Downloaded 118 times















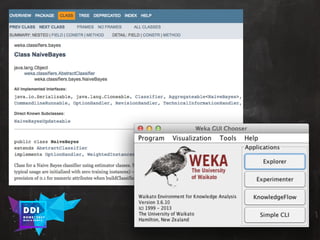









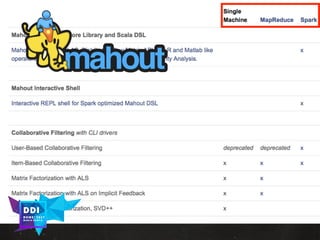
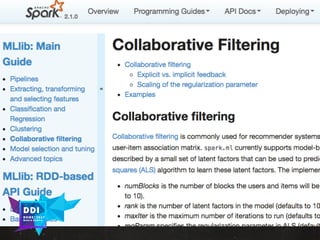
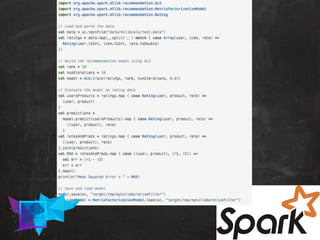






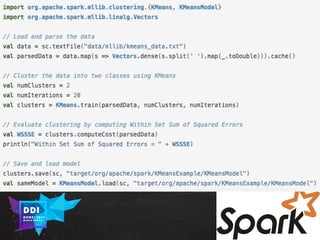









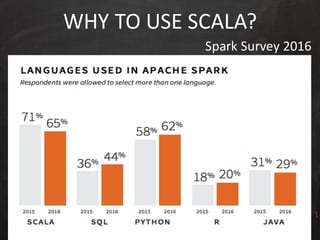



The document discusses data-driven innovation and machine learning applications, featuring insights from speaker Mario Cartia at the 2017 Open Summit in Rome. It covers various topics, including supervised and unsupervised learning techniques, the use of algorithms like naive Bayes classifiers for text categorization, and the significance of deep learning in fields such as computer vision and natural language processing. Additionally, it touches on the importance of big data technologies like Apache Hadoop and Spark in enhancing machine learning capabilities.























































































