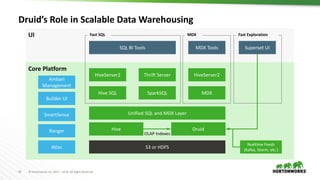
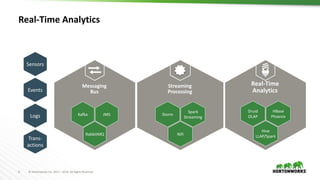
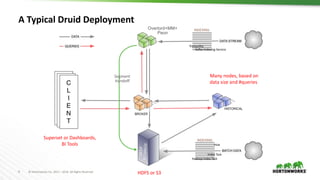
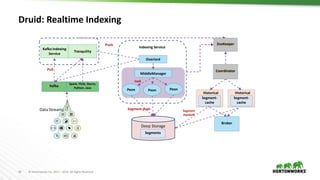
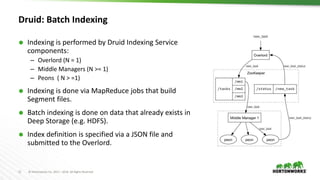
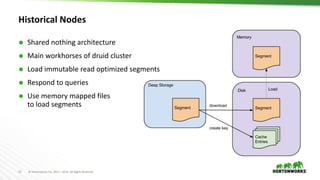
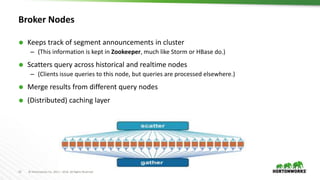
This document provides an overview of Druid, an open-source distributed real-time analytics database. Druid is designed to ingest and query large amounts of data quickly. It can combine both historical and real-time data streams. Druid uses a column-oriented data structure and supports features like streaming data ingestion, sub-second queries, and approximate computation. The document describes the various components of Druid including indexing, serving, and coordination nodes and how they work together. It also discusses querying, integration with Hive, and compares Druid to other real-time analytics solutions.














![20 © Hortonworks Inc. 2011 – 2016. All Rights Reserved
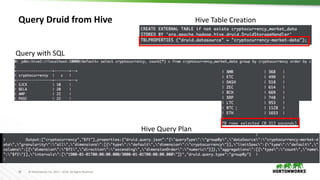
Druid: Real-time Ingestion using Kafka–Indexing-Service
{
"type": "kafka",
"dataSchema": {
"dataSource": "pvcc",
"parser": {
"type": "string",
"parseSpec": {
"format": "json",
"timestampSpec": {
"column": ”eta",
"format": "auto"},
"dimensionsSpec": { "dimensions":
[ "nextLocRmlCd","destRmlCd","nextLocOutboundL4ConsNbr", "outboundL4ConsNbr",
"lastKnownLocCd", "commitDt", "product2x2HighlevelGroupDesc", "product2x2PriorityNbr",
"enrouteStatus", "adjustedPackageType", "latestTranInfacilityState", "nextLocOutboundL4ConsTypeCd” ]}}
},
"metricsSpec": [{ "name": "count", "fieldName": "count", "type": "doubleSum” }],
"granularitySpec": { "type": "uniform", "segmentGranularity": "HOUR", "queryGranularity": "NONE” }},
"tuningConfig": {
"type": "kafka",
"maxRowsPerSegment": 5000000
},"ioConfig": {
"topic": "metrics",
"consumerProperties": {
"bootstrap.servers": "kafkabroker1:6667,kafkabroker2:6667",
"security.protocol": "SASL_PLAINTEXT",
"sasl.kerberos.service.name": "kafka"
},
"taskCount": 8,
"replicas": 2,
"taskDuration": "PT1H"
}
}](https://image.slidesharecdn.com/druiddeepdive-180721175656/85/Druid-deep-dive-20-320.jpg)













![40 © Hortonworks Inc. 2011 – 2016. All Rights Reserved
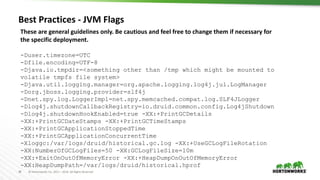
DirectMemory Exception
Not enough direct memory. Please adjust -XX:MaxDirectMemorySize,
druid.processing.buffer.sizeBytes, or druid.processing.numThreads:
maxDirectMemory[3,506,438,144], memoryNeeded[4,294,967,296] =
druid.processing.buffer.sizeBytes[1,073,741,824] * ( druid.processing.numThreads[3] + 1 )
Resolution:
-XX:MaxDirectMemorySize = druid.processing.buffer.sizeBytes * (druid.processing.numMergeBuffers +
druid.processing.numThreads + 1)
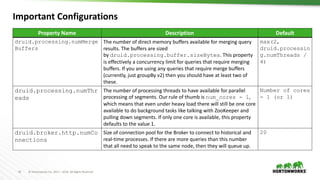
Property Name Description Default
druid.processing.buffer
.sizeBytes
This specifies a buffer size for the storage of intermediate
results. The computation engine in both the Historical and
MM nodes will use a scratch buffer of this size to do all of
their intermediate computations off-heap. Larger values
allow for more aggregations in a single pass over the data
while smaller values can require more passes depending on
the query that is being executed.
1073741824 (1GB)](https://image.slidesharecdn.com/druiddeepdive-180721175656/85/Druid-deep-dive-40-320.jpg)