Downloaded 30 times






























![32
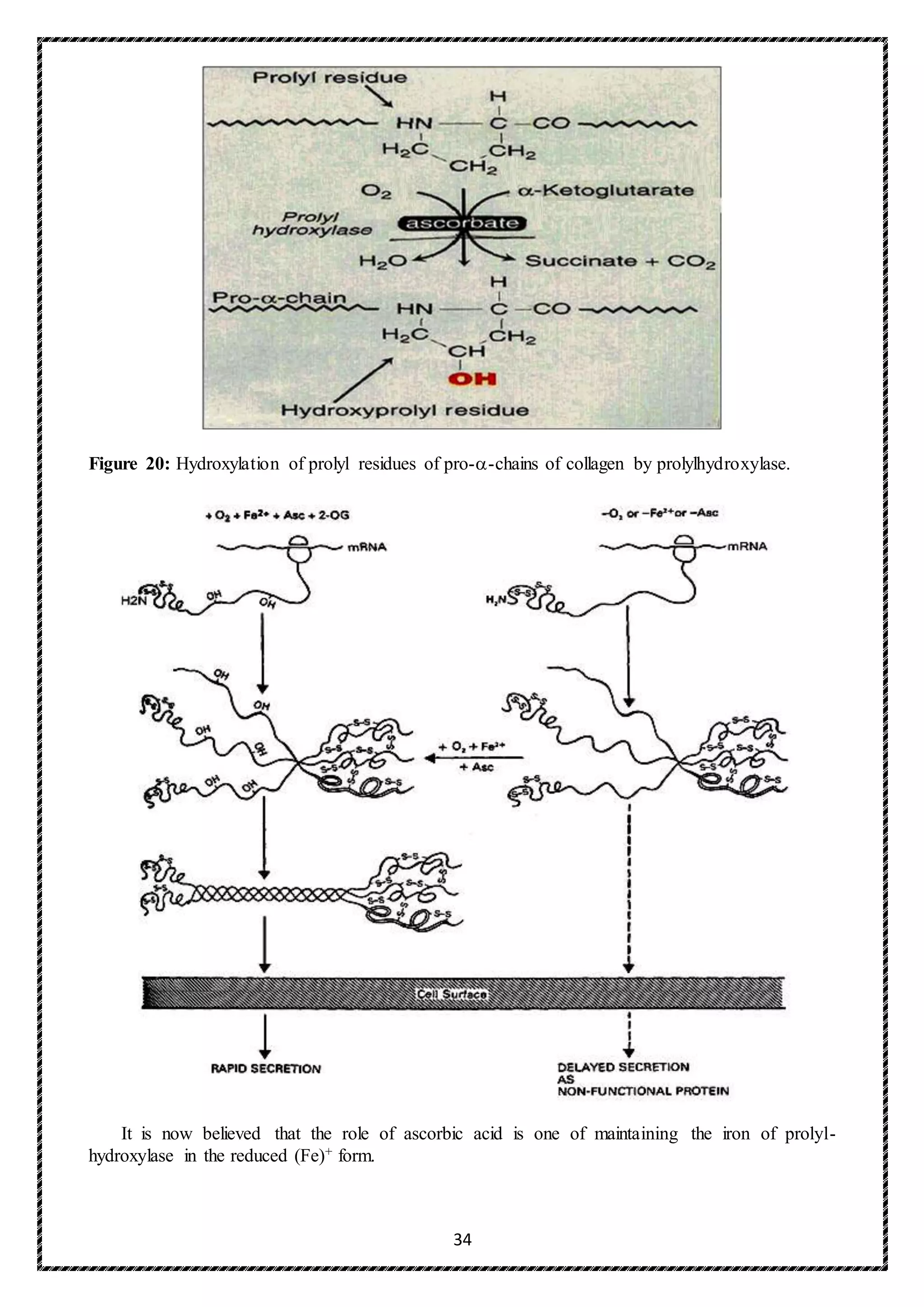
X is frequently proline and Y is often hydroxyproline or hydroxylysine (Figure). Thus, most of
the α-chain can be regarded as a polytripeptide whose sequence can be represented as (-Gly-X-
Y-)333.
