Downloaded 276 times




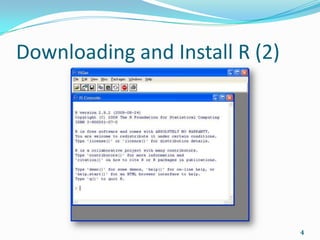
![First Steps (3)
5 * 4 b[4]
[1] 20 [1] 5
a <- (3 * 7) + 1 b[1:3]
a [1] 1 2 3
[1] 22
b[c(1,3,5)]
b <- c(1, 2, 3, 5, 8) [1] 1 3 8
b * 2
[1] 2 4 6 10 16 b[b > 4]
[1] 5 8
5](https://image.slidesharecdn.com/rintroduction-121027052050-phpapp01/85/R-Language-Introduction-5-320.jpg)
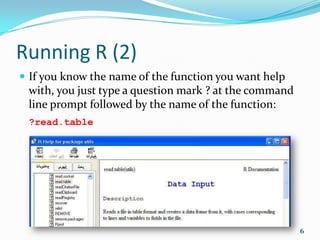


![First Steps (7)
To see a worked example just type the function name:
example(mean)
mean> x <- c(0:10, 50)
mean> xm <- mean(x)
mean> c(xm, mean(x, trim = 0.10))
[1] 8.75 5.50
mean> mean(USArrests, trim = 0.2)
Murder Assault UrbanPop Rape
7.42 167.60 66.20 20.16
9](https://image.slidesharecdn.com/rintroduction-121027052050-phpapp01/85/R-Language-Introduction-9-320.jpg)








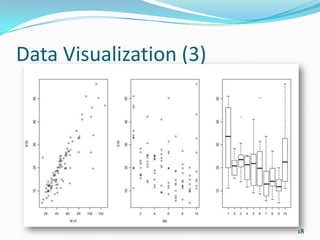
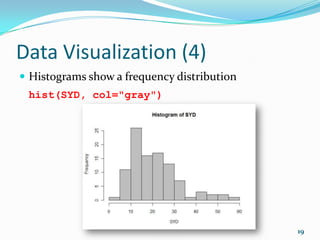
![R Basics (6)
String functions:
substr(month.name, 2, 3)
paste("*", month.name[1:4], "*", sep=" ")
x <- toupper(dna.seq)
rna.seq <- chartr("T", "U", x)
comp.seq <- chartr("ACTG", "TGAC", dna.seq)
20](https://image.slidesharecdn.com/rintroduction-121027052050-phpapp01/85/R-Language-Introduction-20-320.jpg)







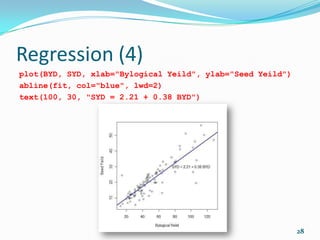

![Correlation and Regression (1)
If you want to determine the significance of a
correlation (i.e. the p value associated with the
calculated value of r) then use cor.test rather than cor.
cor(wt, mpg)
[1] -0.8676594
The value will vary from -1 to +1. A -1 indicates perfect
negative correlation, and +1 indicates perfect positive
correlation. 0 means no correlation.
30](https://image.slidesharecdn.com/rintroduction-121027052050-phpapp01/85/R-Language-Introduction-30-320.jpg)
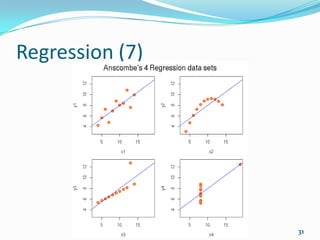






![Correlation and Regression (9)
Predict is a generic built-in function for predictions
from the results of various model fitting functions:
predict(fit, list(wt = 4.5))
[1] 13.23500
38](https://image.slidesharecdn.com/rintroduction-121027052050-phpapp01/85/R-Language-Introduction-38-320.jpg)
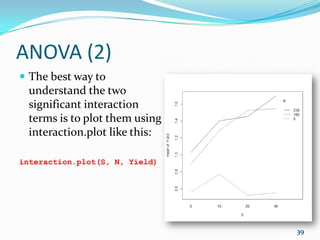

