Download as PDF, PPTX






[3,4] (00011000)
[5,6,7](0000111)
DATA
0
0
0
1
1
2
2
2
DICT
DC = 0
LA = 1
SF = 2](https://image.slidesharecdn.com/truc5nvsyydnyt6i73iy-signature-dcf62be33e184862e1e0932e07ef403313505521e8d591a726d4cd5a38b071b8-poli-201007193045/85/Building-Data-Applications-with-Apache-Druid-9-320.jpg)

[3,4](00011000)
[5,6,7](0000111)
25
42
17
170
112
67
53
94
DATA2
1
2
1
1
0
0
0
[0,2](10100000)
[1,3,4](01011000)
[5,6,7](00000111)
DICT
DC = 0
LA = 1
SF = 2
INDEX
1800
2912
1953
3194
5690
1100
8423
9080
city
(STRING)
count
(LONG)
price
(LONG)
Dictionary encoded
(sorted)
Bitmap index
(stored compressed)](https://image.slidesharecdn.com/truc5nvsyydnyt6i73iy-signature-dcf62be33e184862e1e0932e07ef403313505521e8d591a726d4cd5a38b071b8-poli-201007193045/85/Building-Data-Applications-with-Apache-Druid-10-320.jpg)
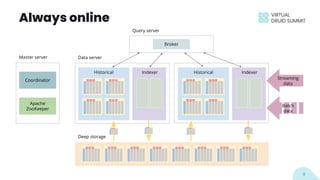
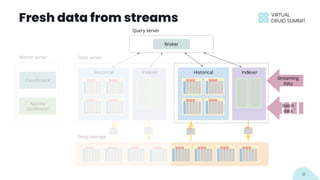

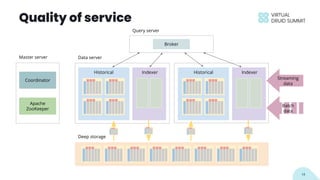
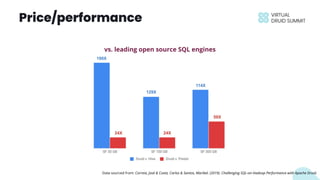
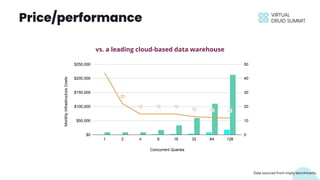




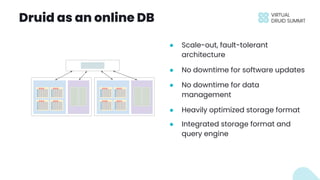
The document discusses building data applications using Apache Druid, highlighting its capabilities such as handling over 100 billion rows per day with low query latency. It emphasizes Druid’s architecture, which includes features like fault-tolerance, integrated storage, and optimized query performance. The presentation concludes with an invitation to engage with the Druid community and provides contact information.












































































