The document presents an overview of Apache Druid, highlighting its use cases, design, and project status. It emphasizes Druid's capabilities in handling time series data for various analytics applications, real-time ingestion rates, and query performance. Additionally, it outlines data processing internals, architecture, scalability, and recent improvements in the Apache incubator program.







![© Cloudera, Inc. All rights reserved.
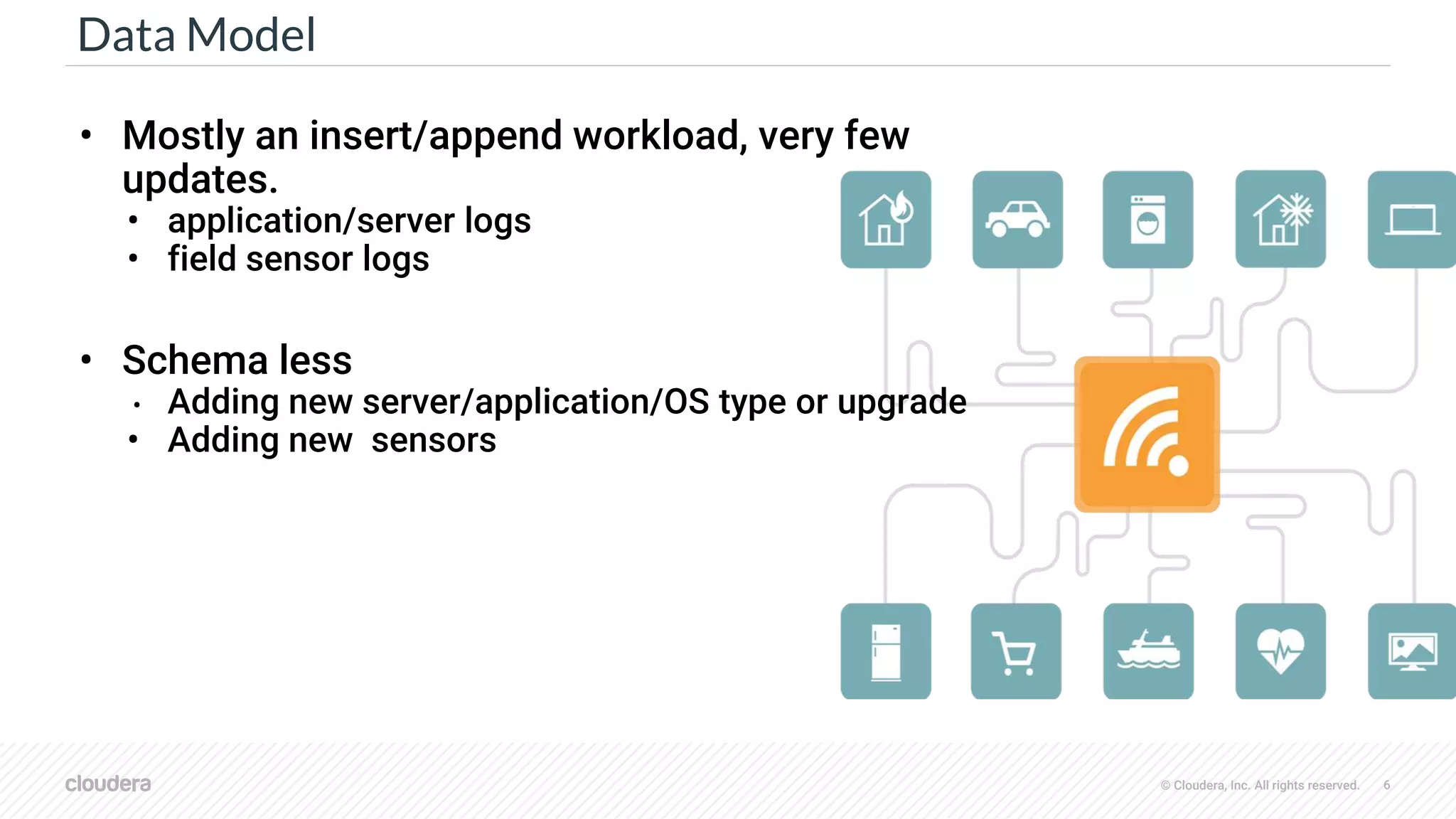
⬢ Replaced 5,000 Hbase cluster serving six petabytes of metrics to power Flurry
mobile analytics alone.[infoworld.com]
⬢ Tracking more than 2 billion mobiles devices [Flurry SDK @ MDC 2016].
⬢ Real-time Ingestion 20 billion events per day [Flurry SDK @ MDC 2016].
⬢ Sub second query latency.
⬢ Query the last 15 second.
Ad-hoc analytics.
High concurrency user-facing real-time slice-and-dice.
Real-time loads of 10s of billions of events per day.](https://image.slidesharecdn.com/latest-druid-2019-04-200326044517/75/Apache-Druid-Design-and-Future-prospect-10-2048.jpg)