2) Triple-helical structure: Unlike most globular proteins that are folded into compact structures,
collagen, a fibrous protein, has an elongated, triple-helical structure that places many of its amino
acid side chains on the surface of the triple-helical molecule.[Note: This allows bond formation
between the exposed R-groups of neighboring collagen monomers, resulting in their aggregation
into long fibers.]
3) Hydroxyproline and hydroxylysine: Collagen contains hydroxyl-proline (hyp) and
hydroxylysine (hyl), which are not present in most other proteins. These residues result from the
hydroxylation of some of the proline and lysine residues after their incorporation into polypeptide
chains (Figure). The hydroxylation is, thus, an example of posttranslational modification).
Hydroxyproline is important in stabilizing the triple-helical structure of collagen because it
maximizes interchain hydrogen bond formation. Proline and hydroxyproline together account for
about one third of the X-Y positions so that they form 25% of the total aminoacyl residues. The
high concentration of hydroxyproline is very unusual in proteins. About 90 hydroxyproline
residues are needed per chain to preserve the triple helix at body temperature; if the biosynthesis
of hydroxyproline is impaired, unstable collagen is formed in which the chains tend not to wind
round each other. Most of the hydroxyproline is 4-hydroxyproline, although a small proportion
of 3-hydroxyprolyl residues are also found in the collagen molecules. Type I collagen contains
only one or two residues of 3-hydroxyproline near the carboxyl end of the chain, but other types
of collagen may contain 10% of the total hydroxyproline as the C-3 derivative.
4) Lysyl residues are also hydroxylated and subsequently a glycosyl residue, to which a galactosyl
residue may become attached, is joined in an O-glycosidic linkage. Another, but extra-cellular
reaction undergone by some of the lysyl residues is one of oxidative deamination when the -
amino group is lost and an aldehyde group is formed. This is able to react with free amino groups
in lysyl residues and as these are usually located in other chains, the result being the type of cross-
linking illustrated in Fig.
5) Glycosylation: The hydroxyl group of the hydroxylysine residues of collagen may be
enzymatically glycosylated. Most commonly, glucose and galactose are sequentially attached to
the polypeptide chain prior to triple-helix formation.
In summary, whilst the functions of some of the side chain modifications are uncertain, it is now
appreciated that 4-hydroxyproline stabilizes the helix of the molecule and hydroxylysine is essential
for sugar attachment; the carbohydrate chain may be effective in water retention and also in cross-
link formation.](https://image.slidesharecdn.com/finalproteinchemistryforpostgraduatestudents2017-2018-171120083820/75/protein-chemistry-33-2048.jpg)


![36
Elastin:
In contrast to collagen, which forms fibers that are tough and have high tensile strength, elastin is
a connective tissue protein with rubber-like properties. Elastic fibers composed of elastin and
glycoprotein microfibrils are found in the lungs, the walls of large arteries, and elastic ligaments.
They can be stretched to several times their normal length, but recoil to their original shape when the
stretching force is relaxed.
A. Structure of elastin
Elastin is an insoluble protein polymer synthesized from a precursor, tropoelastin, which is a
linear polypeptide, composed of about 700 amino acids that are primarily small and nonpolar (for
example, glycine, alanine, and valine). Elastin is also rich in proline and lysine, but contains only a
little hydroxyproline and no hydroxylysine. Tropoelastin is secreted by the cell into the extracellular
space. There it interacts with specific glycoprotein microfibrils, such as fibrillin, which function as a
scaffold onto which tropoelastin is deposited. [Note: Mutations in the fibrillin gene are responsible
for Marfan's syndrome.] Some of the lysyl side chains of the tropoelastin polypeptides are
oxidatively deaminated by lysyl oxidase, forming allysine residues. Three of the allysyl side chains
plus one unaltered lysyl side chain from the same or neighboring polypeptides form a desmosine
cross-link (Figure). This produces elastin an extensively interconnected, rubbery network that can
stretch and bend in any direction when stressed, giving connective tissue elasticity.](https://image.slidesharecdn.com/finalproteinchemistryforpostgraduatestudents2017-2018-171120083820/75/protein-chemistry-37-2048.jpg)





![42
1. Effect of 2, 3-bisphosphoglycerate on oxygen affinity: 2, 3-Bisphosphoglycerate (2, 3-BPG)
is an important regulator of the binding of oxygen to hemoglobin. It is the most abundant organic
phosphate in the red blood cell, where its concentration is approximately that of hemoglobin. 2,3-
BPG is synthesized from an intermediate of the glycolytic pathway.