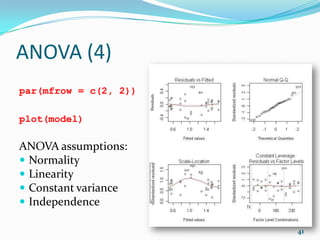
![Correlation and Regression (13)
# Bootstrap 95% CI for R-Squared
library(boot)
rsq <- function(formula, data, indices) {
fit <- lm(formula, data= data[indices,])
return(summary(fit)$r.square)
}
rs <- boot(data=mtcars, statistic=rsq, R=1000,
formula=mpg~wt+disp)
boot.ci(rs, type="bca") # try print(rs) and plot(rs)
42](https://image.slidesharecdn.com/rintroduction-121027052050-phpapp01/85/R-Language-Introduction-42-320.jpg)
![t-Test (1)
Comparing two sample means with normal errors
(Student’s t test, t.test)
t.test(a, b)
t.test(a, b, paired = TRUE)
# alternative argument options:
# "two.sided", "less", "greater"
a <- qsec[cyl == 4]
b <- qsec[cyl == 6]
c <- qsec[cyl == 8]
43](https://image.slidesharecdn.com/rintroduction-121027052050-phpapp01/85/R-Language-Introduction-43-320.jpg)







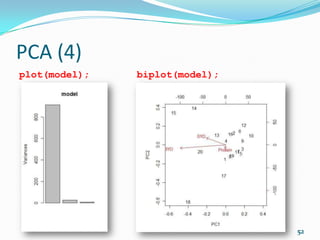






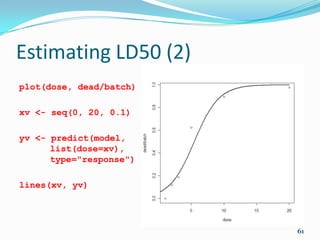


![PCA (2)
model <- prcomp(d2)
model
Standard deviations:
[1] 14.6949595 3.9627722 2.8306355 1.1593717
Rotation:
PC1 PC2 PC3 PC4
wt -0.05887539 0.05015401 -0.07513271 -0.16910728
disp -0.83186362 0.47519625 0.28005113 0.04080894
hp -0.40572567 -0.83180078 0.24611265 -0.28768795
mpeg 0.36888799 0.12190490 0.91398919 -0.09385946
qsec 0.06200759 0.25479354 -0.14134625 -0.93710373
64](https://image.slidesharecdn.com/rintroduction-121027052050-phpapp01/85/R-Language-Introduction-64-320.jpg)
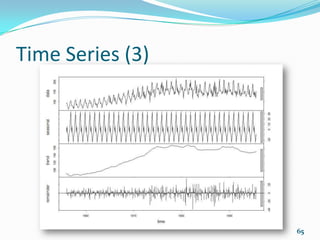

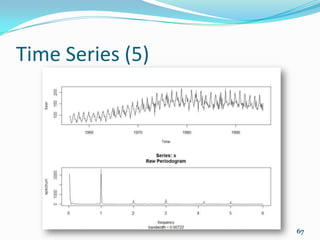





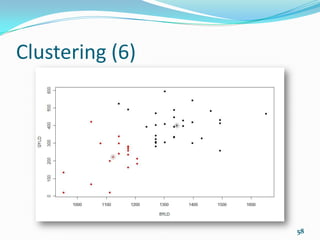
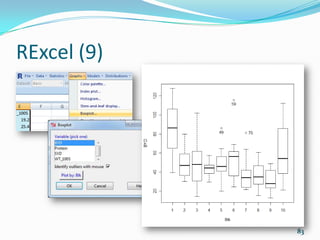
![Clustering (7)
K-means clustering with 2 clusters of sizes 18, 14
Cluster means:
disp hp
1 135.5389 98.05556
2 353.1000 209.21429
Clustering vector:
[1] 1 1 1 1 2 1 2 1 1 1 1 2 2 2 2 2 2 1 1 1 1 2 2 2 2 1 1
1 2 1 2 1
Within cluster sum of squares by cluster:
[1] 58369.27 93490.74
(between_SS / total_SS = 75.6 %)
73](https://image.slidesharecdn.com/rintroduction-121027052050-phpapp01/85/R-Language-Introduction-73-320.jpg)



