







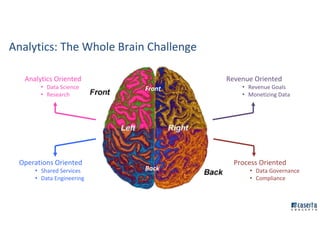
![Chief Data Organization (Oversight)
Vertical Business Area
[Sales/Finance/Marketing/Operations/Customer Svc]
Product Owner
SCRUM Master
Development Team
Business Subject Matter Expertise
Data Librarian/Data Stewardship
Data Science/ Statistical Skills
Data Engineering / Architecture
Presentation/ BI Report Development Skills
Data Quality Assurance
DevOps
IT Organization
(Oversight)
Enterprise Data Architect
Solution Engineers
Data Integration Practice
User Experience Practice
QA Practice
Operations Practice
Advanced Analytics
Business Analysts
Data Analysts
Data Scientists
Statisticians
Data Engineers
Planning Organization
Project Managers
Data Organization
Data Gov Coordinator
Data Librarians
Data Stewards
It Takes a Village!](https://image.slidesharecdn.com/strata2016presentation-160930205120/85/Building-New-Data-Ecosystem-for-Customer-Analytics-Strata-Hadoop-World-2016-9-320.jpg)



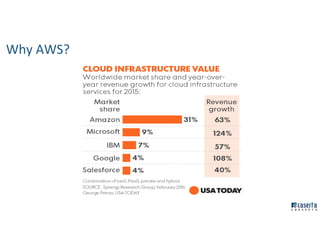
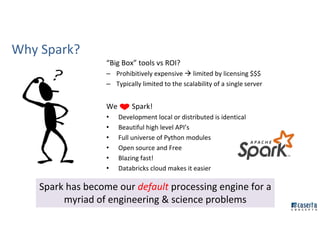
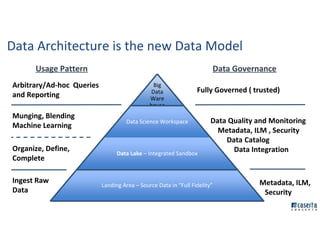
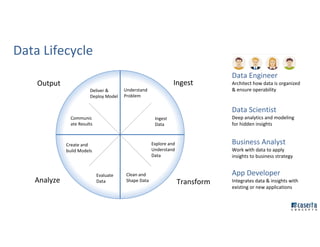
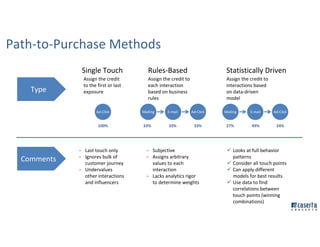

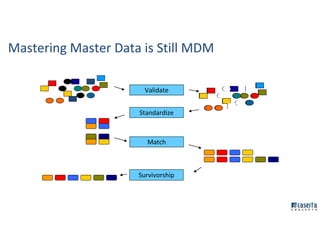

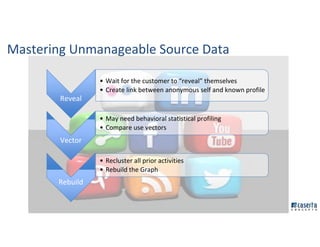

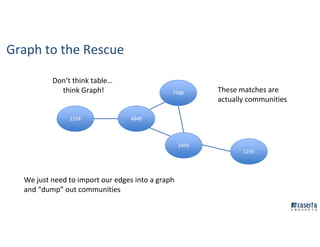

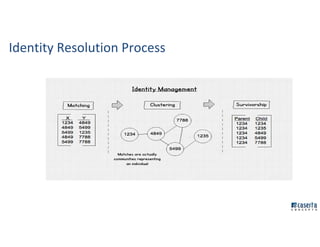
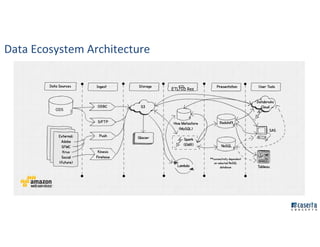
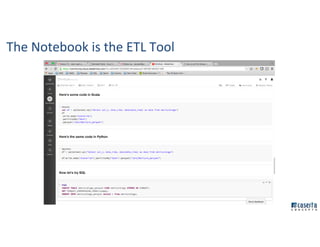






The document outlines Joe Caserta's professional journey, emphasizing his leadership in data analytics and innovation through Caserta Concepts, a recognized consulting firm. Key achievements include founding big data practices, launching a data warehousing meetup, and advocating for modern data ecosystems using technologies like AWS and Spark. It highlights the importance of data governance, customer behavior tracking, and advanced analytics in enhancing customer experiences and decision-making.









































































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)







