Download as PDF, PPTX






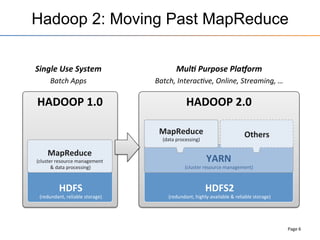
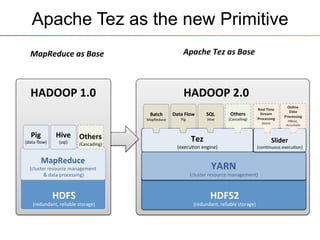
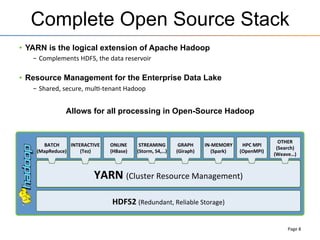
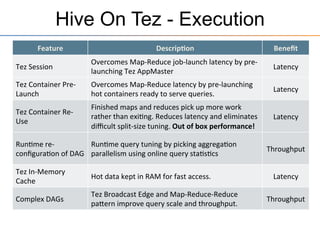

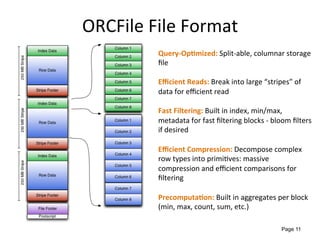

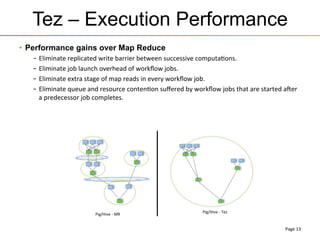
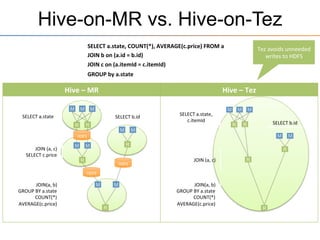

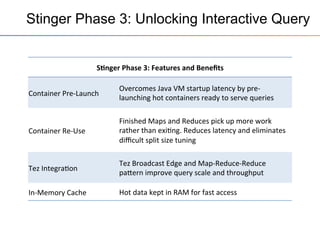
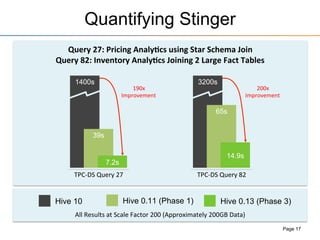
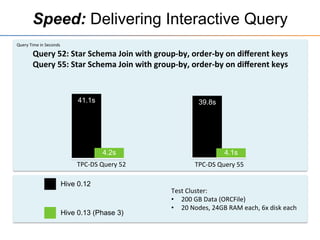
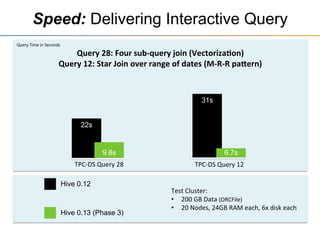
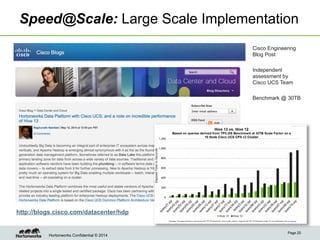




This document provides an overview of the Stinger initiative to improve the performance of Hive interactive queries. The Stinger project worked to optimize Hive so that queries return results in seconds instead of minutes or hours by implementing features like Hive on Tez, vectorized processing, predicate pushdown, the ORC file format, and a cost-based optimizer. These optimizations improved Hive performance by over 100 times, allowing interactive use of Hive for the first time on large datasets.




















































































