




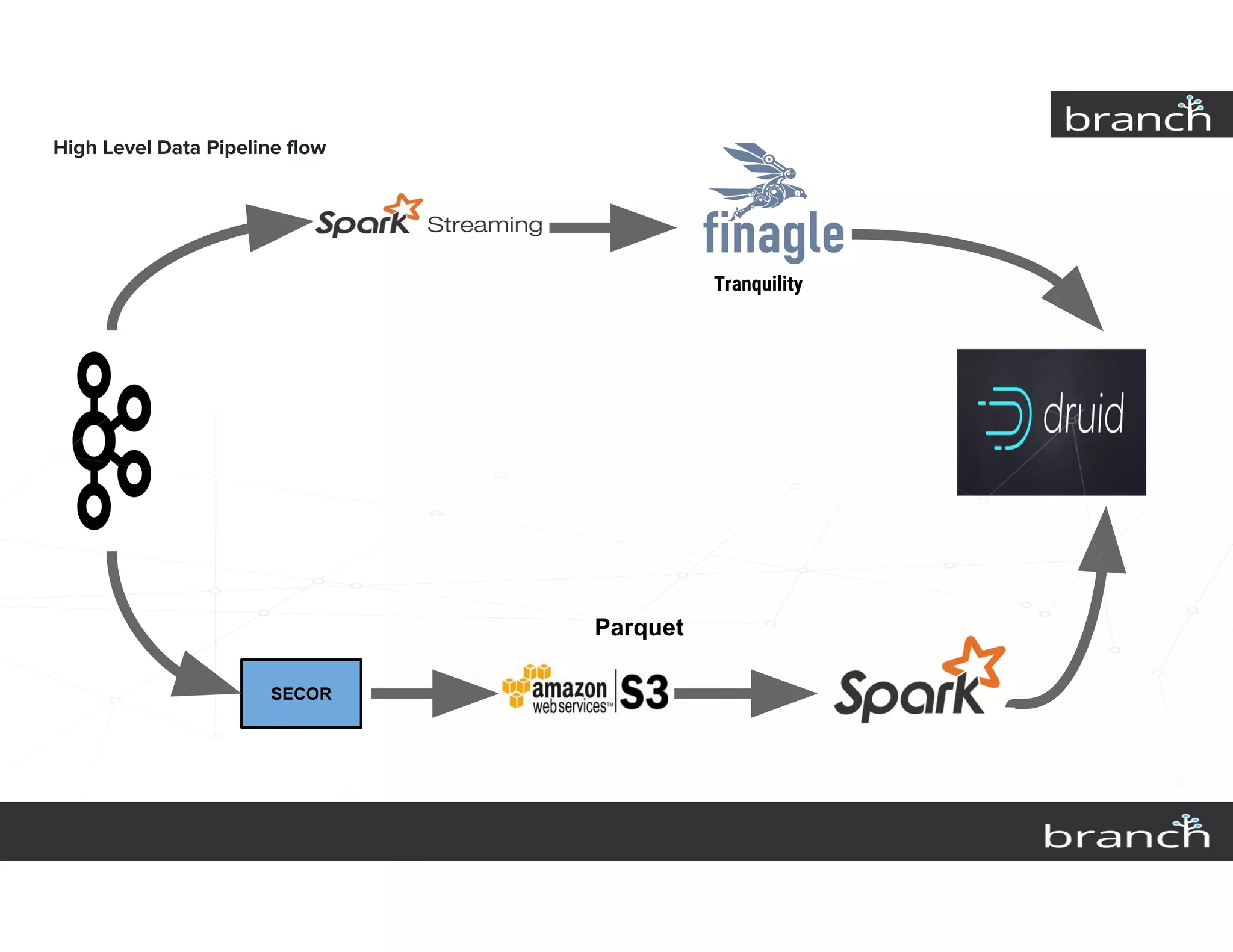
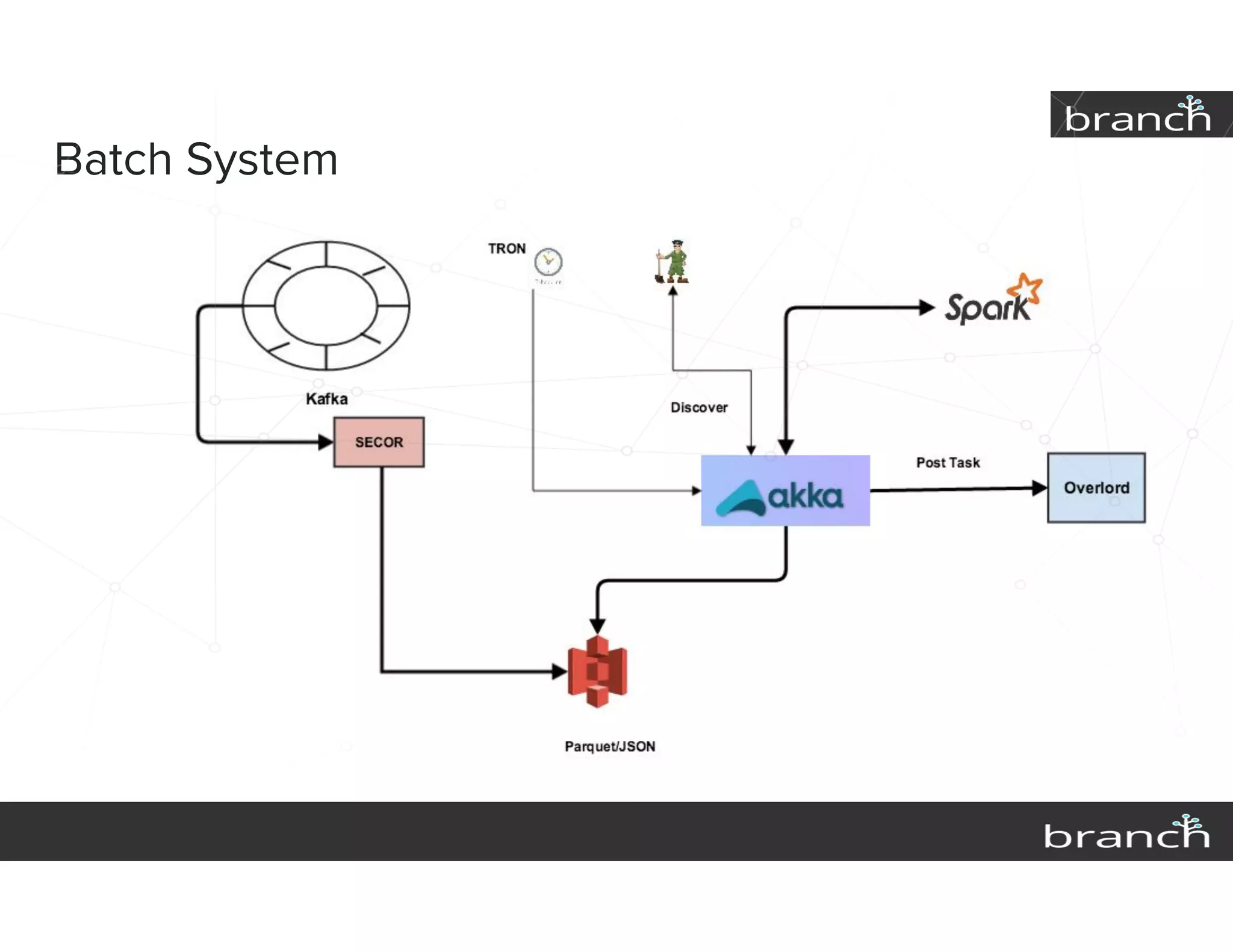
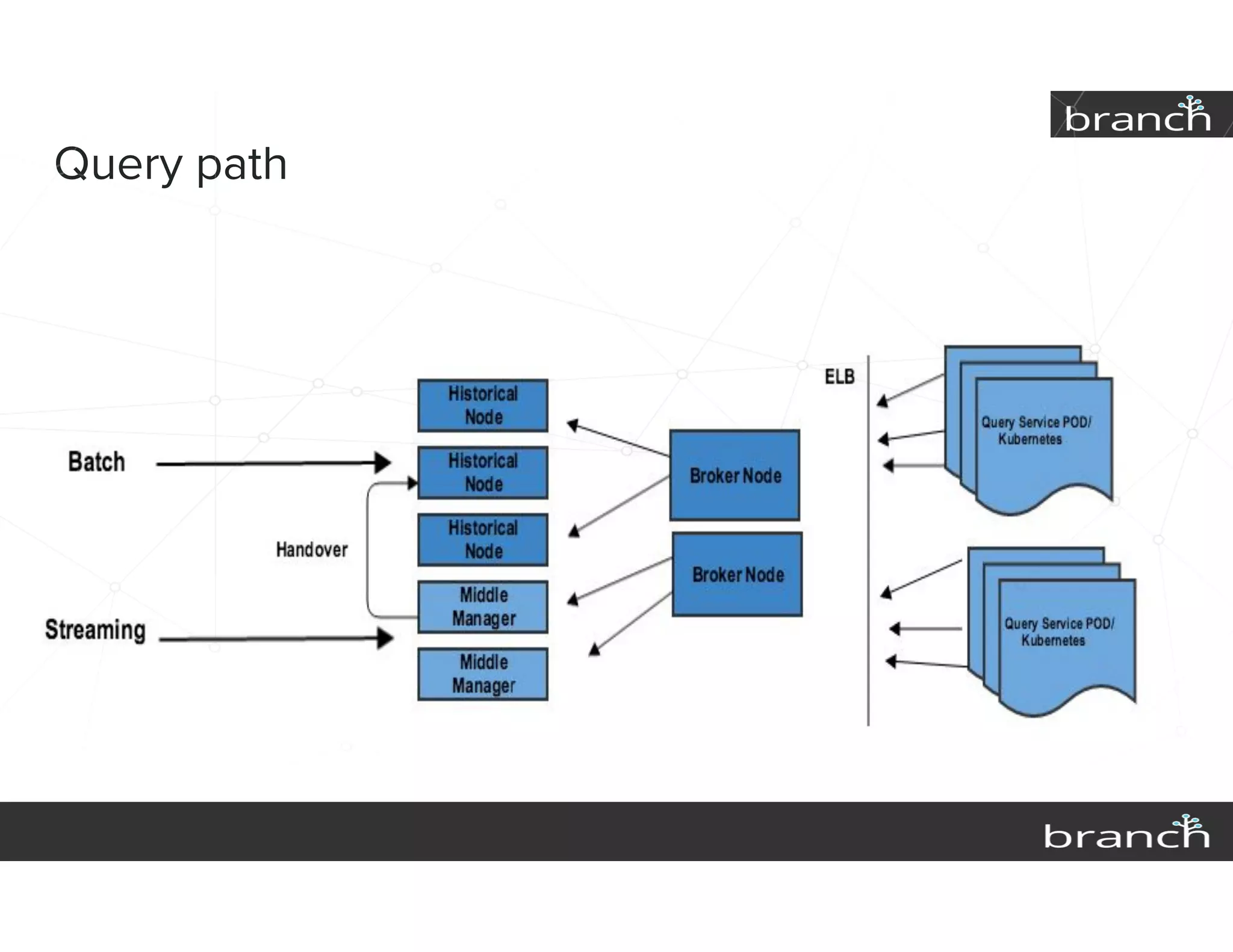


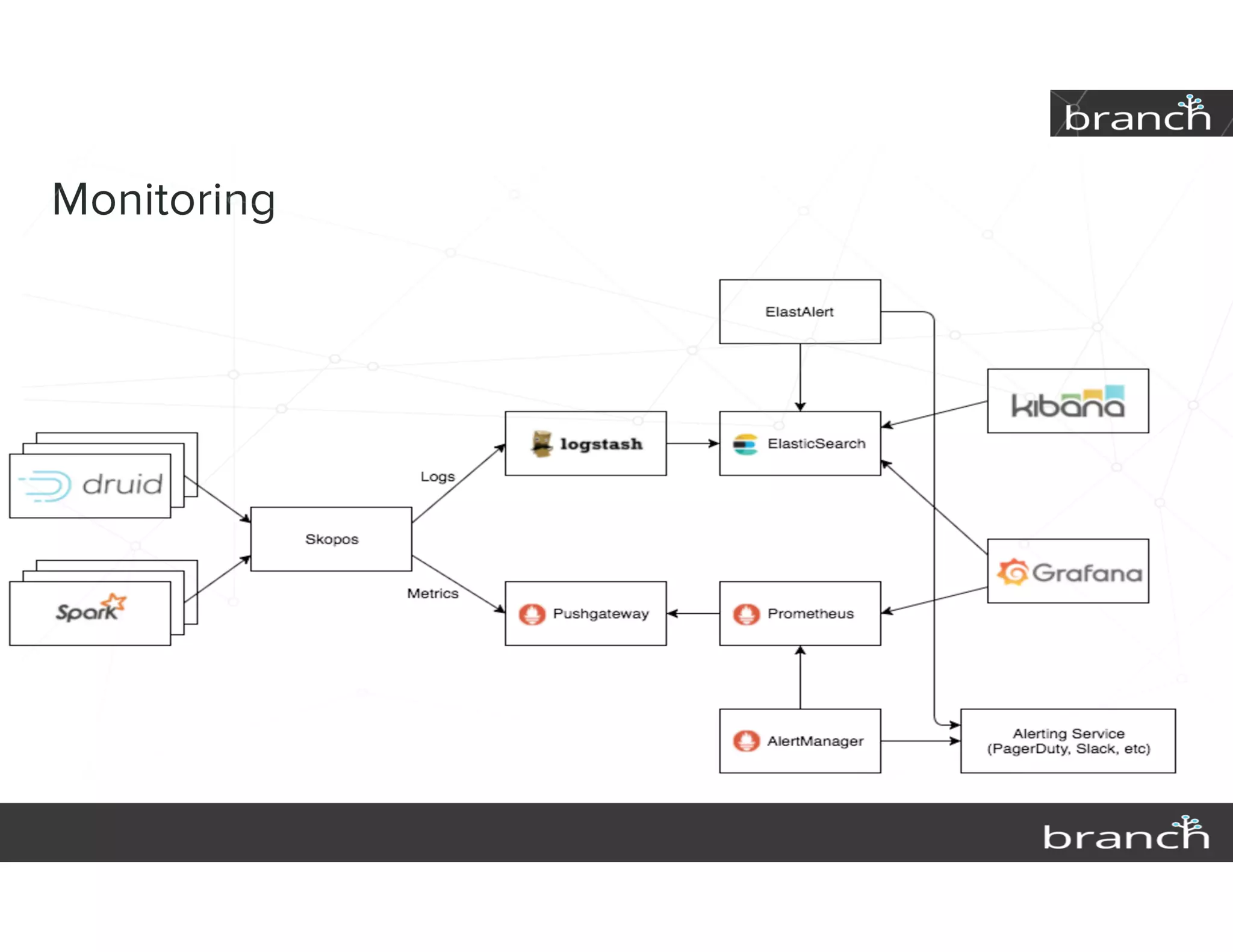
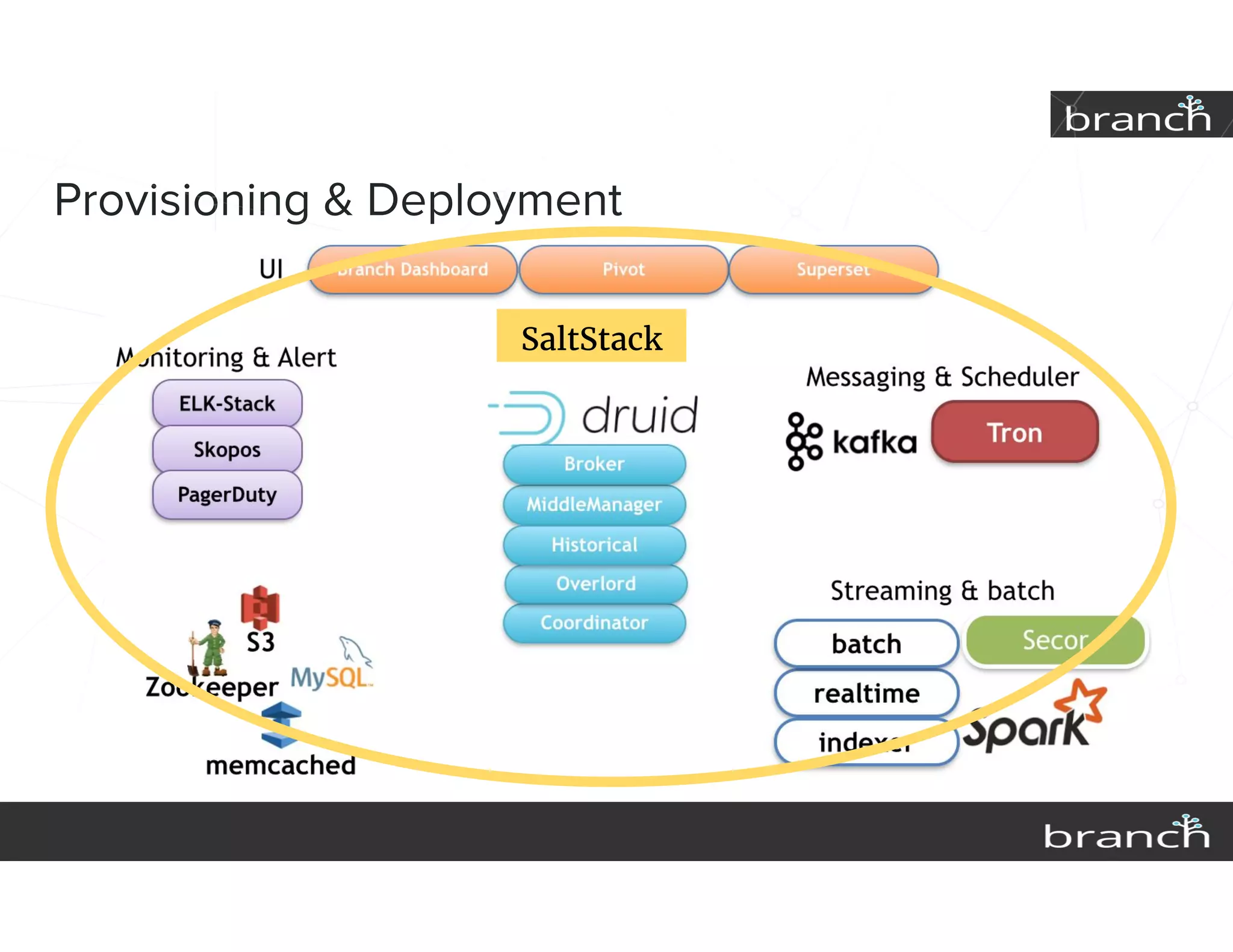
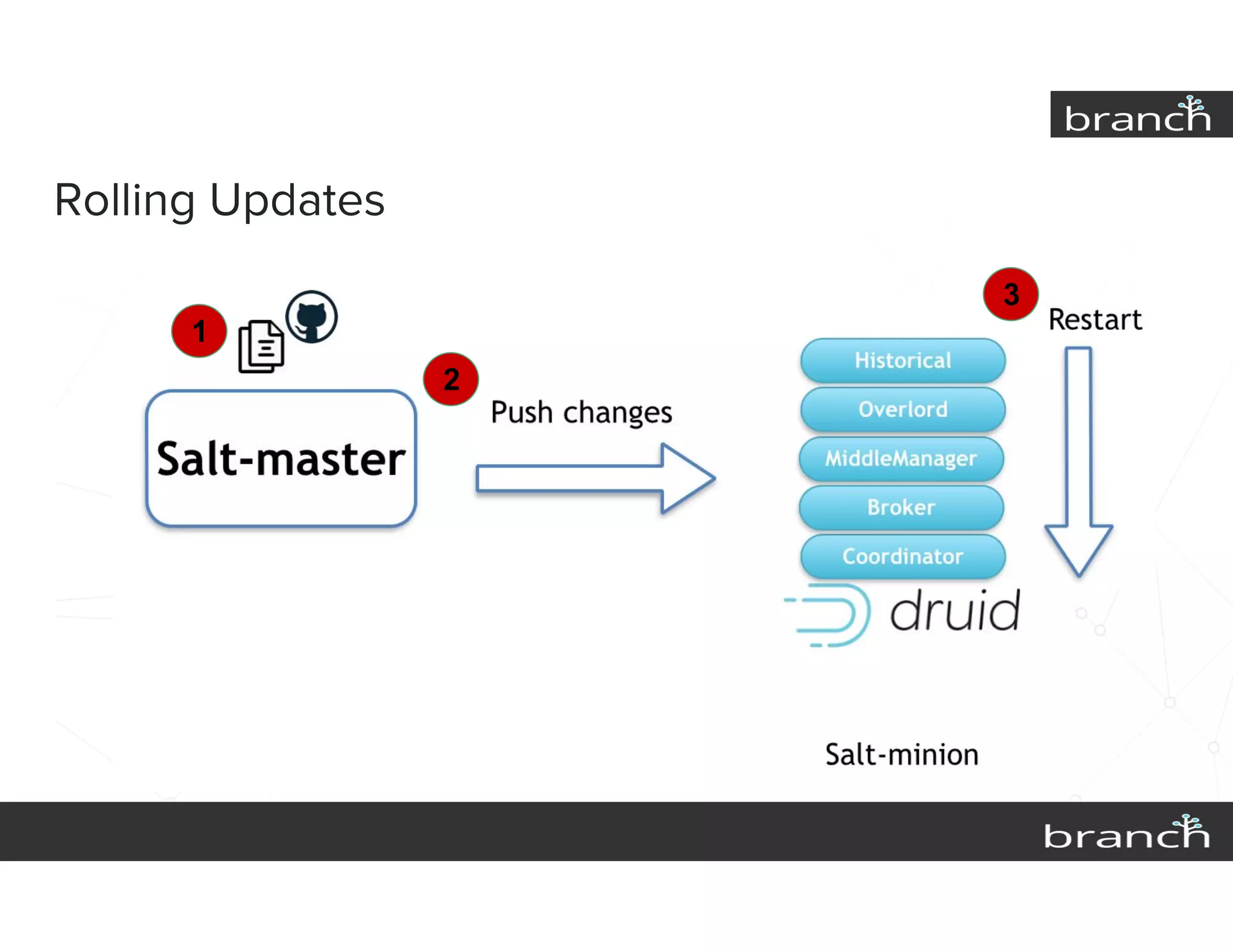


The document summarizes Druid, an open source data analytics platform, and how it has enhanced the data platform for a company to enable better business decisions. Key