![© Cloudera, Inc. All rights reserved.
COLUMN COMPRESSION -
DICTIONARIES
• Create ids
• bieberfever.com -> 0, ultratrimfast.com -> 1
• Store
• publisher -> [0, 0, 0, 1, 1, 1]
• advertiser -> [0, 0, 0, 0, 0, 0]
timestamp publisher advertiser gender country ... click price
2011-01-01T00:01:35Z bieberfever.com google.com Male USA 0 0.65
2011-01-01T00:03:63Z bieberfever.com google.com Male USA 0 0.62
2011-01-01T00:04:51Z bieberfever.com google.com Male USA 1 0.45
2011-01-01T01:00:00Z ultratrimfast.com google.com Female UK 0 0.87
2011-01-01T02:00:00Z ultratrimfast.com google.com Female UK 0 0.99
2011-01-01T02:00:00Z ultratrimfast.com google.com Female UK 1 1.53
...](https://image.slidesharecdn.com/latest-druid-2019-04-200326044517/75/Apache-Druid-Design-and-Future-prospect-13-2048.jpg)
![© Cloudera, Inc. All rights reserved.
BITMAP INDEXES
timestamp publisher advertiser gender country ... click price
2011-01-01T00:01:35Z bieberfever.com google.com Male USA 0 0.65
2011-01-01T00:03:63Z bieberfever.com google.com Male USA 0 0.62
2011-01-01T00:04:51Z bieberfever.com google.com Male USA 1 0.45
2011-01-01T01:00:00Z ultratrimfast.com google.com Female UK 0 0.87
2011-01-01T02:00:00Z ultratrimfast.com google.com Female UK 0 0.99
2011-01-01T02:00:00Z ultratrimfast.com google.com Female UK 1 1.53
...
• bieberfever.com -> [0, 1, 2] -> [111000]
• ultratrimfast.com -> [3, 4, 5] -> [000111]
• Compress using Concice or Roaring (take advantage of dimension sparsity)](https://image.slidesharecdn.com/latest-druid-2019-04-200326044517/75/Apache-Druid-Design-and-Future-prospect-14-2048.jpg)


![© Cloudera, Inc. All rights reserved.
DATA PROCESSING
⬢ Prune Partitions based on Time range predicate.
○ Segments [2010-2011]
⬢ Split query by time intervals to target processing nodes:
○ Push down filter predicates on attributes.
○ Prune attribute/metric columns.
⬢ Each processing node locally:
○ Build iterator columns/rows matching filters
○ Compute partial aggregate (apply limits if possible)
⬢ Collect partial results:
○ Finalize aggregate results
○ Compute post aggregate (eg AVG = SUM/COUNT or SUM(sales)/SUM(expenses))
○ Apply limits
SELECT `user`,
sum(`c_added`) AS s,
EXTRACT(year FROM
`__time`)
FROM druid_table
WHERE EXTRACT(year FROM
`__time`)
BETWEEN 2010 AND 2011
AND `user_country` =
‘USA’
GROUP BY `user`,
EXTRACT(year FROM
`__time`)
ORDER BY s DESC
LIMIT 10;](https://image.slidesharecdn.com/latest-druid-2019-04-200326044517/75/Apache-Druid-Design-and-Future-prospect-17-2048.jpg)
![© Cloudera, Inc. All rights reserved.
Theta Sketches KMV: Open sourced by Yahoo! [datasketches.github.io]
⬢ Predictable approximation error can be trade-off by sketch size
○ k = 4096 corresponds to an RSE of +/- 3.2% with 95% confidence.
○ k = 16K corresponds to an RSE of +/- 1.6% with 95% confidence.
⬢ Limited memory footprint and independent from data size
○ k = 4096 -> 32768 bytes.
○ K = 16384 -> 131072 bytes.
⬢ Mergebale at query time.
○ “merge rate of about 14.5 million sketches per second per processor thread”
[http://datasketches.github.io/docs/Theta/ThetaMergeSpeed.html].
⬢ Intersection can be computed at query time.
⬢ Duplication insensitive.
https://speakerdeck.com/druidio/approximate-algorithms-and-sketches-in-druid](https://image.slidesharecdn.com/latest-druid-2019-04-200326044517/75/Apache-Druid-Design-and-Future-prospect-18-2048.jpg)




![© Cloudera, Inc. All rights reserved. 27
Apache Druid Next
➔[WIP] Java 11 compatibility #5589
➔[DONE] Query vectorization #7093
➔[PROPOSAL] Dynamic prioritization and laning #6993
➔[PROPOSAL] Add support for t-digest backed aggregators #7303
➔[PROPOSAL] Initial Join Support Druid #6416](https://image.slidesharecdn.com/latest-druid-2019-04-200326044517/75/Apache-Druid-Design-and-Future-prospect-26-2048.jpg)