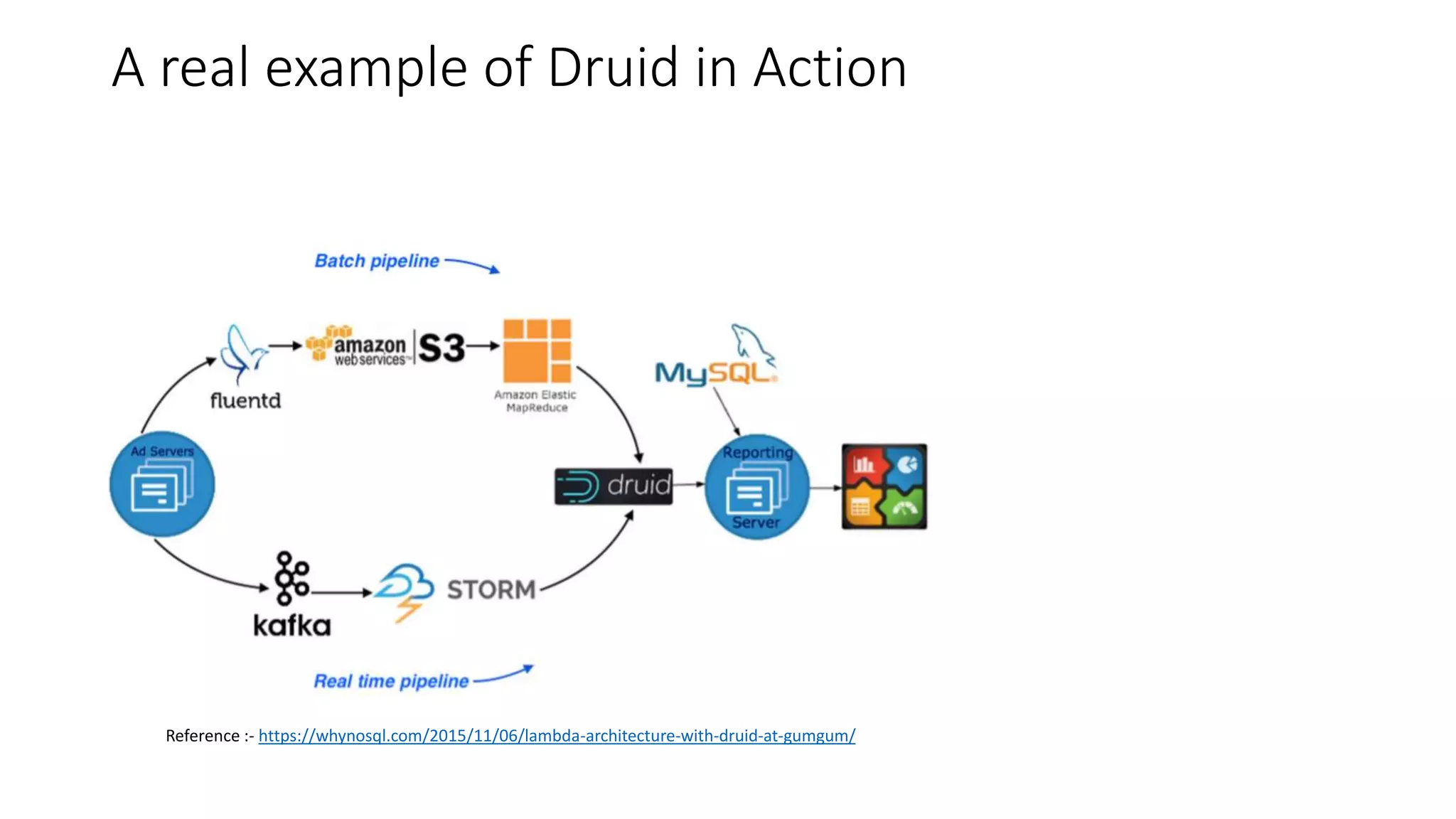
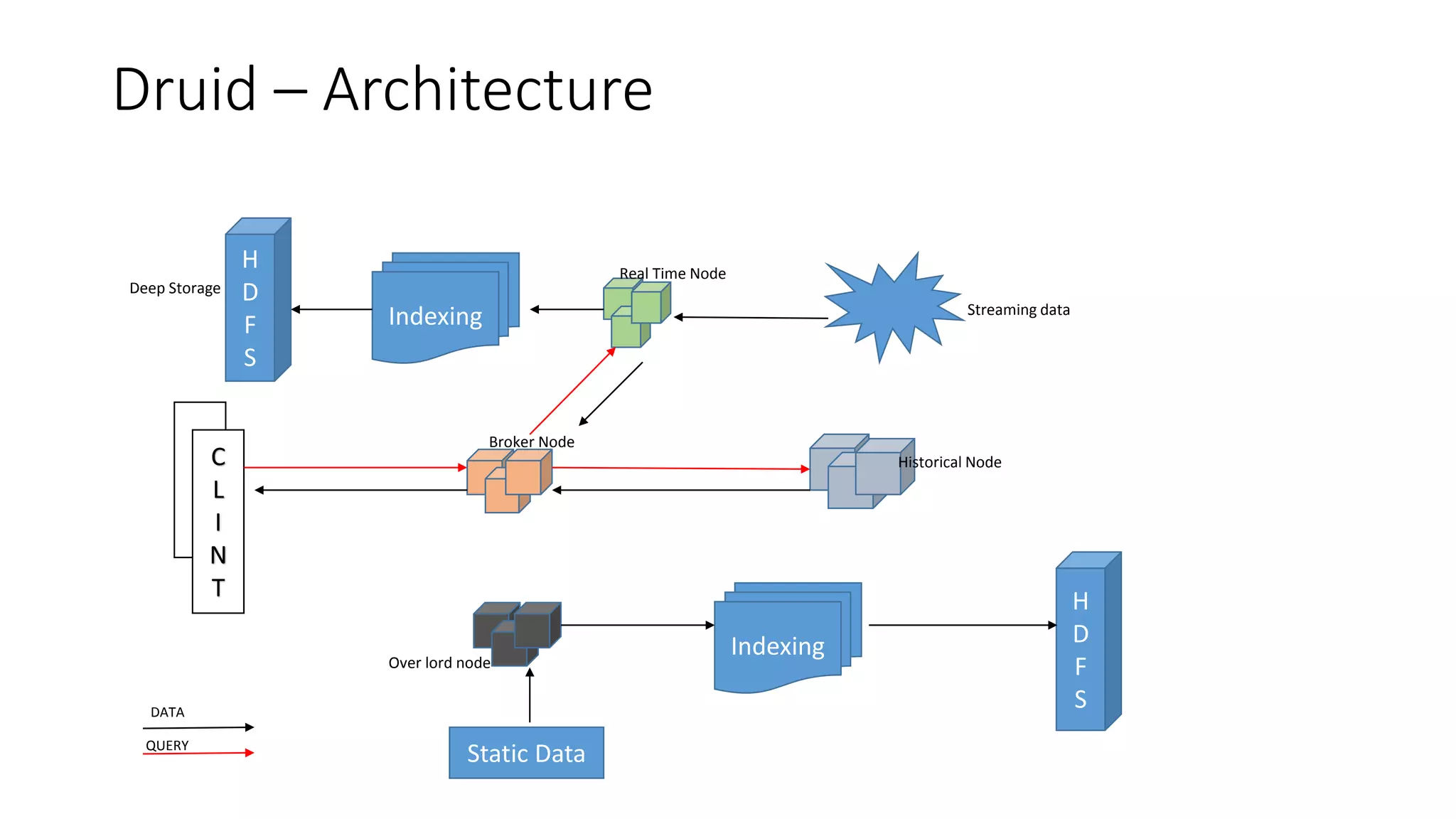
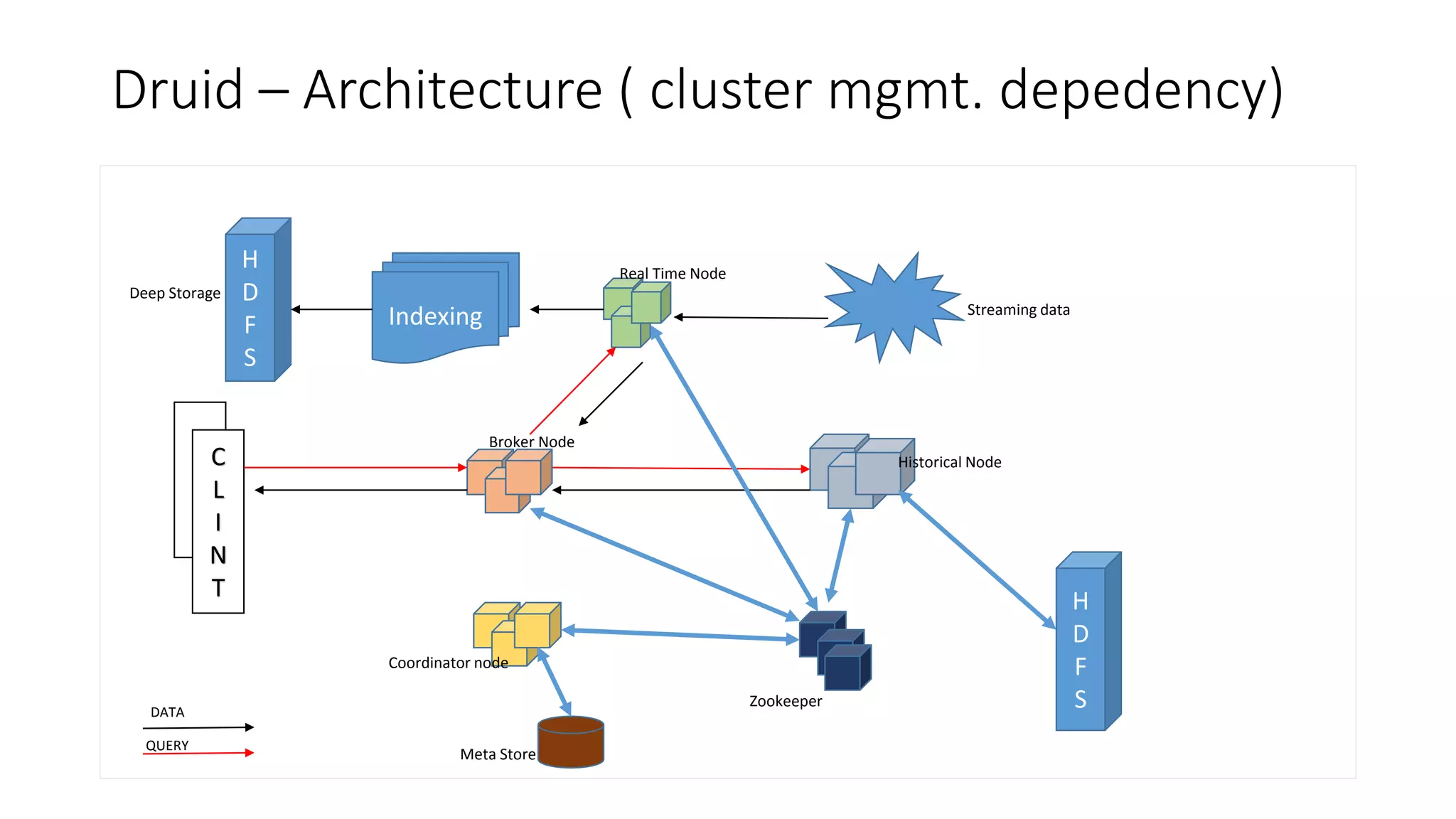
Druid is an open source, fast, distributed column-oriented data store designed for low latency ingestion and fast ad-hoc analytics, with strong support for real-time streaming ingestion. It has gained adoption across industries such as Metamarkets, Airbnb, Alibaba, Cisco, and eBay for applications involving high-volume event processing and complex queries. Key features include sub-second response times for aggregations, scalability to handle petabytes of data, and efficient data storage and query capabilities.













![Query commands
• TopN
• This will result Top N pages with latency in descending order.
• curl -L -H'Content-Type: application/json' -XPOST --data-binary @quckstart/Test/query/pageviewsLatforCount-top-
latency-pages.json http://localhost:8082/druid/v2/?pretty
• Timeseries
• This will result total latency , filtered by user=“alice” and "granularity": "day“ . [ “all” ]
• curl -L -H'Content-Type: application/json' -XPOST --data-binary @ckstart/Test/query/pageviewsLatforCount-timeseries-
