



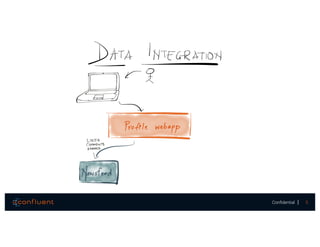
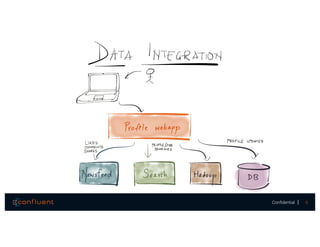
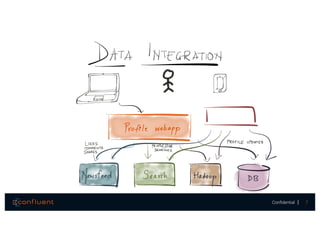

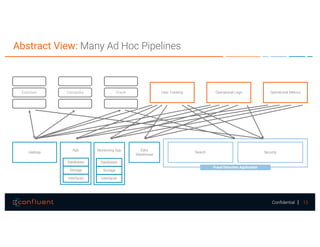
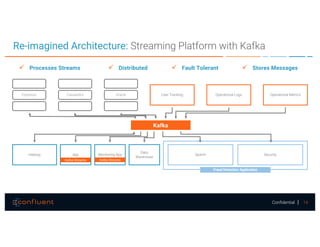

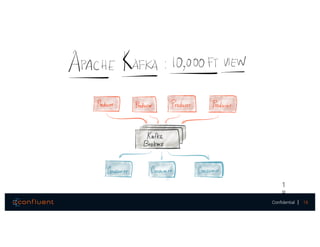



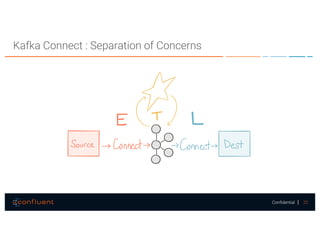
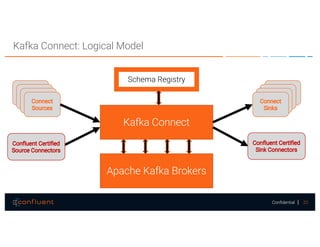

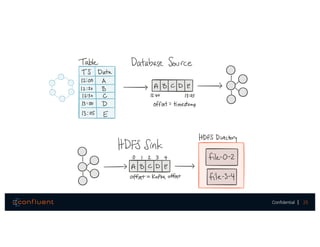


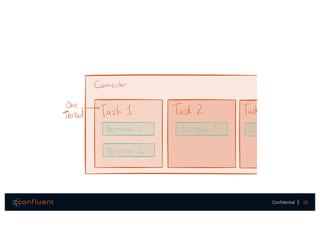





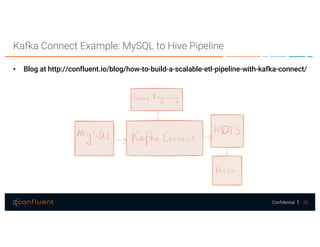

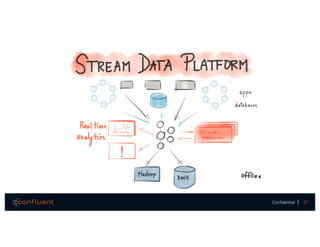


The document presents a discussion on data integration with Apache Kafka, covering design considerations, the Kafka solution, and Kafka Connect. It highlights the architecture of a streaming platform, reliability, data handling semantics, and the benefits of using Kafka Connect for simplified data integration. The document also includes a case example of a MySQL to Hive pipeline setup.











































































































