Downloaded 73 times

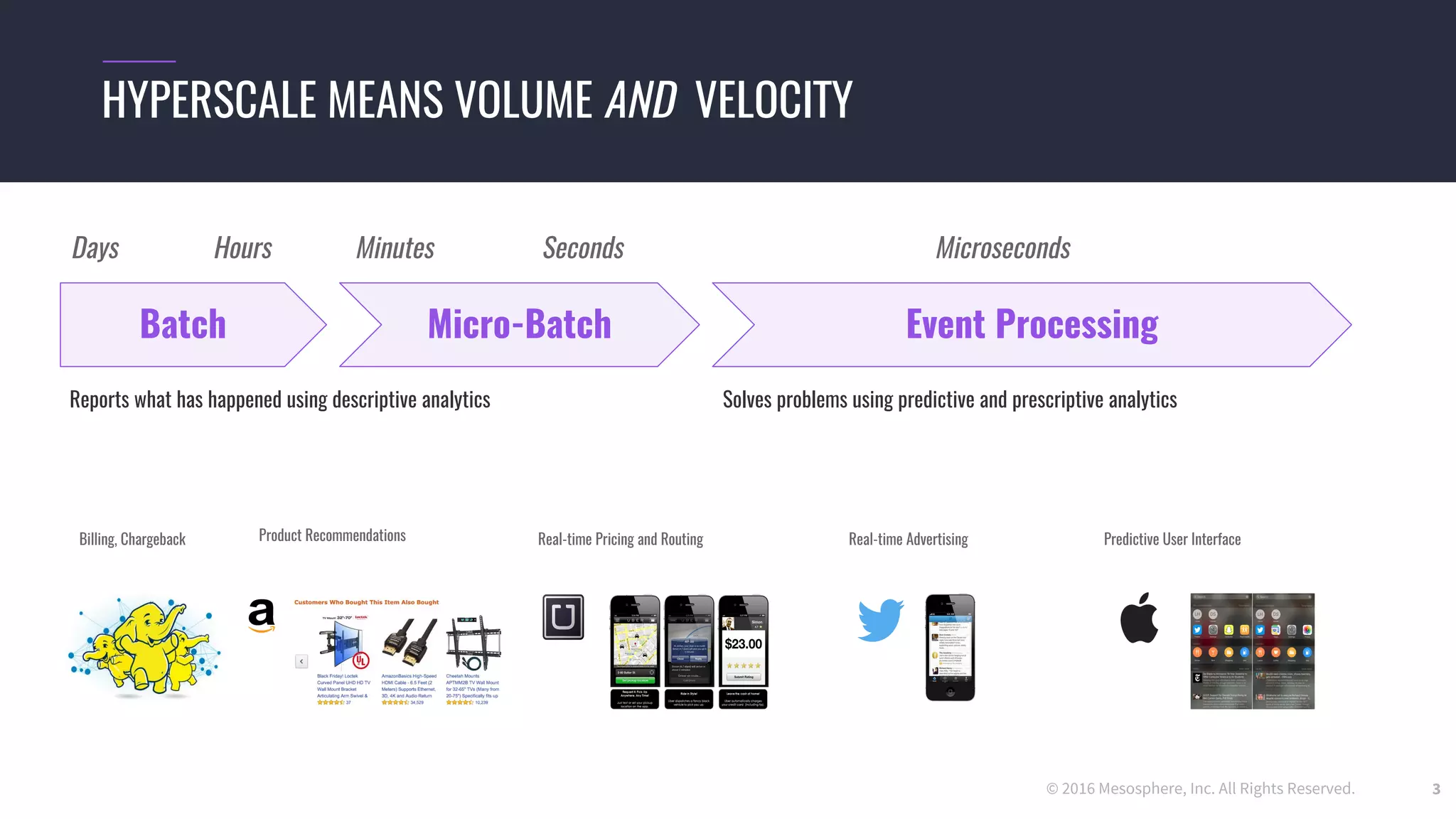
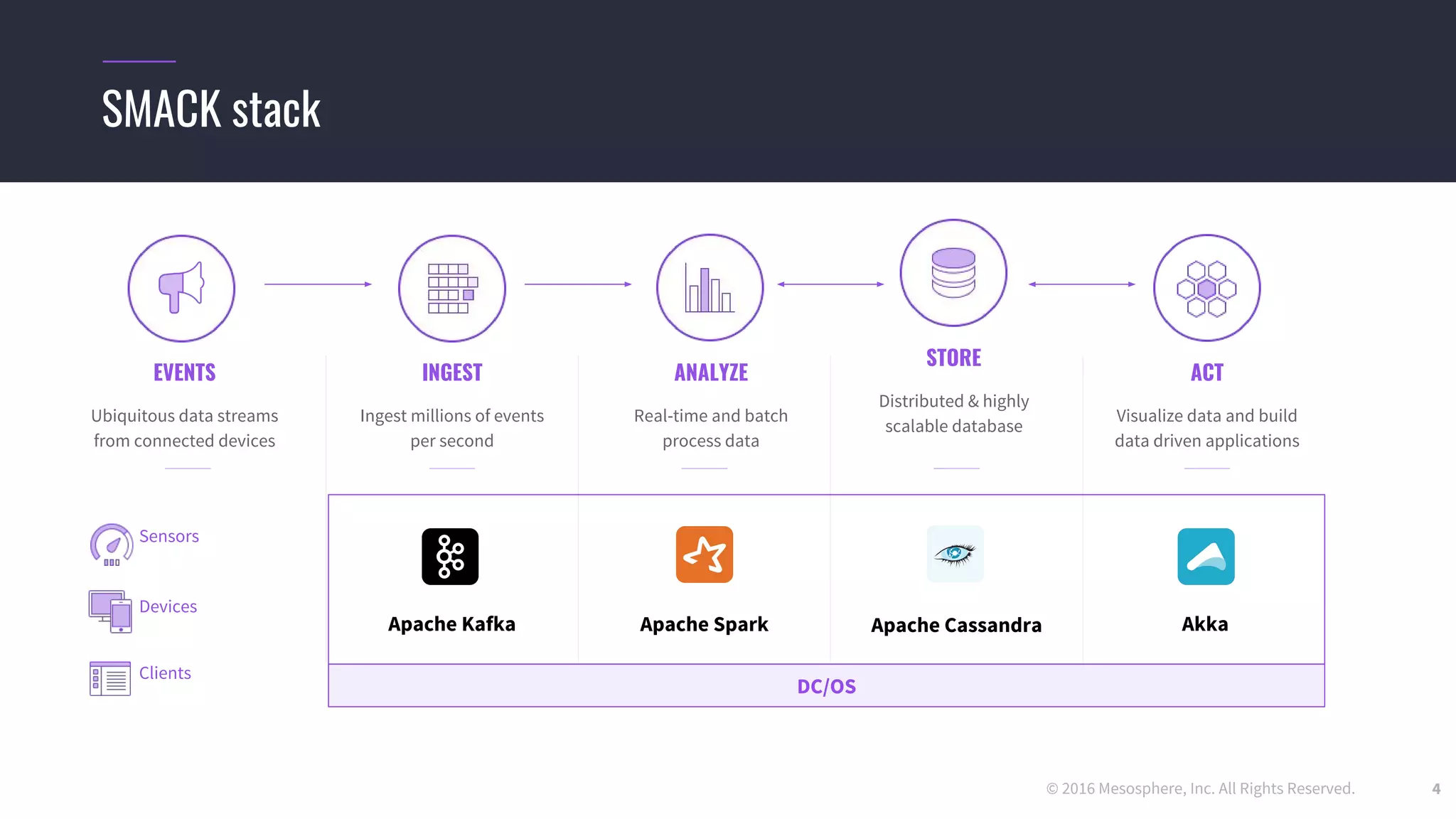


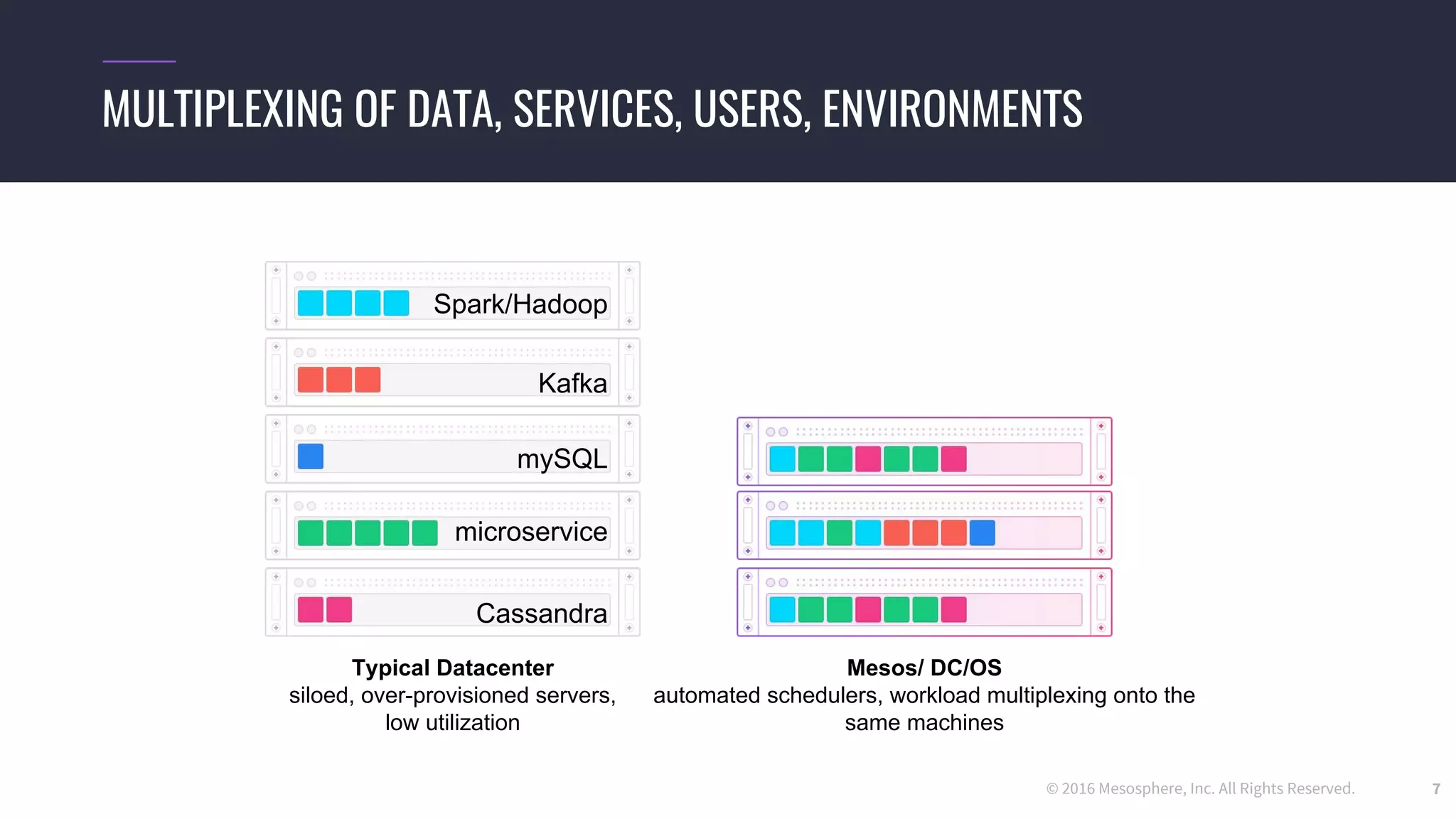
