Download to read offline






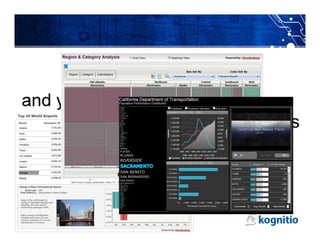






















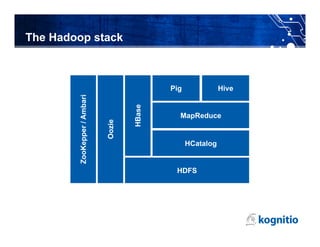

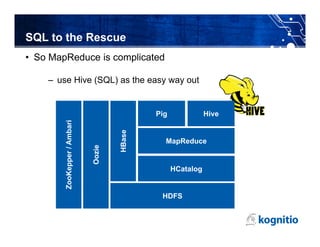







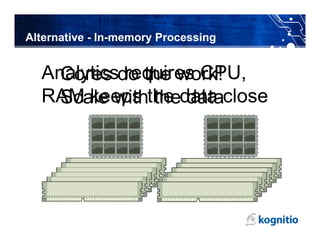

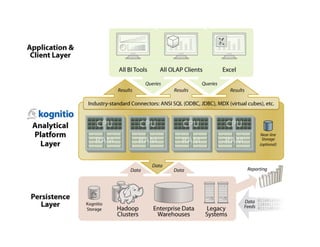
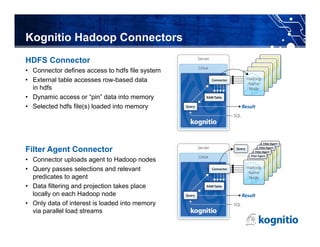




The document discusses the challenges and limitations of using Hadoop for interactive business intelligence (BI), particularly highlighting its slow query response times and complexity. It contrasts Hadoop's batch processing nature with the need for real-time analysis in BI, suggesting that an in-memory processing approach could minimize disruption and cut latency. The conclusion emphasizes the importance of simplifying data access and improving throughput while maintaining central governance in BI systems.










































