A- Binding of 2, 3-BPG to deoxyhemoglobin: 2, 3-BPG decreases the oxygen affinity of
hemoglobin by binding to deoxyhemoglobin but not to oxyhemoglobin. This preferential binding
stabilizes the taut conformation of deoxyhemoglobin. The effect of binding 2,3-BPG can be
represented schematically as:
B- Binding site of 2,3-BPG: One molecule of 2,3-BPG binds to a pocket, formed by the two β-
globin chains, in the center of the deoxyhemoglobin tetramer (Figure 25). This pocket contains
several positively charged amino acids that form ionic bonds with the negatively charged
phosphate groups of 2, 3-BPG. [Note: A mutation of one of these residues can result in
hemoglobin variants with abnormally high oxygen affinity.] 2,3-BPG is expelled on oxygenation
of the hemoglobin.
Figure 25: Synthesis of 2, 3-bisphophoglycerate.
E- Minor Hemoglobin’s:
1- Hemoglobin A1C:
Under physiologic conditions, glucose reacts nonenzymically with the N-terminal amino
groups of the B-chain of HbA to form hemoglobin A1C (Fig. 26). Hemoglobin A1C constitutes an
average of about 5% of the total hemoglobin of the erythrocyte. However, in individuals with
diabetes mellitus the amount is elevated twofold to threefold. The rate of formation of HbA1C is
proportional to the concentration of glucose in the blood. The glycosylation of Hb is not reversible.
Therefore, once formed, Hb1C persists for the life span of the erythrocyte. Thus, the total HbA1C
in a population of red blood cells reflects the average glucose concentration during the previous 6
to 10 weeks. The levels of HbA1C can be used as an index of long-term control of hyperglycemia
during the treatment of diabetes.](https://image.slidesharecdn.com/finalproteinchemistryforpostgraduatestudents2017-2018-171120083820/75/protein-chemistry-43-2048.jpg)








![51
macromolecule such as a protein.) After proteins that do not bind to the ligand are washed
through the column, the bound protein of particular interest is eluted (washed out of the column)
by a solution containing free ligand.
Proteins can be Separated and Characterized by Electrophoresis:
Another important technique for the separation of proteins is based on the migration of charged
proteins in an electric field, a process called electrophoresis. These procedures are not generally used
to purify proteins in large amounts, because simpler alternatives are usually available and
electrophoretic methods often adversely affect the structure and thus the function of proteins.
Electrophoresis is, however, especially useful as an analytical method.
Gel electrophoresis
The proteins of the sample are separated using gel electrophoresis. Separation of proteins may be
by isoelectric point (pI), molecular weight, electric charge, or a combination of these factors. The
nature of the separation depends on the treatment of the sample and the nature of the gel.
By far the most common type of gel electrophoresis employs polyacrylamide gels and buffers
loaded with sodium dodecyl sulfate (SDS). SDS-PAGE (SDS polyacrylamide gel electrophoresis)
maintains polypeptides in a denatured state once they have been treated with strong reducing agents
to remove secondary and tertiary structure (e.g. disulfide bonds [S-S] to sulfhydryl groups [SH and
SH]) and thus allows separation of proteins by their molecular weight. Sampled proteins become
covered in the negatively charged SDS and move to the positively charged electrode through the
acrylamide mesh of the gel. Smaller proteins migrate faster through this mesh and the proteins are
thus separated according to size (usually measured in kilodaltons, kDa). The concentration of
acrylamide determines the resolution of the gel - the greater the acrylamide concentration the better
the resolution of lower molecular weight proteins. The lower the acrylamide concentration was the
better the resolution of higher molecular weight proteins. Proteins travel only in one dimension along
the gel for most blots.
