Download as PDF, PPTX








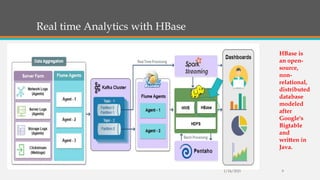








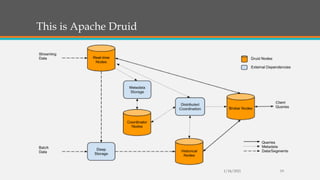




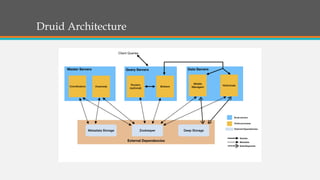



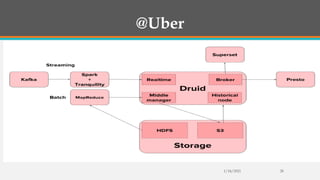




Fast Analytics aims to deliver analytics at decision-making speeds using technologies like Apache Kudu and Apache Druid for processing high volumes of data in real time. However, Kudu does not integrate well with Hadoop, so Druid is presented as a better solution for combining low-latency queries with Hadoop compatibility. The document then provides overviews of the capabilities and use cases of Druid, examples of companies using Druid, and instructions for getting started with a Druid quickstart tutorial.