract
From stephen.marquard@uct.ac.za Sat Jan 5 09:14:16
2008
>>> y = re.findall('S+@S+',x)
>>> print y
['stephen.marquard@uct.ac.za']
>>> y = re.findall('^From (S+@S+)',x)
>>> print y
['stephen.marquard@uct.ac.za']
^From (S+@S+)](https://image.slidesharecdn.com/p32017pythonregexes-171016214505/75/P3-2017-python_regexes-17-2048.jpg)
![The Double Split Version
• Sometimes we split a line one way and then grab
one of the pieces of the line and split that piece
again
From stephen.marquard@uct.ac.za Sat Jan 5 09:14:16
2008
words = line.split()
email = words[1]
pieces = email.split('@')
print pieces[1]
stephen.marquard@uct.ac.za
['stephen.marquard', 'uct.ac.za']
'uct.ac.za'](https://image.slidesharecdn.com/p32017pythonregexes-171016214505/75/P3-2017-python_regexes-18-2048.jpg)
![The Regex Version
From stephen.marquard@uct.ac.za Sat Jan 5 09:14:16
2008
import re
lin = 'From stephen.marquard@uct.ac.za Sat Jan 5 09:14:1
y = re.findall('@([^ ]*)',lin)
print y['uct.ac.za']
'@([^ ]*)'
Look through the string until you find an at-sign
Match non-blank character
Match many of them](https://image.slidesharecdn.com/p32017pythonregexes-171016214505/75/P3-2017-python_regexes-19-2048.jpg)
![Escape Character
• If you want a special regular expression
character to just behave normally (most
of the time) you prefix it with ''
>>> import re
>>> x = 'We just received $10.00 for cookies.'
>>> y = re.findall('$[0-9.]+',x)
>>> print y
['$10.00']
$[0-9.]+
A digit or periodA real dollar sign
At least one
or more](https://image.slidesharecdn.com/p32017pythonregexes-171016214505/75/P3-2017-python_regexes-20-2048.jpg)

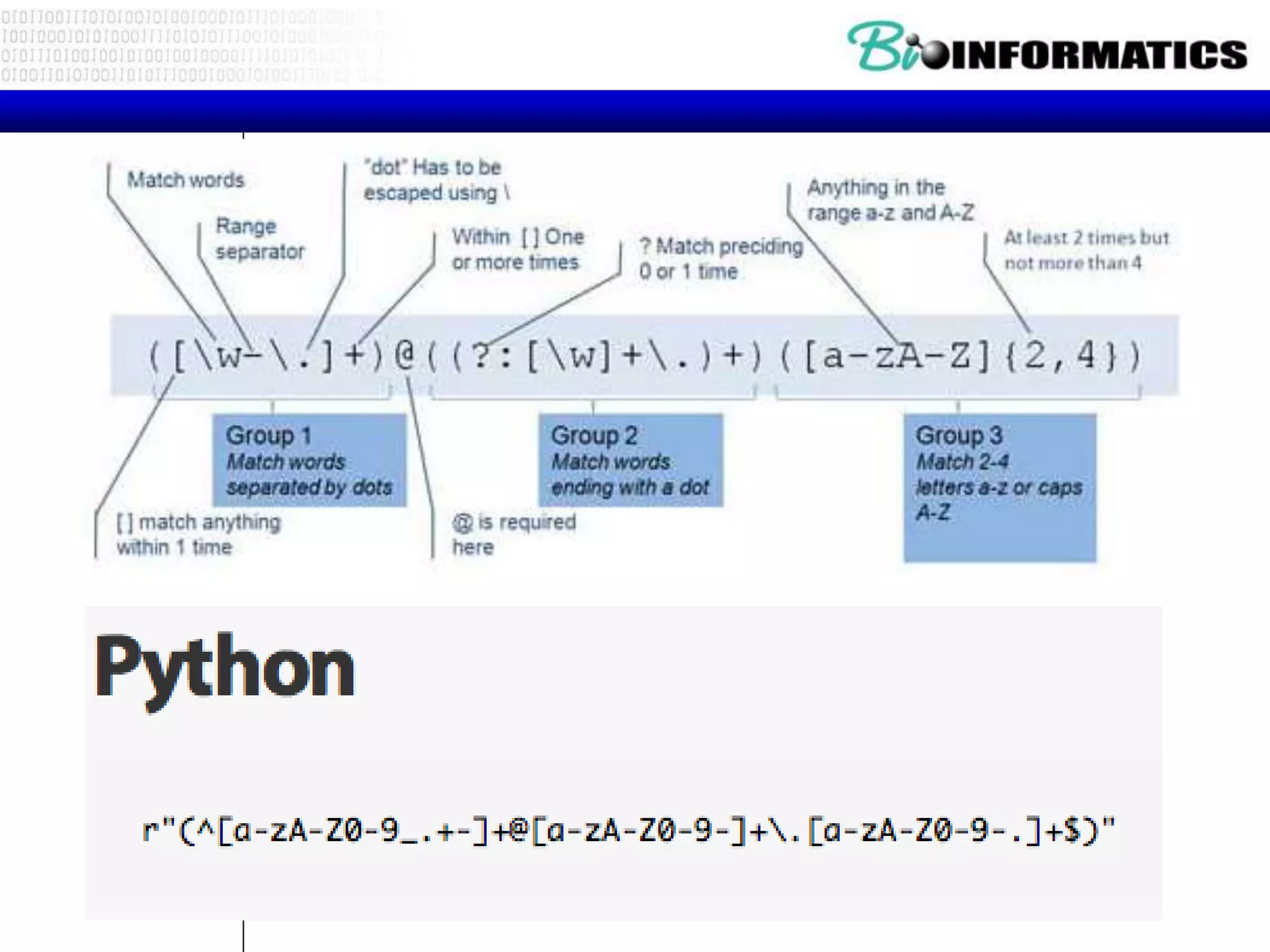




![Examples 4
regex = r"([a-zA-Z]+) d+"
#finditer() returns an iterator that produces Match instances instead of the strings
returned by findall()
matches = re.finditer(regex, "June 24, August 9, Dec 12")
for match in matches:
print(match)
print ("Match at index:",match.group(0),match.group(1),match.start(), match.end())](https://image.slidesharecdn.com/p32017pythonregexes-171016214505/75/P3-2017-python_regexes-28-2048.jpg)
![Examples 5
text = 'abbaaabbbbaaaaa'
pattern = 'ab'
for match in re.finditer(pattern, text):
s = match.start()
e = match.end()
print ('Found "%s" at %d:%d' % (text[s:e], s, e))](https://image.slidesharecdn.com/p32017pythonregexes-171016214505/75/P3-2017-python_regexes-29-2048.jpg)



The document discusses regular expressions (regex) in Python. It provides examples of using regex to search for patterns in strings, extract matches, and find and group substrings. Key concepts covered include regex syntax like anchors, character classes, repetition, capturing groups, greedy/non-greedy matching, and the re module's functions like search, findall, finditer, and sub. Real-world applications mentioned include validating formats like IP addresses and parsing structured data.


























































![Bio ontologies and semantic technologies[2]](https://cdn.slidesharecdn.com/ss_thumbnails/bioontologiesandsemantictechnologies2-180509123734-thumbnail.jpg?width=640&height=640&fit=bounds)



