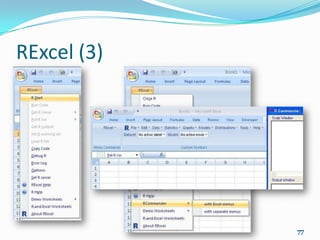
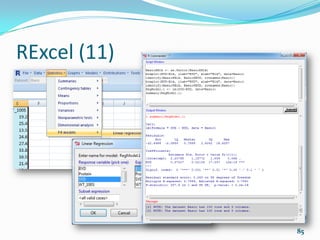
![Programming (1)
We can extend the functionality of R by writing a
function that estimates the standard error of the mean
SEM <- function(x, na.rm = FALSE) {
if (na.rm == TRUE) VAR <- x[!is.na(x)]
else VAR <- x
SD <- sd(VAR)
N <- length(VAR)
SE <- SD/sqrt(N - 1)
return(SE)
}
78](https://image.slidesharecdn.com/rintroduction-121027052050-phpapp01/85/R-Language-Introduction-78-320.jpg)
![Programming (2)
You can define your own operator of the form %any%
using any text string in place of any. The function
should be a function of two arguments.
"%p%" <- function(x,y) paste(x,y,sep=" ")
"Hi" %p% "Khaled"
[1] "Hi Khaled"
79](https://image.slidesharecdn.com/rintroduction-121027052050-phpapp01/85/R-Language-Introduction-79-320.jpg)
![Programming (3)
setwd("path/to/folder")
sink("output.txt")
cat("Intercept t Slope")
a <- fit$coefficients[[1]]
b <- fit$coefficients[[2]]
cat(paste(a, b, sep="t"))
sink()
jpeg(filename="graph.jpg", width=600, height=600)
plot(wt, mpg); abline(fit)
dev.off()
80](https://image.slidesharecdn.com/rintroduction-121027052050-phpapp01/85/R-Language-Introduction-80-320.jpg)


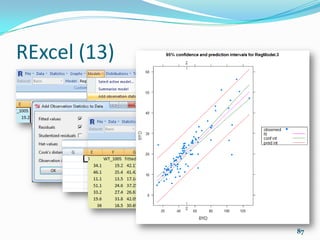
![Programming (7)
If want to evaluate the quadratic x2−2x +4 many times
so we can write a function that evaluates the function
for a specific value of x:
my.f <- function(x) { x^2 - 2*x + 4 }
my.f(3)
[1] 7
plot(my.f, -10, +10)
84](https://image.slidesharecdn.com/rintroduction-121027052050-phpapp01/85/R-Language-Introduction-84-320.jpg)
![Programming (9)
We can find the minimum of the function using:
optimize(my.f, lower = -10, upper = 10)
$minimum
[1] 1
$objective
[1] 3
which says that the minimum occurs at x=1 and at that
point the quadratic has value 3.
86](https://image.slidesharecdn.com/rintroduction-121027052050-phpapp01/85/R-Language-Introduction-86-320.jpg)



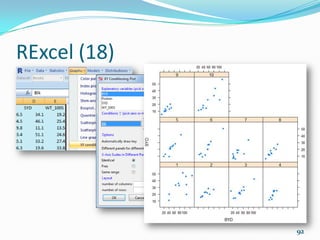




The document outlines various statistical and data analysis techniques that can be performed in R including importing data, data visualization, correlation and regression, and provides code examples for functions to conduct t-tests, ANOVA, PCA, clustering, time series analysis, and producing publication-quality output. It also reviews basic R syntax and functions for computing summary statistics, transforming data, and performing vector and matrix operations.































































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)
