- Propensity score matching (PSM) and weighting methods can be used to estimate treatment effects when selection into a treatment is based on observable characteristics.
- PSM involves matching treated units to untreated units with similar propensity scores, which is the predicted probability of receiving treatment based on observables. Weighting assigns weights inversely proportional to the probability of receiving the actual treatment.
- Both methods rely on the assumption that conditioning on observables eliminates selection bias, but there may still be bias from unobservables. Sensitivity analysis is used to check the robustness of results.
Introduction of PSM as a method to find non-participant comparison groups. Highlights assumptions of traditional regression and the advantages of PSM.
Discusses the core concept of propensity scores, their calculation, and the required characteristics for effective matching between treatment and control groups.
Outlines the importance of a common support region and critical assumptions to mitigate bias in PSM based on observable characteristics.
Identifies which variables influence program placement and outlines practical applications of PSM using predicted probabilities.
Describes different matching methods like one-to-one matching and kernel matching, highlighting their respective functionalities and implications.
Explains how to estimate treatment impacts using matched samples and the significance of propensity score specification for robust results.
Discusses testing matched samples for balance in covariates, how to estimate correct standard errors, and sensitivity analyses of results.
Contrast between PSM and social experiments, noting the concerns regarding selection bias and overall methodology differences.
Explains propensity score weighting methods, including inverse probability weighting and its application in real-world settings such as poverty reduction projects.
Propensity Score
Matching Methods
Day1, Lecture 3
By Ragui Assaad
Training on Applied Micro-Econometrics and
Public Policy Evaluation
July 25-27, 2016
Economic Research Forum
2.
Type I Methods
•Assumption:
• Conditional exogeneity of placement
• i.e. placement into program does not depend on unobservables
affecting outcome of interest
• In that case Ti is not correlated with error term and is therefore not
endogenous
• Can simply use regression to get at ATE
• This is a fairly strong assumption that is unlikely to be met in most
cases.
3.
Multiple Regression Approach
•Assumes conditional exogeneity of placement (selection
on observables only)
• Run a multiple regression explaining the outcome (Y) as a
function of the Treatment (T) and other controls (X). The
coefficient of T is the average treatment effect.
• Can Differentiate effect of treatment across different
groups by interacting X and T
iiii XTY
iiiiii XTXTY
4.
Problems with RegressionApproach
• Besides the strong assumption of conditional exogeneity
of placement, linear regression makes other strong
parametric assumptions relating to how treatment and
outcome are related conditional on observables.
• We must assume a particular functional form, like linear,
log-linear, etc.
• We would prefer not to make such assumptions and use a
non-parametric approach.
• Regular regression also gives equal weight to all
comparison observations, irrespective of how likely they
are to participate in the program
5.
Introduction to PropensityScore
Matching (PSM)
• Method is used to find a comparison group of non-
participants with similar pre-intervention characteristics as
the treatment group
• Like regression, method assumes conditional exogeneity
of placement or “selection on observables only”
• Main Question: Which characteristics does one use and
what weight to put on each of them?
• Propensity score matching is a way of answering this
question
6.
What are theadvantages of PSM over
Regression?
• PSM does not assume a particular functional form for the
way the X’s affect Y and the way T affects Y
• It is referred to as a non-parametric method
• Regression uses the whole dataset to compare treatment
and controls, even if treatment and control observations
are very different in terms of the observables
• PSM only compares treatment and control observations
that are similar (along observable characteristics)
• We only keep control observations that "close" to the treatment
observations we want to match
7.
Basic Theorem ofPSM
• Rosenbaum and Rubin (1983) showed that instead of
having to match on a multitude of dimensions in a vector
of observable characteristics Z, it is only necessary to
match on a single dimension P(Z), which is the propensity
score.
• A treatment and control observation that are "close" in the
propensity score space, will also be "close" along the
various elements making up Z.
8.
What is apropensity score?
• A propensity score is given by:
• P(Z)=Pr(T=1 | Z) where Z is a vector of pre-exposure
characteristics
– Z can include the pre-treatment value of the outcome
– Treatment units are matched to comparison or control units with
similar values of P(Z)
• Impact estimates from Propensity Score Matching (PSM)
will depend on the variables that go into the equation
used to estimate propensity score and also on the
specification of that equation
• Can be estimated using probit or logit
9.
