Downloaded 73 times




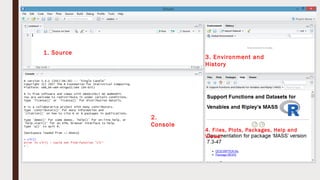












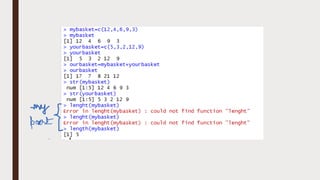




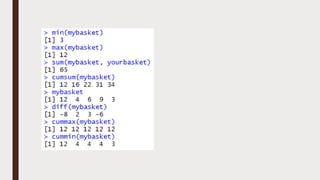



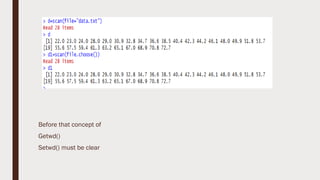
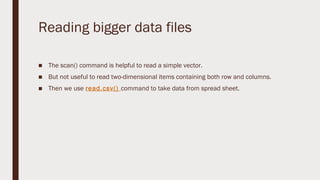
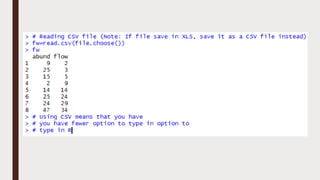


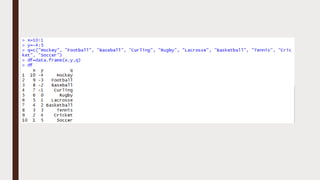
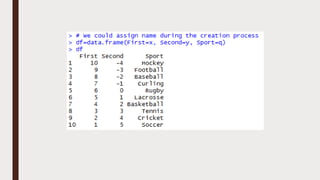

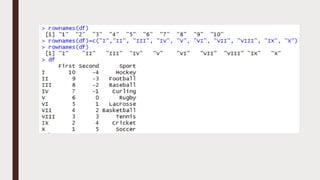





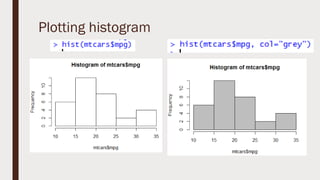
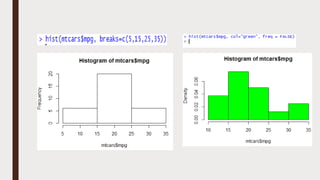


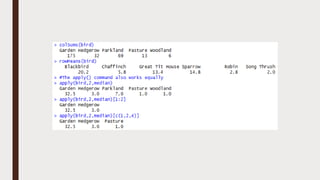




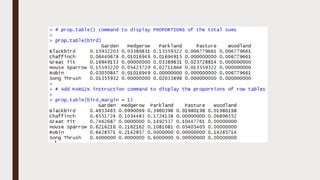
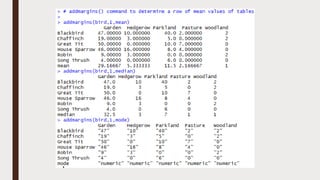


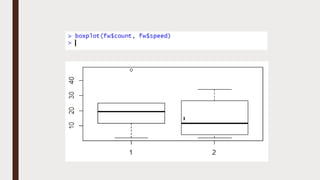











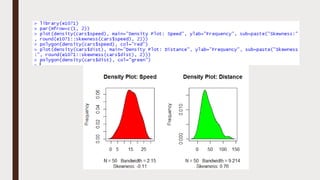
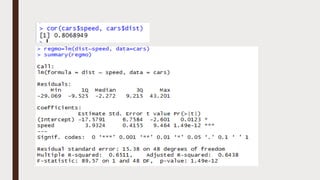








The document provides an overview of R programming, emphasizing its functionality as a statistical processing environment and a tool for data analysis. It covers R Studio's interface components, basic arithmetic operations, and the creation and manipulation of vectors and data frames. Additionally, it discusses data visualization techniques, statistical testing, and model prediction with an emphasis on the importance of splitting datasets for improving predictive accuracy.



































































