Downloaded 94 times









![15
Copyright © Intelligent Business Strategies 1992-2016!
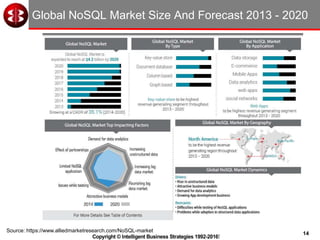
Key Value Stores Can Store Any Data - Examples
Key Value
10034 John Smith
82771
93441
{ "firstName": ”Wayne",
"lastName": ”Rooney",
"age": 25,
"address": {
"streetAddress": "21 Sir Matt Busby Way",
"city": ”Manchester”,
“country”: “England”,
"postalCode": “M1 6DY”
},
"phoneNumbers": [
{ "type": "home”,
"number": ”0161-123-1234”
},
{
"type": ”mobile",
"number": ”07779-123234”
}
]
}
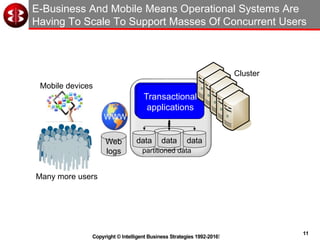
Key value store features:
• Very simple to understand
• Very scalable - hash partitioning
• Data access is via the key
• The application controls what’s stored in
the value
• Very fast performance
• Acceleration via in-memory processing
• Eventual consistency
• Often no support for data types
• No built-in referential integrity
• No understanding of data relationships
• The application must understand any
relationships in data
• Programmer is in complete control
• Application must navigate complex data
Use for specific operational applications](https://image.slidesharecdn.com/webinarjanuary2016-160129013108/85/Operational-Analytics-Using-Spark-and-NoSQL-Data-Stores-15-320.jpg)
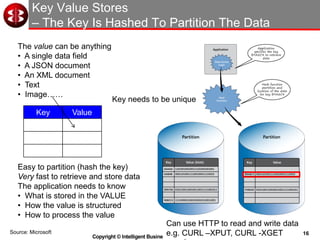
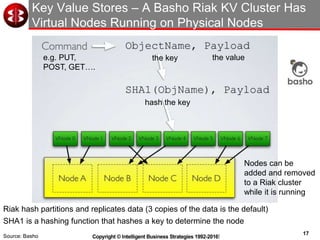
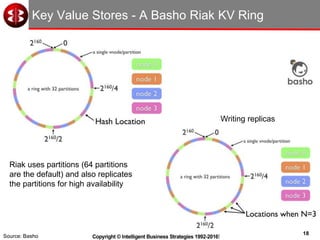

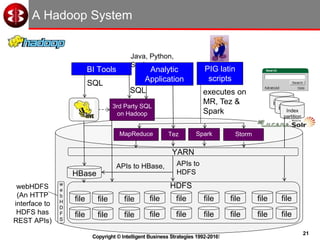
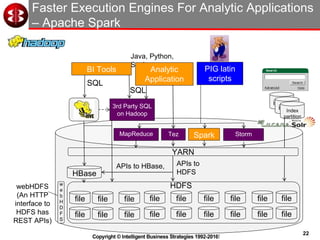
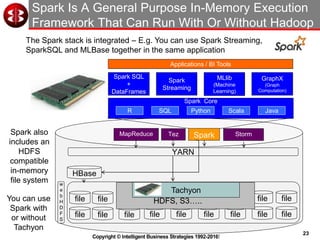
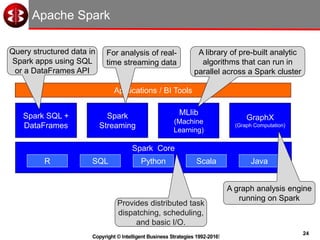
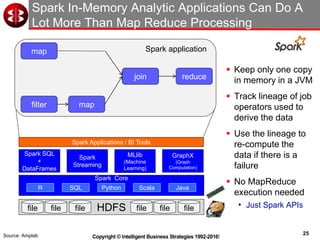
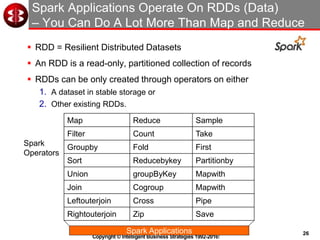

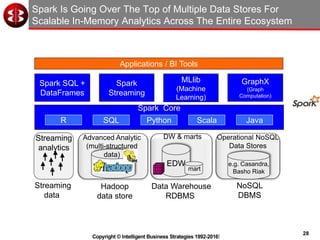



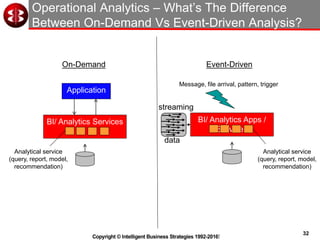
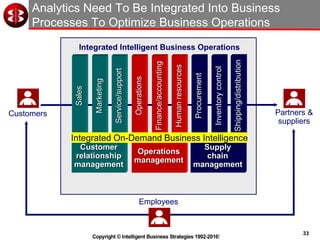
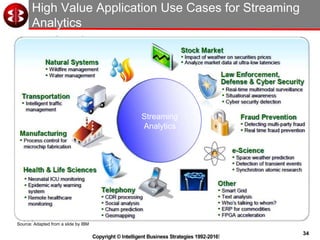


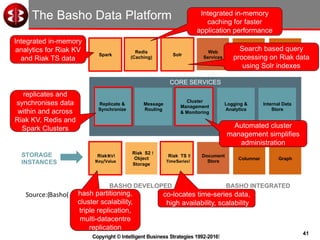

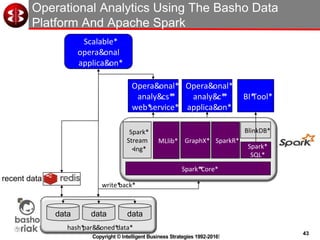





The document discusses delivering operational analytics using Apache Spark and NoSQL data stores, highlighting the evolving landscape of data management systems and the emergence of big data analytics. It emphasizes the need for scalable operational applications and the integration of analytics into core business processes to enhance decision-making, improve customer engagement, and optimize operational effectiveness. Additionally, it covers various types of NoSQL databases, their applications, and the critical role of in-memory processing for real-time analytics.











































































