Samples are loaded into wells in the gel. One lane is usually reserved for a marker or ladder, a
commercially available mixture of proteins having defined molecular weights, typically stained so as
to form visible, coloured bands. When voltage is applied along the gel, proteins migrate into it at
different speeds. These different rates of advancement (different electrophoretic mobilities) separate
into bands within each lane.
The polyacrylamide gel acts as a molecular sieve, slowing the migration of proteins approximately
in proportion to their charge-to-mass ratio. The migration of a protein in a gel during electrophoresis
is therefore a function of its size and its shape.
SDS binds to most proteins in amounts roughly proportional to the molecular weight of the
protein, about one molecule of SDS for every two amino acid residues. The bound SDS contributes
a large net negative charge, rendering the intrinsic charge of the protein insignificant and conferring
on each protein a similar charge-to-mass ratio. In addition, the native conformation of a protein is
altered when SDS is bound, and most proteins assume a similar shape. Electrophoresis in the presence
of SDS therefore separates proteins almost exclusively on the basis of mass (molecular weight), with
smaller polypeptides migrating more rapidly. After electrophoresis, the proteins are visualized by](https://image.slidesharecdn.com/finalproteinchemistryforpostgraduatestudents2017-2018-171120083820/75/protein-chemistry-52-2048.jpg)





![57
Metabolic Defects in Amino Acid Metabolism
Inborn errors of metabolism are commonly caused by mutant genes that generally result in
abnormal proteins, most often enzymes. The inherited defects may be expressed as a total loss of
enzyme activity or, more frequently, as a partial deficiency in catalytic activity. Without treatment,
the inherited defects of amino acid metabolism almost invariably result in mental retardation or other
developmental abnormalities as a result of harmful accumulation of metabolites. Although more than
50 of these disorders have been described, many are rare, occurring in less than 1 per 250,000 in most
populations (Figure 34). Collectively, however, they constitute a very significant portion of pediatric
genetic diseases (Figure 35). Phenylketonuria is the most important disease of amino acid metabolism
because it is relatively common and responds to dietary treatment.
Figure 34: Incidence of inherited diseases of amino acid metabolism. [Note: Cystinuria is the most
common genetic error of amino acid transport.]](https://image.slidesharecdn.com/finalproteinchemistryforpostgraduatestudents2017-2018-171120083820/75/protein-chemistry-58-2048.jpg)


![60
Figure 37: Biosynthetic reactions involving amino acids and tetrahydrobiopterin.
1. Characteristics of classic PKU:
a) Elevated phenylalanine: Phenylalanine is present in elevated concentrations in tissues,
plasma, and urine. Phenyllactate, phenylacetate, and phenylpyruvate, which are not normally
produced in significant amounts in the presence of functional phenylalanine hydroxylase,
are also elevated in PKU (Figure 37). These metabolites give urine a characteristic musty
(“mousey”) odor. [Note: The disease acquired its name from the presence of a phenylketone
(now known to be phenylpyruvate) in the urine.]
b) CNS symptoms: Mental retardation, failure to walk or talk, seizures, hyperactivity, tremor,
microcephaly, and failure to grow are characteristic findings in PKU. The patient with
untreated PKU typically shows symptoms of mental retardation by the age of one year, and
rarely achieves an IQ greater than 50 (Figure 25). [Note: These clinical manifestations are
now rarely seen as a result of neonatal screening programs.]
c) Hypopigmentation: Patients with phenylketonuria often show a deficiency of pigmentation
(fair hair, light skin color, and blue eyes). The hydroxylation of tyrosine by tyrosinase, which
is the first step in the formation of the pigment melanin, is competitively inhibited by the
high levels of phenylalanine present in PKU.](https://image.slidesharecdn.com/finalproteinchemistryforpostgraduatestudents2017-2018-171120083820/75/protein-chemistry-61-2048.jpg)

![62
2. Neonatal screening and diagnosis of PKU: Early diagnosis of phenylketonuria is important
because the disease is treatable by dietary means. Because of the lack of neonatal symptoms,
laboratory testing for elevated blood levels of phenylalanine is mandatory for detection.
