Download as PDF, PPTX





















![Name Finder API - Detect Names
NameFinderME nameFinder = new NameFinderME(new
TokenNameFinderModel(
OpenNLPMain.class.getResource("/opennlp-models/por-ner.bin”)));
for (String document[][] : documents) {
for (String[] sentence : document) {
Span nameSpans[] = nameFinder.find(sentence);
// do something with the names
}
nameFinder.clearAdaptiveData()
}](https://image.slidesharecdn.com/hadoopsummitsanjoseopennlp-170619034221/85/Large-Scale-Text-Processing-22-320.jpg)





![Apache Flink - Pos Tagger and NER
DataStream<Tuple2<String, String>> porNewsArticles = langStream.select("por");
DataStream<Tuple2<String, String[]>> porNewsTokenized = porNewsArticles.map(new
PorTokenizerMapFunction());
DataStream<POSSample> porNewsPOS = porNewsTokenized.map(new
PorPOSTaggerMapFunction());
DataStream<NameSample> porNewsNamedEntities = porNewsTokenized.map(new
PorNameFinderMapFunction());](https://image.slidesharecdn.com/hadoopsummitsanjoseopennlp-170619034221/85/Large-Scale-Text-Processing-30-320.jpg)
![Apache Flink - Pos Tagger and NER
private static class LanguageSelector implements OutputSelector<Tuple2<String, String>> {
public Iterable<String> select(Tuple2<String, String> s) {
List<String> list = new ArrayList<>();
list.add(languageDetectorME.predictLanguage(s.f1).getLang());
return list;
}
}
private static class PorTokenizerMapFunction implements MapFunction<Tuple2<String, String>,
Tuple2<String, String[]>> {
public Tuple2<String, String[]> map(Tuple2<String, String> s) {
return new Tuple2<>(s.f0, porTokenizer.tokenize(s.f0));
}
}](https://image.slidesharecdn.com/hadoopsummitsanjoseopennlp-170619034221/85/Large-Scale-Text-Processing-31-320.jpg)
![Apache Flink - Pos Tagger and NER
private static class PorPOSTaggerMapFunction implements MapFunction<Tuple2<String, String[]>,
POSSample> {
public POSSample map(Tuple2<String, String[]> s) {
String[] tags = porPosTagger.tag(s.f1);
return new POSSample(s.f0, s.f1, tags);
}
}
private static class PorNameFinderMapFunction implements MapFunction<Tuple2<String, String[]>,
NameSample> {
public NameSample map(Tuple2<String, String[]> s) {
Span[] names = engNameFinder.find(s.f1);
return new NameSample(s.f0, s.f1, names, null, true);
}
}](https://image.slidesharecdn.com/hadoopsummitsanjoseopennlp-170619034221/85/Large-Scale-Text-Processing-32-320.jpg)





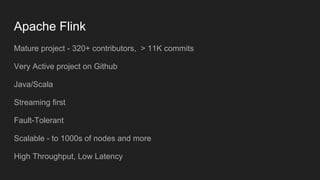
This document summarizes Suneel Marthi's presentation on large scale natural language processing. It discusses how natural language processing deals with processing and analyzing large amounts of human language data using computers. It provides an overview of Apache OpenNLP and Apache Flink, two open source projects for natural language processing. It also discusses how models for tasks like part-of-speech tagging and named entity recognition can be trained for different languages and integrated into data pipelines for large scale processing using these frameworks.










































































