Download to read offline














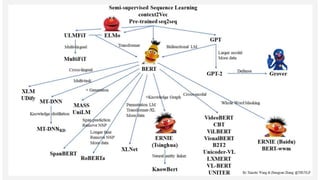
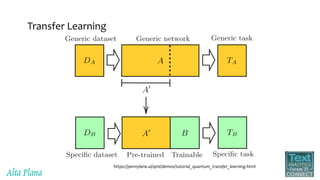

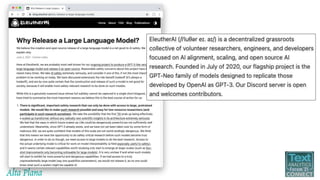
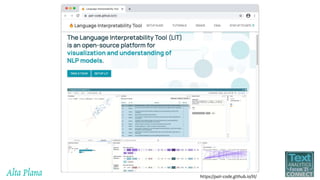

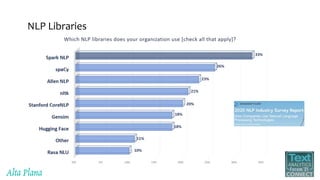

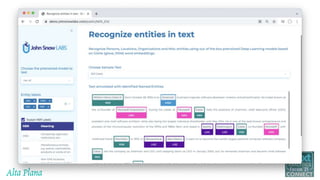
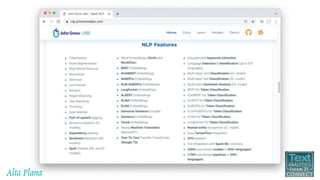
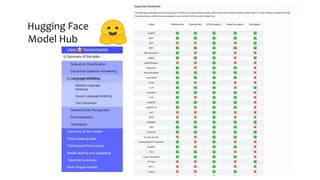

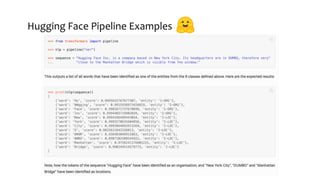
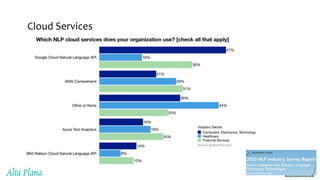

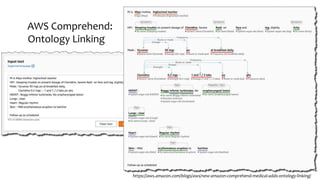

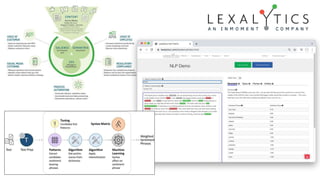
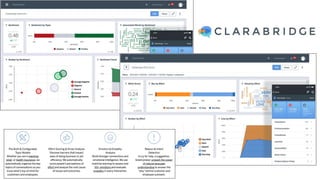


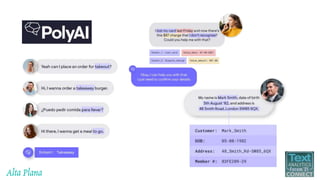
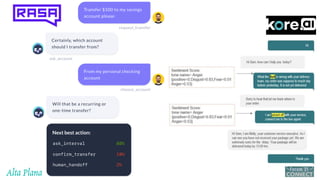
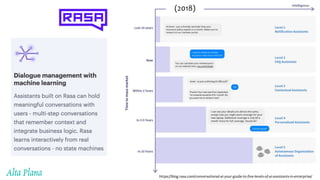
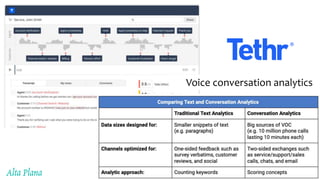



This document discusses recent advances in natural language processing (NLP), focusing on natural language understanding (NLU) and natural language generation (NLG). It highlights various techniques such as word embeddings, including word2vec and BERT, and applications like machine translation, summarization, and conversational interfaces. Additionally, it references NLP libraries and cloud services, emphasizing their role in extracting meaningful information from data.











































































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)











