Downloaded 71 times








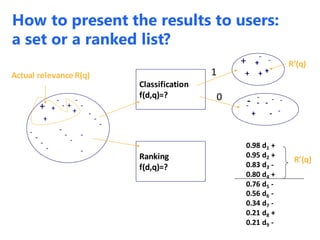

















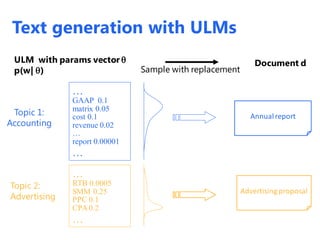
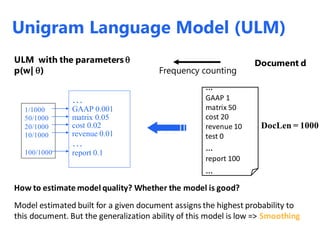









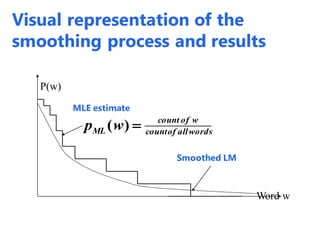



















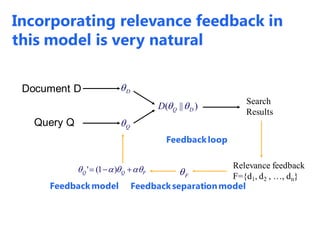






The document discusses statistical language models for information retrieval (IR), covering their historical development and various ranking models including probabilistic approaches. It details methodologies for filtering and ranking documents based on query relevance using vector space models, and emphasizes the evolution of models from classical to advanced statistical methods. Additionally, it examines the concept of text similarity, the use of machine learning in ranking, and evaluates the performance of unigram language models in IR contexts.
































