However, the infant with PKU frequently has normal blood levels of phenylalanine at birth
because the mother clears increased blood phenylalanine in her affected fetus through the
placenta. Normal levels of phenylalanine may persist until the newborn is exposed to 24 to 48
hours of protein feeding. Thus, screening tests are typically done after this time to avoid false
negatives. For newborns with a positive screening test, diagnosis is confirmed through
quantitative determination of phenylalanine levels.
3. Antenatal diagnosis of PKU: Classic PKU is a family of diseases caused by any of 400 or more
different mutations in the gene that codes for phenylalanine hydroxylase (PAH). The frequency
of any given mutation varies among populations, and the disease is often doubly heterozygous,
that is, the PAH gene has a different mutation in each allele. Despite this complexity, prenatal
diagnosis is possible.
4. Treatment of PKU: Most natural protein contains phenylalanine, and it is impossible to satisfy
the body's protein requirement when ingesting a normal diet without exceeding the phenylalanine
limit. Therefore, in PKU, blood phenylalanine is maintained close to the normal range by feeding
synthetic amino acid preparations low in phenylalanine, supplemented with some natural foods
(such as fruits, vegetables, and certain cereals) selected for their low phenylalanine content. The
amount is adjusted according to the tolerance of the individual as measured by blood
phenylalanine levels. The earlier treatment is started, the more completely neurologic damage
can be prevented. [Note: Treatment must begin during the first seven to ten days of life to prevent
mental retardation.] Because phenylalanine is an essential amino acid, overzealous treatment that
results in blood phenylalanine levels below normal should be avoided because this can lead to
poor growth and neurologic symptoms. In patients with PKU, tyrosine cannot be synthesized
from phenylalanine and, therefore, it becomes an essential amino acid that must be supplied in
the diet. Discontinuance of the phenylalanine-restricted diet before eight years of age is
associated with poor performance on IQ tests. Adult PKU patients show deterioration of IQ
scores after discontinuation of the diet (Figure 39). Lifelong restriction of dietary phenylalanine
is, therefore, recommended. [Note: Individuals with PKU are advised to avoid aspartame, an
artificial sweetener that contains phenylalanine.]
5. Maternal PKU: When women with PKU who are not on a low- phenylalanine diet become
pregnant, the offspring are affected with “maternal PKU syndrome.” High blood phenylalanine
levels in the mother cause microcephaly, mental retardation, and congenital heart abnormalities
in the fetus. Some of these developmental responses to high phenylalanine occur during the first
months of pregnancy. Thus, dietary control of blood phenylalanine must begin prior to
conception, and must be maintained throughout the pregnancy.](https://image.slidesharecdn.com/finalproteinchemistryforpostgraduatestudents2017-2018-171120083820/75/protein-chemistry-63-2048.jpg)
![63
Figure 39: Changes in IQ scores after discontinuation of low-phenylalanine diet in patients with
phenylketonuria.
B. Maple syrup urine disease:
Maple syrup urine disease (MSUD) is a rare (1:185,000), autosomal recessive disorder in which
there is a partial or complete deficiency in branched-chain α-keto acid dehydrogenase, an enzyme
complex that decarboxylates leucine, isoleucine, and valine. These amino acids and their
corresponding α-keto acids accumulate in the blood, causing a toxic effect that interferes with brain
functions. The disease is characterized by feeding problems, vomiting, dehydration, severe metabolic
acidosis, and a characteristic maple syrup odor to the urine. If untreated, the disease leads to mental
retardation, physical disabilities, and even death.