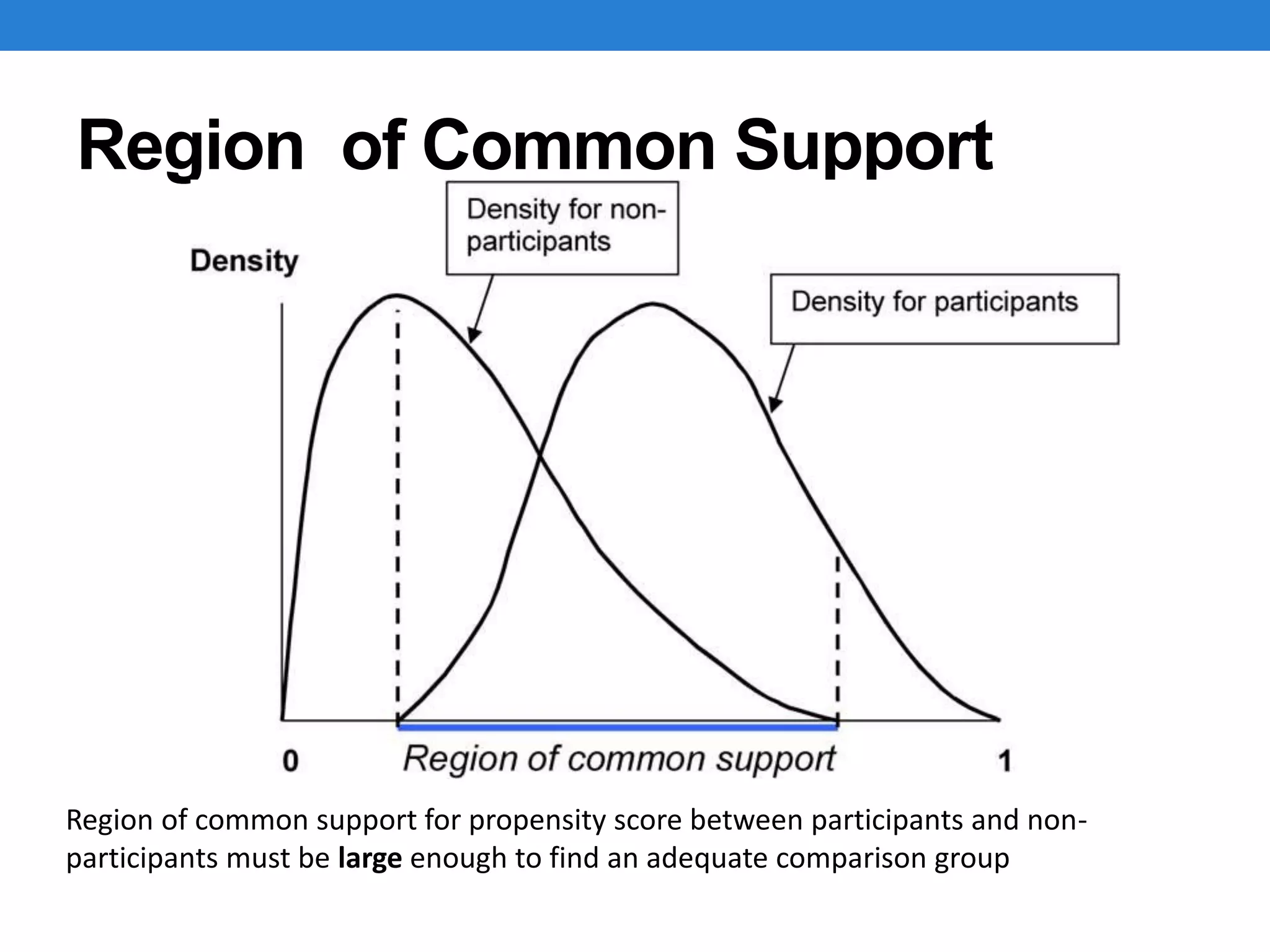
Region of CommonSupport
Region of common support for propensity score between participants and non-
participants must be large enough to find an adequate comparison group
10.
Assumption Underlying PSMMethods
• Eliminating selection based on observables will reduce
overall bias
• This is the case if and only if the bias based on
unobservables goes in the same direction as bias based
on observables
• If they go in opposite direction, eliminating bias based on
observables will increase overall bias
• Possible in theory, but not likely in practice
11.
What variables goin Z?
• Any variable that can affect program placement, including
the pre-intervention level of the outcome variable
• Can be obtained through interviews
• If one cannot find good observable variables to explain
who participates and who doesn’t, we will do a poor job
eliminating selection bias
12.
PSM in practice
•Use predicted probabilities of participation from a probit or
logit model
• Matching is done based on the distance between each
treatment observation and comparison observations in its
neighborhood, using the propensity score as a metric of
distance.
• The outcome of each treatment is compared to that of its
matched comparison observations to detect whether the
treatment has a statistically significant effect
13.
