

















[3,4] (00011000)
[5,6,7](0000111)
DATA0
0
0
1
1
2
2
2
DICT
Melbourne = 0
Perth = 1
Sydney = 2](https://image.slidesharecdn.com/dataconlasarreldruid101-201103193754/85/Apache-Druid-101-28-320.jpg)
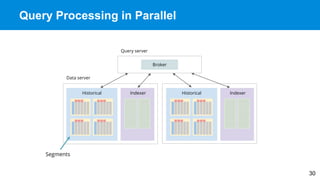


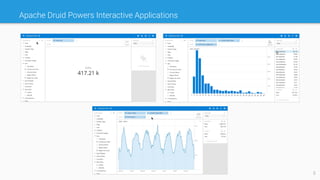
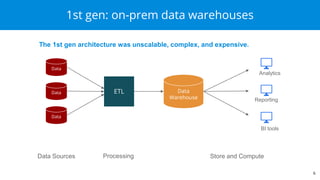
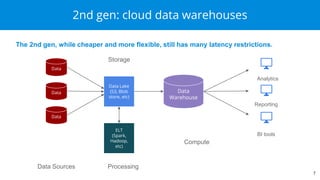
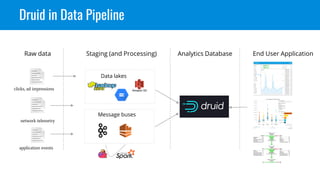
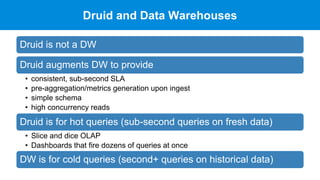
Apache Druid is a high-performance, real-time analytics database designed for low-latency and high concurrency, suitable for a variety of data applications. It was initially developed for digital advertising by Metamarkets and has since expanded across multiple sectors, allowing for fast ingestion and complex queries on large datasets. Druid's architecture is distinguished from traditional data warehouses by providing real-time data access, flexible schemas, and support for ad-hoc query environments.























































































