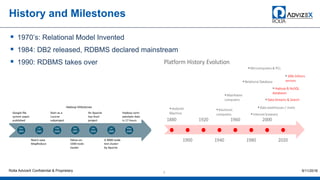
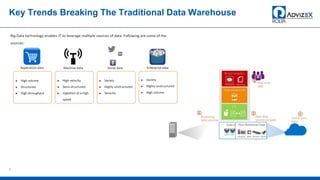
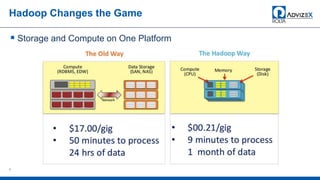
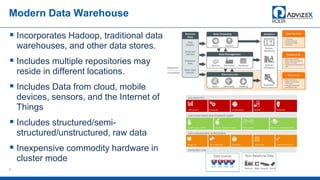
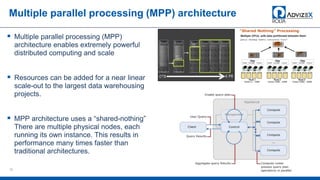
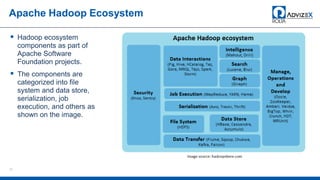
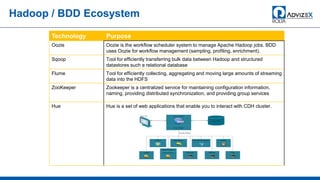
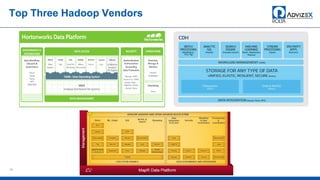
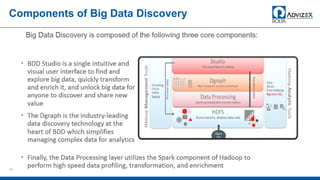
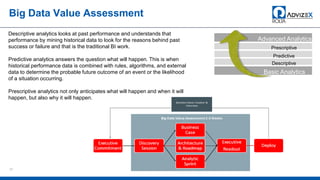
The document discusses the modern data warehouse and key trends driving changes from traditional data warehouses. It describes how modern data warehouses incorporate Hadoop, traditional data warehouses, and other data stores from multiple locations including cloud, mobile, sensors and IoT. Modern data warehouses use multiple parallel processing (MPP) architecture and the Apache Hadoop ecosystem including Hadoop Distributed File System, YARN, Hive, Spark and other tools. It also discusses the top Hadoop vendors and Oracle's technical innovations on Hadoop for data discovery, transformation, discovery and sharing. Finally, it covers the components of big data value assessment including descriptive, predictive and prescriptive analytics.