Downloaded 104 times



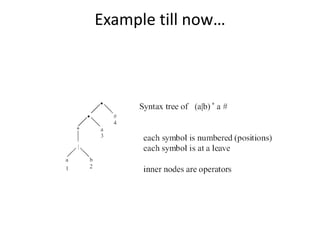





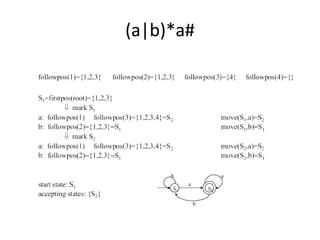

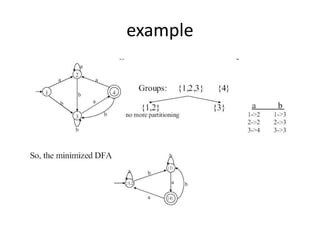



The document discusses three methods to optimize DFAs: 1) directly building a DFA from a regular expression, 2) minimizing states, and 3) compacting transition tables. It provides details on constructing a direct DFA from a regular expression by building a syntax tree and calculating first, last, and follow positions. It also describes minimizing states by partitioning states into accepting and non-accepting groups and compacting transition tables by representing them as lists of character-state pairs with a default state.



![Depth first search [dfs]](https://cdn.slidesharecdn.com/ss_thumbnails/depthfirstsearchdfs-190926145304-thumbnail.jpg?width=640&height=640&fit=bounds)