Matching Methods
• Thereare many ways to undertake the matching
• Simplest method:
• One-to-one matching
• Match each treatment observation with “nearest” comparison observation
• Can impose a maximum distance, through a “caliper”
• Subject to potential outliers
• Addressing ties in propensity scores
• Nearest n-neighbors
• Uses the average of the nearest n-neighbors among comparison observations
• Can also impose a caliper
14.
Matching Method
• Morecomplicated but probably sounder methods
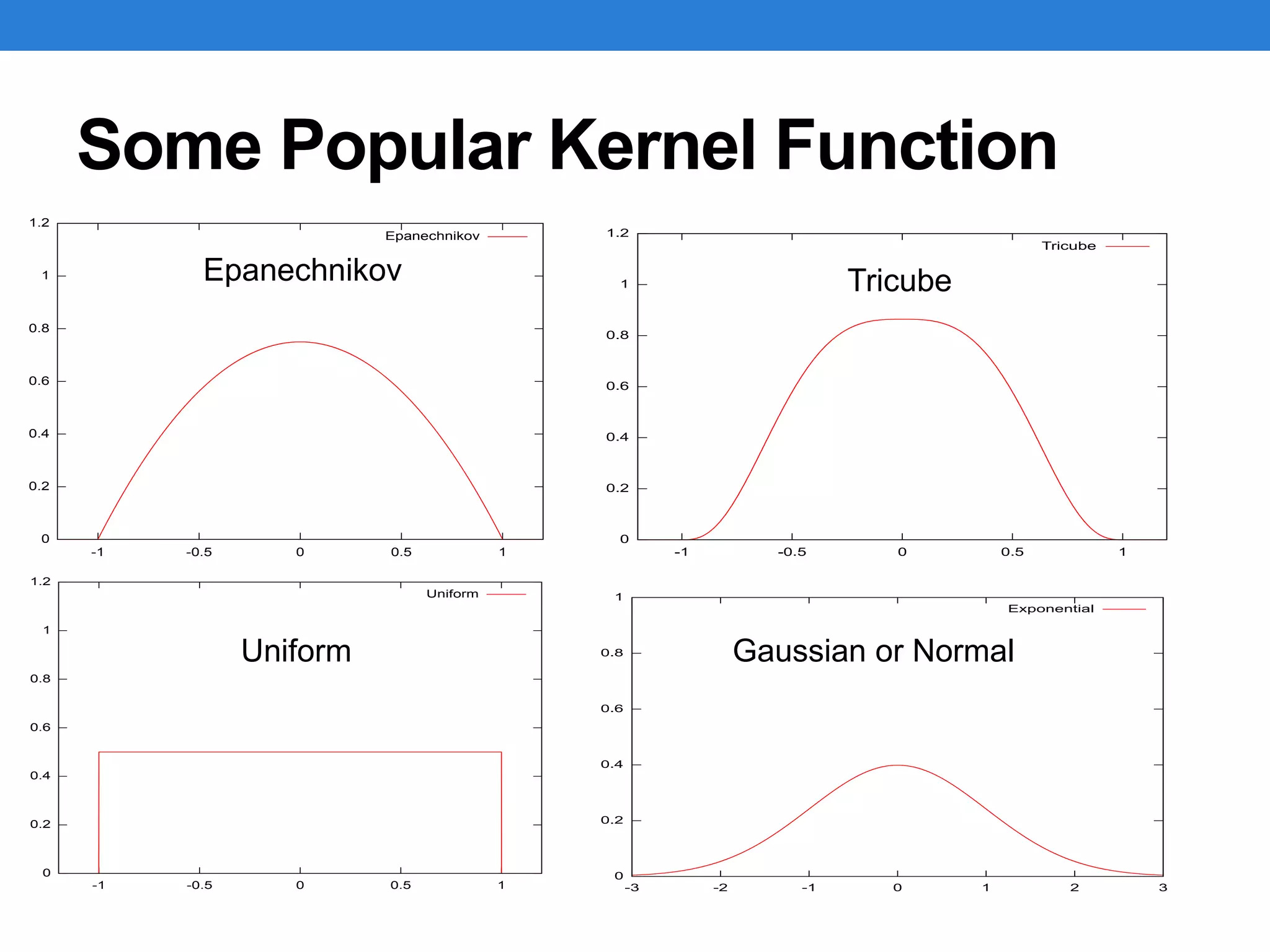
• Kernel matching
• Kernel functions are symmetric functions around a particular point that
can be used to provide a weight that is inversely proportional to the
horizontal distance from that point
• The weight is the vertical height at each distance from the central point
• The weight typically goes to zero after a certain distance has been
reached (usually referred to as bandwidth)
PSM Estimator
• Thesimplest measure of the impact of program is
measured by:
Where Yj
C is the value for a single “nearest neighbor” from
the comparison group.
