


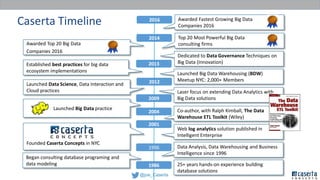


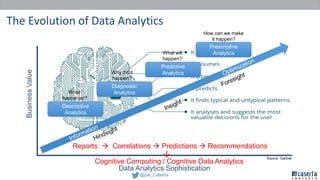



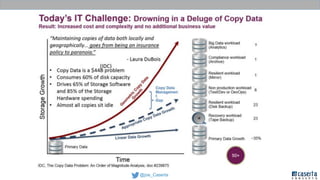


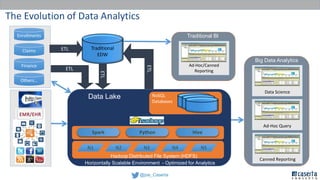







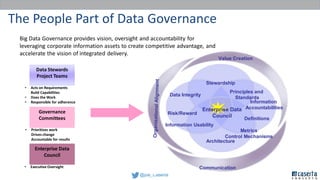
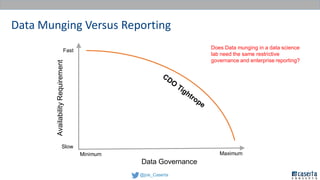
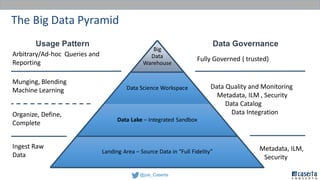
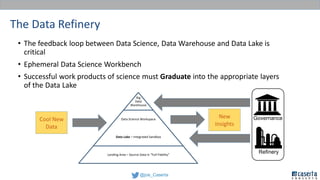



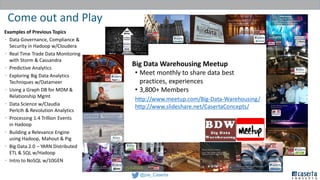

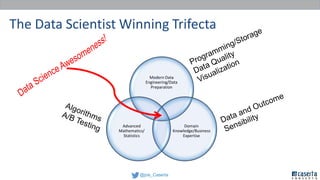
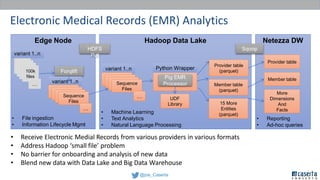

Joe Caserta's presentation on data lakes highlights the balance between data governance and innovation, emphasizing the importance of effective data management practices in modern analytics. He discusses the evolution of data analytics and the shift from traditional methods to more dynamic and scalable approaches enabled by big data technologies. The presentation also addresses the challenges of data sprawl and the necessity of strong governance frameworks to ensure data quality and usability in enterprise environments.





































































