features of Druid include sub-second aggregate queries, real-time analytics dashboards, and live queries for unique users. Druid has helped scale to several hundred terabytes of data with thousands of queries per second while supporting new analytics applications, ad hoc reporting, and exploratory analysis. Future plans include improving the query service and migrating components to technologies like Spark, Flink, Mesos and Docker.

















































![[DSC Europe 25] Behzad Hosseini - AI Agents in the Wild: Deploying Models tha...](https://cdn.slidesharecdn.com/ss_thumbnails/3qtejajvsjqrzwfept2c-10-251212103250-7f2b1068-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Ivan Petrovic - Is it really that expensive to build an AI sy...](https://cdn.slidesharecdn.com/ss_thumbnails/ybqhdwvusbg7jms3doxh-9-251216105605-7aab5a10-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Velibor Ilic - Autonomous Driving - How AI Shapes Technical ...](https://cdn.slidesharecdn.com/ss_thumbnails/gwu9aqths9ovngsrhidc-3-velibor-ilic-autonomous-driving-how-ai-shapes-technical-challenges-251219150035-7436923a-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dobrica Cosic - From Electrons to Innovation: How Granular Da...](https://cdn.slidesharecdn.com/ss_thumbnails/h4qk69zereaumbceubgr-dobrica-cosic-from-electrons-to-innovation-how-granular-data-and-analytics-are--251218085301-b982fb14-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Danica Soc - The Science Behind Marketing: Experimentation me...](https://cdn.slidesharecdn.com/ss_thumbnails/c0nofsggs9gw5ucmallr-3-251216103155-56bd64d1-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Maria Kokiasmenos - AI Governance US Perspective.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/eszqnbzlsqa2vch6dmci-6-251215095918-6fcdf45f-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Katherine Forrest - AI NOW: Understanding the Velocity of Cha...](https://cdn.slidesharecdn.com/ss_thumbnails/wvvbruqfrci0sfq9xwgb-4-251212104007-e5ad1987-thumbnail.jpg?width=640&height=640&fit=bounds)