• If we are using multiple “nearest neighbors” we take a
weighted mean of all the “nearest neighbors” to form Yj
C
with the weights provided by the kernel function used
(generally declining with distance from observation j)
(1/ NT
) (Yj
T
-Yj
C
)
j=1
NT
å
17.
Notes on EstimatingPropensity Score
• Although effect of treatment on outcome is non-
parametric, estimation of propensity score itself
depends on a parametric specification (usually
logit or probit)
• Specification of propensity score equation will
affect quality of matching and, therefore, final
result
• Must try out multiple specifications with lots of
interaction terms between the observable
characteristics to get a good fit
18.
Testing how goodthe match is
• Need to test the extent to which observable
characteristics are balanced in the matched sample, using
a t-test of of the difference in means of the covariates
across matched samples.
• None of the test should be statistically significant
• Should examine the effect of the matching method on the
area of common support
• The closer we try to make the match, the more likely that some
treatment observation won’t find matches, which reduce the
efficiency of the model
19.
Standard Errors
• Becausepropensity scores are predicted, analytical
standard errors obtained from a t-test of the outcome for
matched treatment and comparison observations are not
correct
• We typically use bootstrapping to estimate the correct
standard errors.
20.
Sensitivity Analysis
• Thereare many modeling decisions that can affect the
results, including
• Specification of propensity score equation
• What variables to include
• How many interactions to include and at what level
• Matching method and caliper or bandwidth to use
• Must test sensitivity of results to these decisions.
• If results are not robust to these changes, this should raise a
question mark about their reliability
21.
PSM compared toSocial Experiements
• In social experiments PS= constant.
– Everyone has same probability of participating.
• PSM tries to match treatment and control groups based
on them having an equal probability of participation (using
the probability predicted from observables)
• But probability of participation can also be affected by
unobservables raising concerns about remaining selection
bias in PSM methods
Motivation for propensityscore
weighting
• Propensity score methods are used to remove the effects
of observable confounders when estimating the effect of a
treatment on an outcome
• Have been discussing matching methods
• Stratification, nearest neighbor, etc.
• Propensity scores can also be used to weight
observations (like a sample weight)
• Specifically use inverse probability of treatment weighting (IPTW)
• This approach can be used in contexts where models are non-linear
• Example: Propensity score weights in survival analysis (Austin, 2011)
23
24.
Creating propensity scoreweights
• Same creation of propensity scores as for matching
• P(Z)=Pr(Ti=1 | Zi) where Z is a vector of pre-exposure
characteristics
• Predict probabilities of participation using logit or probit:
• Use propensity scores to create weights
• Weights (wi) are the inverse of the probability of receiving the
treatment (or non-treatment) that the subject actually received
• High weights for those who were unlikely to receive treatment but
did and those who were likely to receive treatment but did not
24
ˆP
wi =
Ti
ˆPi
+
1-Ti
1- ˆPi
If treated wi =
1
ˆPi
If control wi =
1
1- ˆPi
25.
Estimates of treatmenteffects
• There are a number of ways to use IPTW directly
to estimate treatment effects
• Can estimate average treatment effect (ATE) as:
• Average treatment on the treated (ATT) and
average treatment on the untreated (controls,
ATC) use different weights:
25
ATE =
1
n
TiYi
ˆPi1
n
å -
(1-Ti )Yi
(1- ˆPi )1
n
å
wi,ATT = Ti +
ˆPi (1-Ti )
1- ˆPi
wi,ATC =
Ti (1- ˆPi )
ˆPi
+(1-Ti )
26.
Incorporating weights intomodels
• Regression models can be weighted by the inverse
probability of treatment to estimate the causal effects of
treatment
• Use like a sample weight
• Need to account for weighted nature of synthetic sample
(use robust estimation) when using IPTW
26
27.
Checking weights
• Whenweights are applied to treatment and control
groups, they should then have statistically
indistinguishable group means
• Weights may be very inaccurate/unstable for subjects with
a very low probability of receive the treatment status they
received
• Very unlikely to get treatment and did
• Very likely to get treatment and did not
• Can stabilize weights by multiplying weights by mean
probability of treatment received (T or C) propensity score
• Can also trim (use region of common support)
27
28.
Example of propensityscore weighting
• Southwest China Poverty Reduction Project ran from
1995 to 2005
• Surveys in 1996 and 2000 of 2,000 households in
targeted and non-targeted villages
• Follow-up in 2004/5
• Selection might drive treatment effect estimates if initial
differences in samples were large
• Propensity score weighting in regression models was
used as part of estimating program effects
• Impact evaluation of Chen, Mu, and Ravallion (2008)
found impacts on income, consumption, and education
diminished by 2004/5
28