






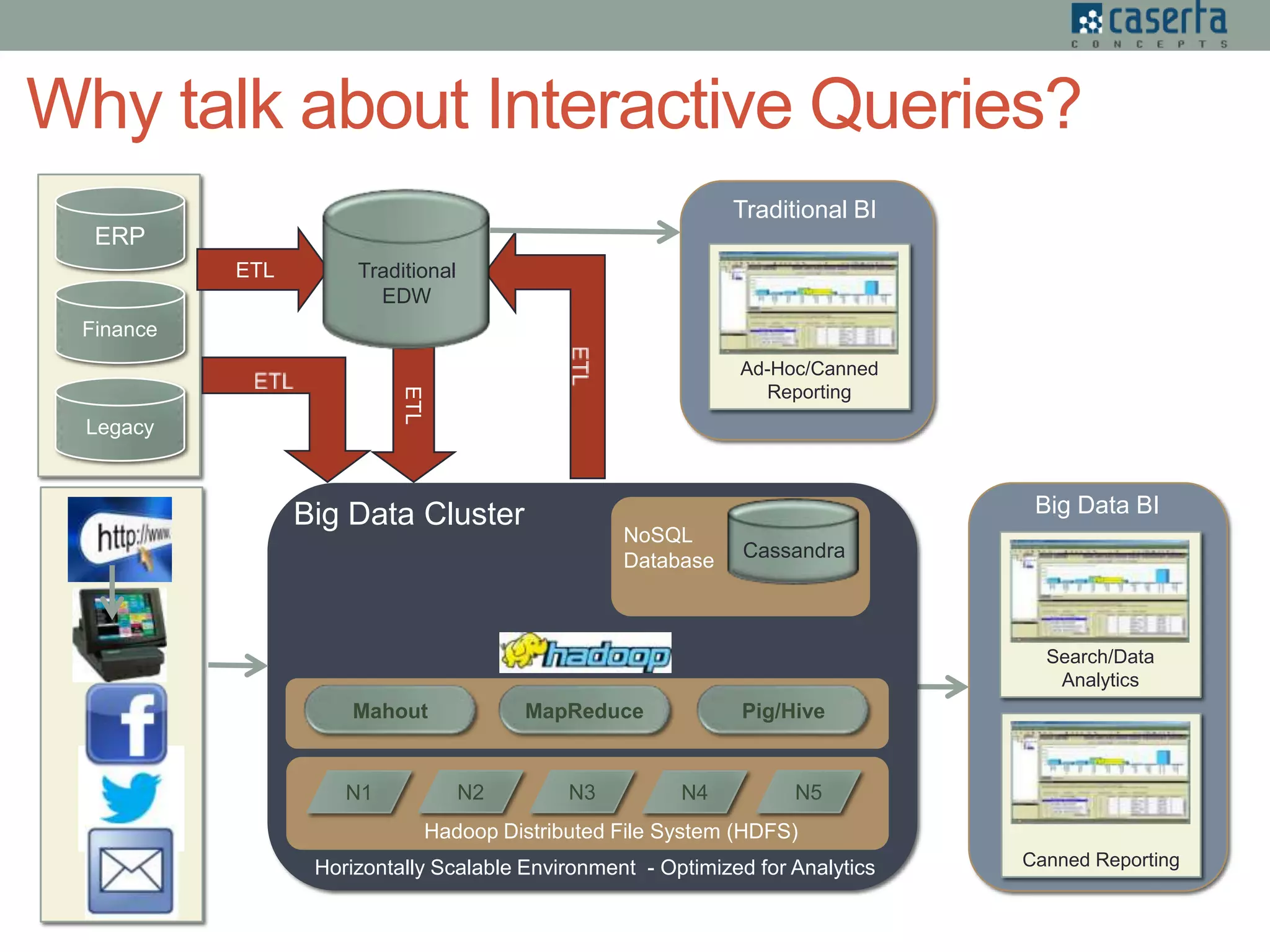





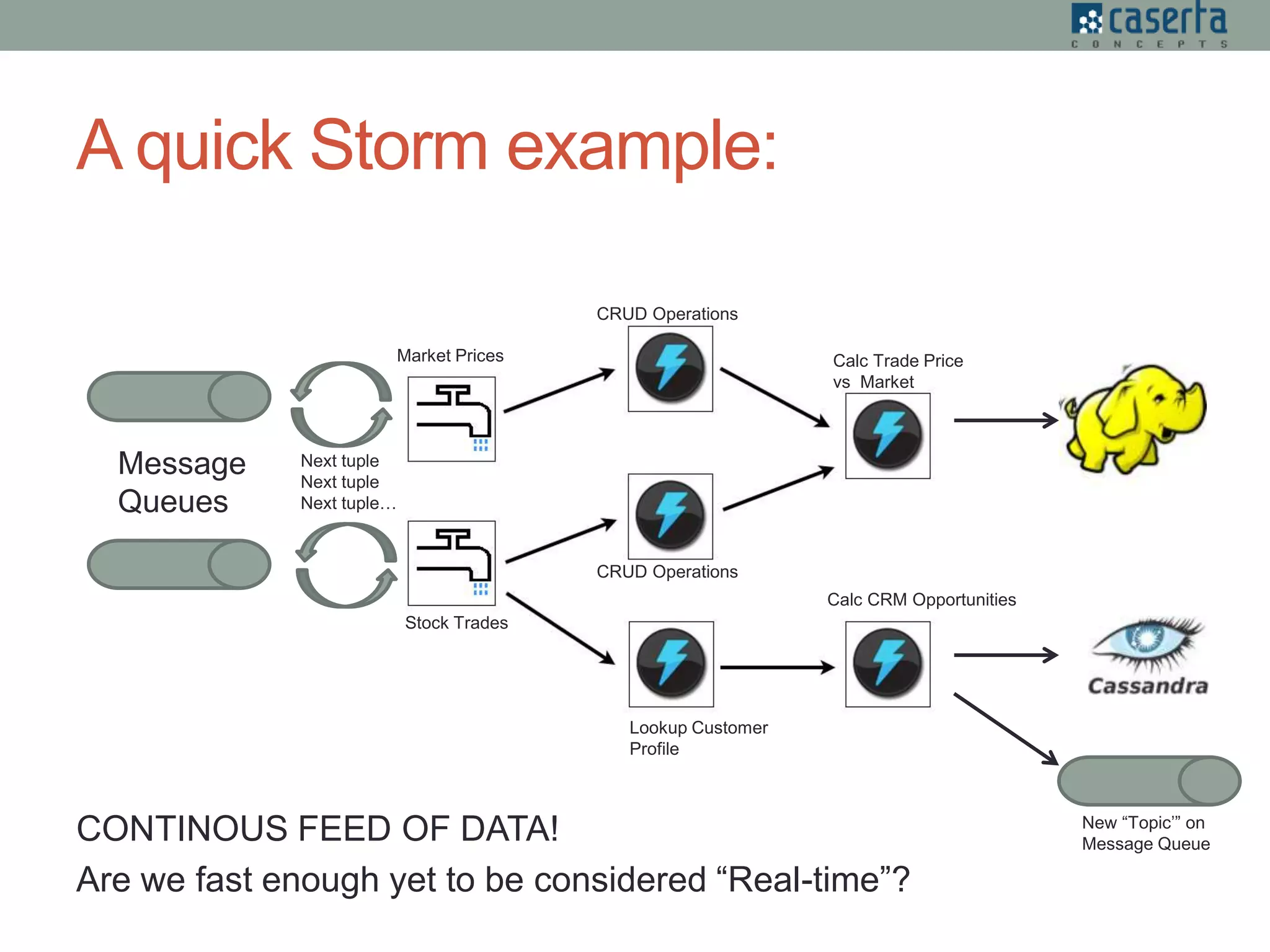








The document outlines a meetup hosted by Caserta Concepts focusing on real-time interactive queries in Hadoop, highlighting the difficulties and solutions in achieving low-latency data processing and querying. It discusses various tools and technologies for data ingestion and querying, including streaming, micro-batch processing, and different query engines like Stinger and Drill. The event aims to provide networking opportunities and share expert insights on big data in industries such as finance, healthcare, and retail.


































![[Sneak Preview] Apache Spark: Preparing for the next wave of Reactive Big Data](https://cdn.slidesharecdn.com/ss_thumbnails/coll-report-typesafe-apache-spark-slide-share-150127023731-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)








































