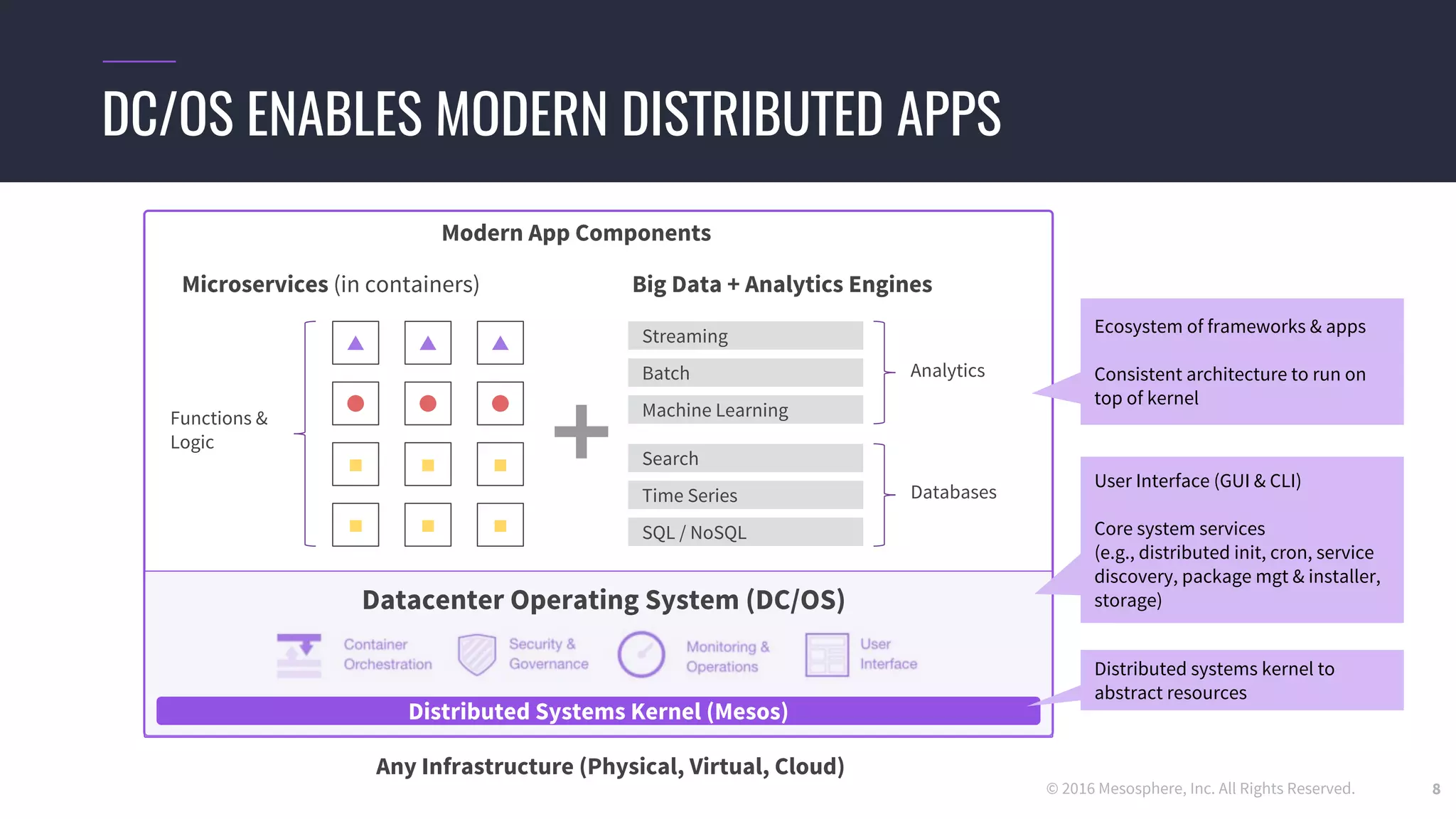

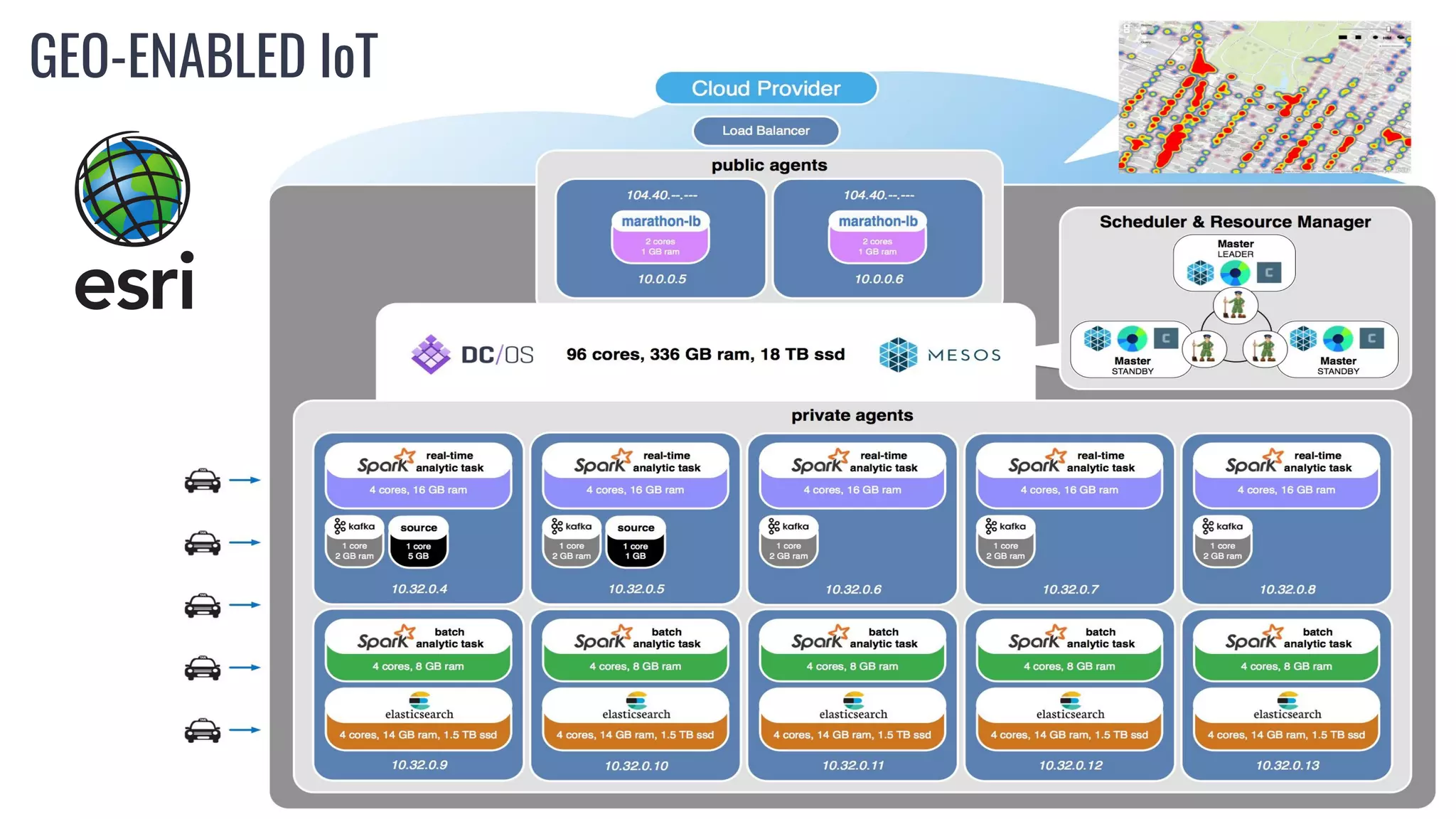
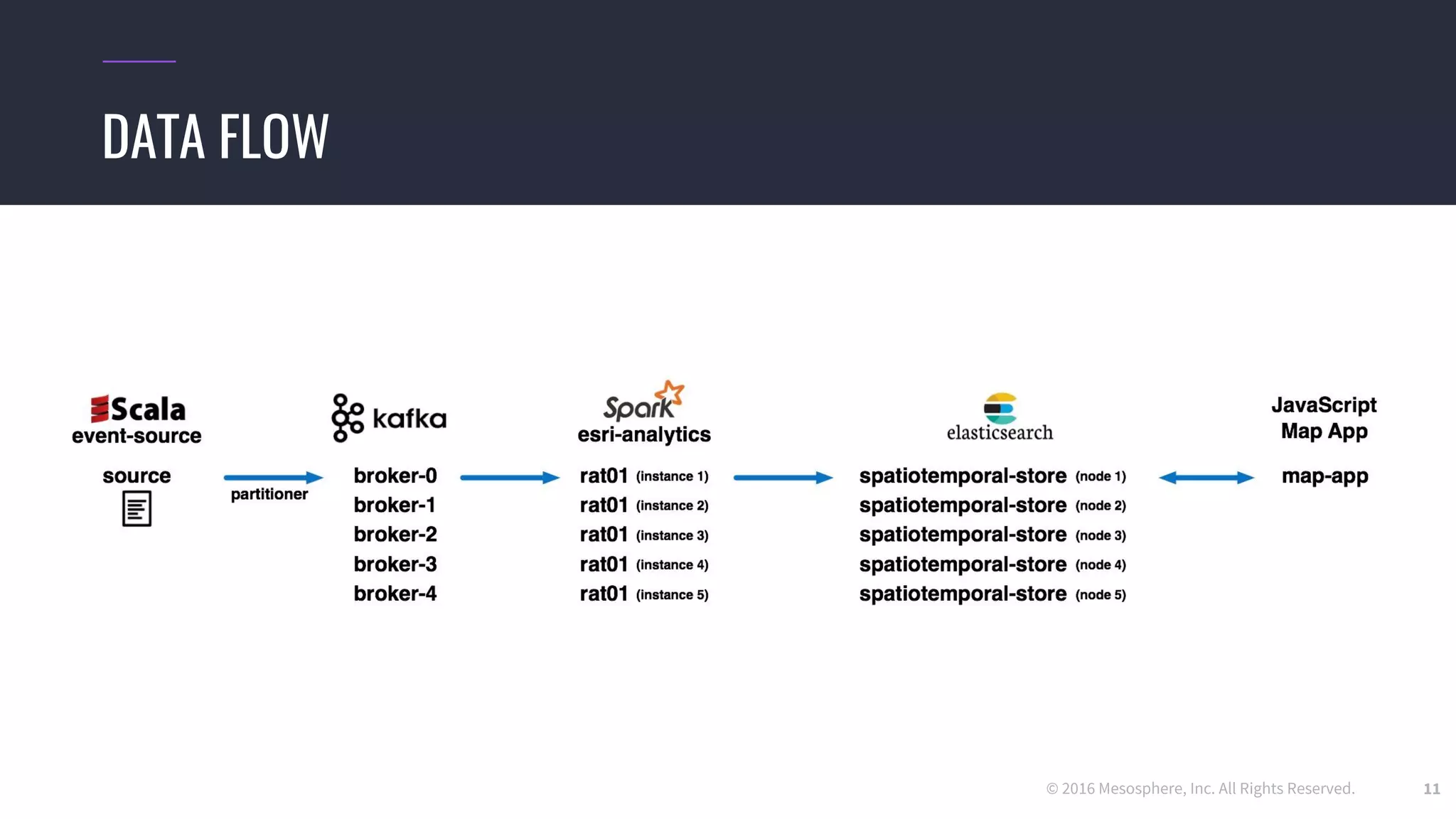