1) Classification: The term “maple syrup urine disease” includes a classic type and several variant
forms of the disorder. The classic from is the most common type of MSUD. Leukocytes or cultured
skin fibroblasts from these patients show little or no branched-chain α-keto acid dehydrogenase
activity. Infants with classic MSUD show symptoms within the first several days of life. If not
diagnosed and treated, classic MSUD is lethal in the first weeks of life. Patients with intermediate
forms have a higher level of enzyme activity (approximately 3–15% of normal). The symptoms
are milder and show an onset from infancy to adulthood. Patients with the rare thiamine-dependent
variant of MSUD achieve increased activity of branched-chain α-keto acid dehydrogenase if given
large doses of this vitamin.
2) Screening and diagnosis: As with PKU, antenatal diagnosis and neonatal screening are available,
and most affected individuals are compound heterozygotes.
3) Treatment: The disease is treated with a synthetic formula that contains limited amounts of
leucine, isoleucine, and valine, sufficient to provide the branched-chain amino acids necessary for
normal growth and development without producing toxic levels. Early diagnosis and lifelong
dietary treatment is essential if the child with MSUD is to develop normally. [Note: Branched-
chain amino acids are an important energy source in times of metabolic need, and individuals with
MSUD are at risk of decompensation during periods of increased protein catabolism.]
C. Albinism:
Albinism refers to a group of conditions in which a defect in tyrosine metabolism results in a
deficiency in the production of melanin. These defects result in the partial or full absence of pigment
from the skin, hair, and eyes. Albinism appears in different forms, and it may be inherited by one of
several modes: autosomal recessive (primary mode), autosomal dominant, or X-linked. Complete
albinism (also called tyrosinase-negative oculocutaneous albinism) results from a deficiency of
tyrosinase activity, causing a total absence of pigment from the hair, eyes, and skin. It is the most](https://image.slidesharecdn.com/finalproteinchemistryforpostgraduatestudents2017-2018-171120083820/75/protein-chemistry-64-2048.jpg)

![65
E. Alkaptonuria
Alkaptonuria is a rare metabolic disease involving a deficiency in homogentisic acid oxidase,
resulting in the accumulation of homogentisic acid. [Note: This reaction occurs in the degradative
pathway of tyrosine.] The illness has three characteristic symptoms: homogentisic aciduria (the
patient's urine contains elevated levels of homogentisic acid, which is oxidized to a dark pigment on
standing, Figure A), large joint arthritis, and black ochronotic pigmentation of cartilage and
collagenous tissue (Figure B). Patients with Alkaptonuria are usually asymptomatic until about age
40. Dark staining of the diapers sometimes can indicate the disease in infants, but usually no
symptoms are present until later in life. Diets low in protein, especially in phenylalanine and tyrosine,
help reduce the levels of homogentisic acid, and decrease the amount of pigment deposited in body
tissues. Although Alkaptonuria is not life-threatening, the associated arthritis may be severely
crippling.
Further readings:
Lippincott (Review Illustrated Biochemistry).
Lehninger's (Principles of Biochemistry).
Harper's (Illustrated Biochemistry).
Basic Concepts in Biochemistry.](https://image.slidesharecdn.com/finalproteinchemistryforpostgraduatestudents2017-2018-171120083820/75/protein-chemistry-66-2048.jpg)

This document provides an overview of biochemistry, including its definition, objectives, and relationships to other life sciences. It discusses that proteins are the most abundant biomolecules in cells, consisting of linear polymers of 20 amino acids. The major techniques used in biochemistry to study cellular components and reactions are also summarized.














































![Lesson-Presentation-introduction_to_biochemistry [Autosaved].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/lesson-presentation-introductiontobiochemistryautosaved-230131133523-5098d4aa-thumbnail.jpg?width=640&height=640&fit=bounds)







