pages.json http://localhost:8082/druid/v2/?pretty
• groupBy
• A) This is will result aggregated latency grpBy user+url
• curl -L -H'Content-Type: application/json' -XPOST --data-binary
@quickstart/Test/query/pageviewsLatforCount-aggregateLatencyGrpByURLUser.json
http://localhost:8082/druid/v2/?pretty
• B) This will result aggregated page count (i.e. number of url accessed ) grpBy user
• curl -L -H'Content-Type: application/json' -XPOST --data-binary
@quickstart/Test/query/pageviewsLatforCount-countURLAccessedGrpByUser.json
http://localhost:8082/druid/v2/?pretty](https://image.slidesharecdn.com/understanding-apache-druid-170714112335/75/Understanding-apache-druid-17-2048.jpg)







![Resilience: the key requirement of a [big] [data] architecture - StampedeCon...](https://cdn.slidesharecdn.com/ss_thumbnails/resiliencethekeyrequirementofabigdataarchitecture-stampedecon2015-150717135240-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
















































![[DSC Europe 25] Nikola Rajovic - Hardware Technologies Under the Hood: RISC-V...](https://cdn.slidesharecdn.com/ss_thumbnails/o2gptrmtoyqndgoshwgq-dsc2025-tenstorrent-rajovic-251205090438-814685f5-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Marija Vlajkovic & Andrea Radonjanin - Integration of AI tool...](https://cdn.slidesharecdn.com/ss_thumbnails/qf1jrglttoc3bm8s3aop-final-integration-of-ai-tools-251208151905-394f3a6a-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Jim Sterne - Adopting Generative AI Capabilities Into the Ent...](https://cdn.slidesharecdn.com/ss_thumbnails/sxhpofuorcagxsaulkmt-3-251204082258-7e66bc48-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Andy Cotgreave - Nothing is new in analytics.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/mba4vzcurvoh5lfrd5zw-6-251205194645-341bbbbe-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Goran Obradovic - The Rise of Sovereign AI: Building the Regi...](https://cdn.slidesharecdn.com/ss_thumbnails/7nw2xxixrxqdxvrb5wca-6-251205085714-ab09a2ac-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Dragana Ilic - AI for Big Data in Astronomy.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/8palya86qaatvjhva1ms-2-dragana-ilic-ai-ilic-251208151906-652b819c-thumbnail.jpg?width=640&height=640&fit=bounds)