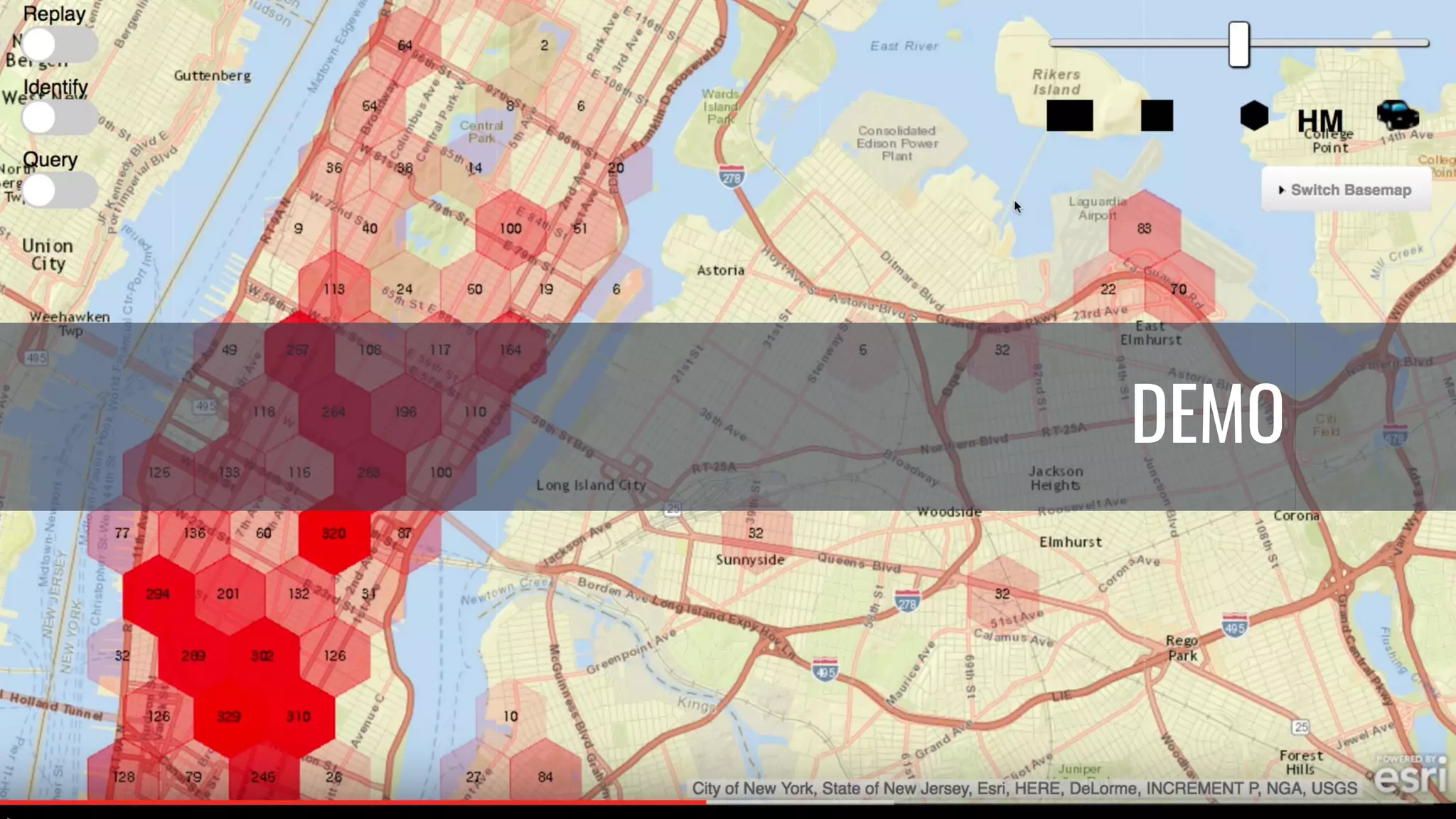



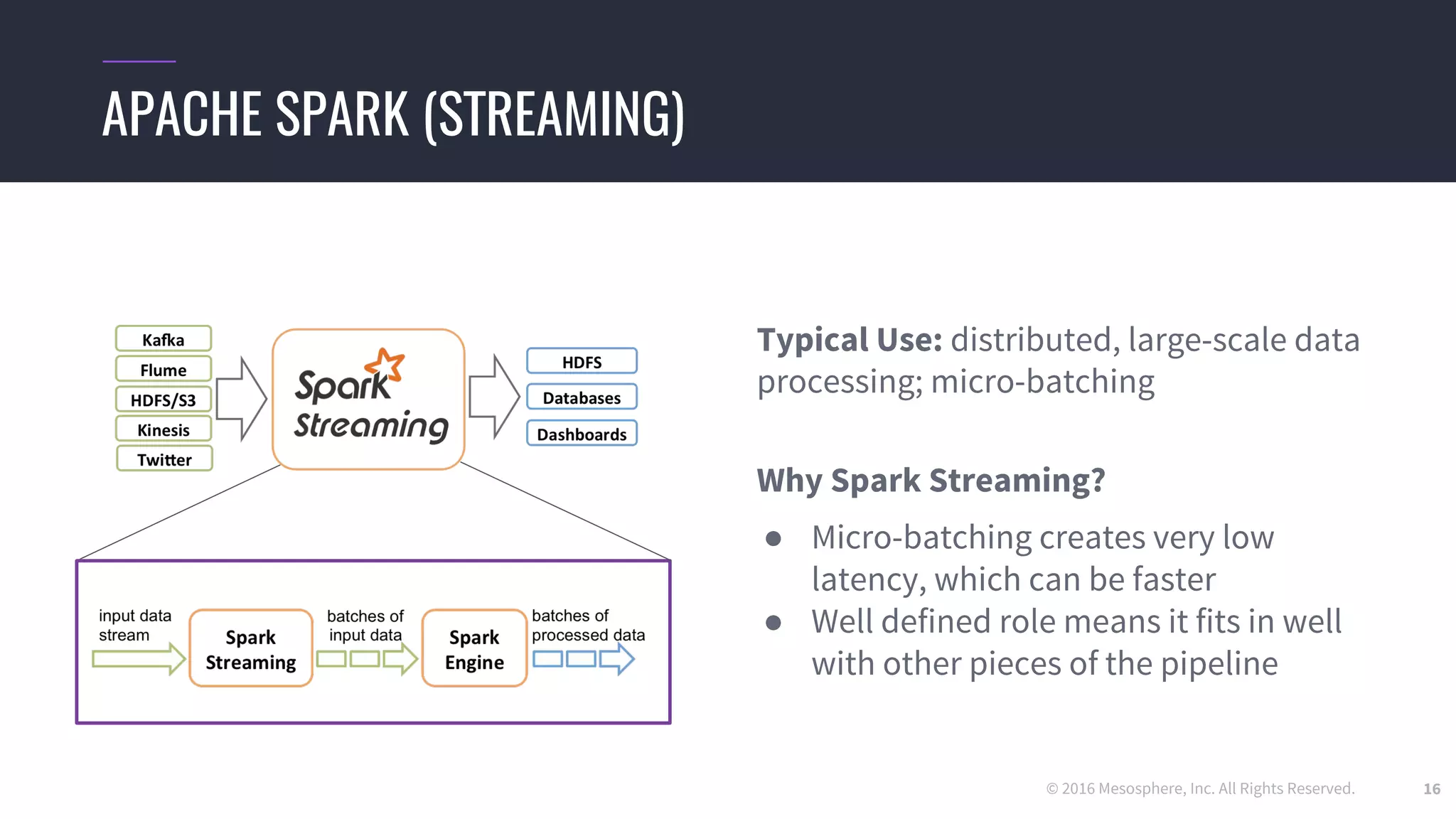

The document discusses powering predictive mapping at scale using the SMACK stack, which includes Spark, Kafka, and Elasticsearch. It describes how the SMACK stack can ingest millions of events per second from connected devices, store the data in Apache Spark, and allow real-time and batch processing of the data. It also provides an example of using the stack for real-time tracking of geo-enabled IoT devices and demonstrates the data flow and a demo of the system.
















































![[DO16] Mesosphere : Microservices meet Fast Data on Azure](https://cdn.slidesharecdn.com/ss_thumbnails/do16-170616021542-thumbnail.jpg?width=640&height=640&fit=bounds)


























































