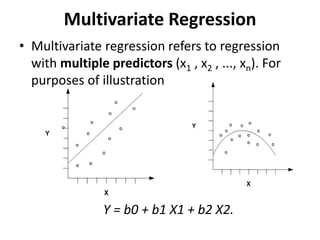
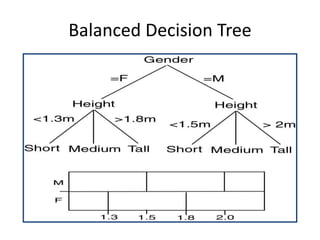
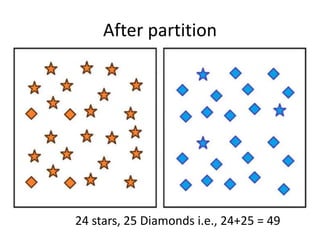
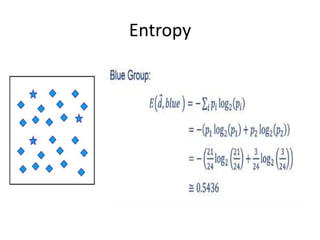
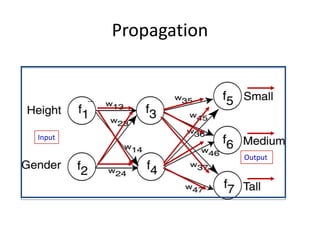
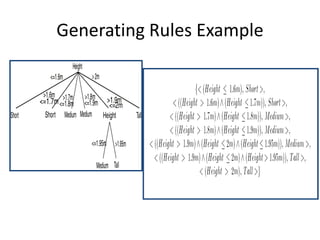
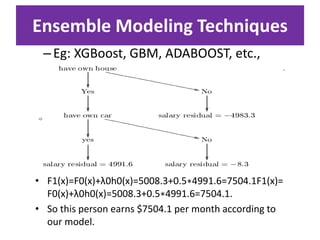
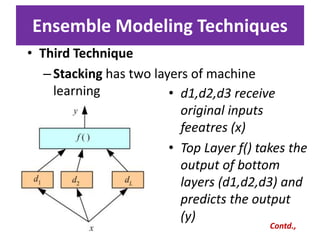
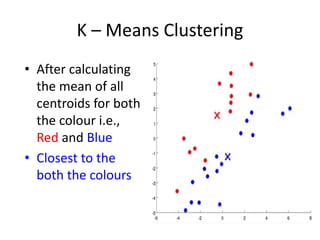
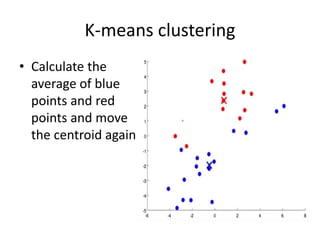
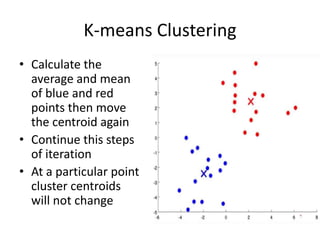
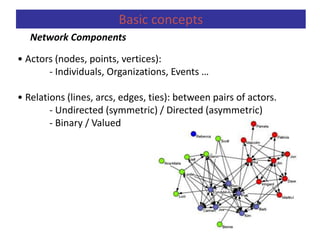
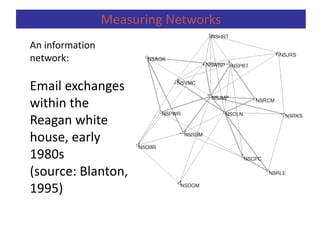
Predictive analytics uses data mining, statistical modeling and machine learning techniques to extract insights from existing data and use them to predict unknown future events. It involves identifying relationships between variables in historical data and applying patterns to unknowns. Predictive analytics is more sophisticated than analytics which has a retrospective focus on understanding trends, while predictive analytics focuses on gaining insights for decision making. Common predictive analytics techniques include regression, classification, time series forecasting, association rule mining and clustering. Ensemble methods like bagging, boosting and stacking combine multiple predictive models to improve performance.



























































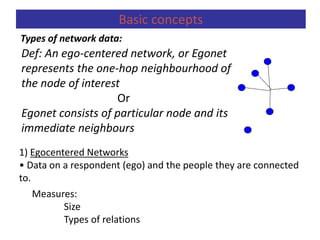


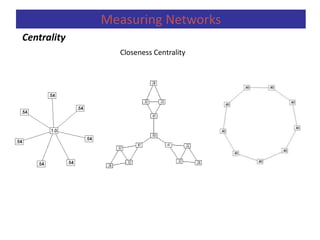
![A second measure is closeness centrality. An actor
is considered important if he/she is relatively close to all
other actors.
Closeness is based on the inverse of the
distance of each actor to every other actor in the
network.
Closeness Centrality:
Relative Closeness Centrality
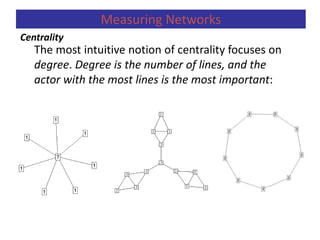
Centrality
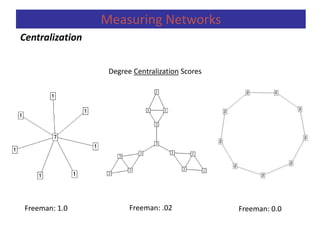
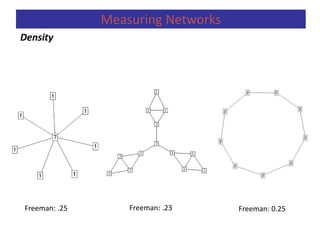
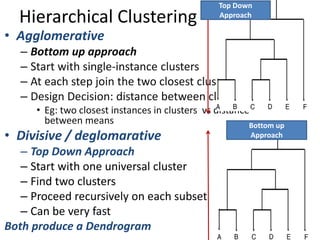
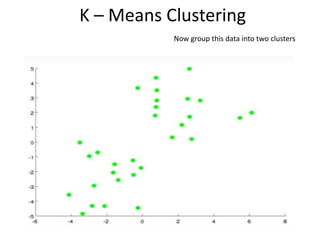
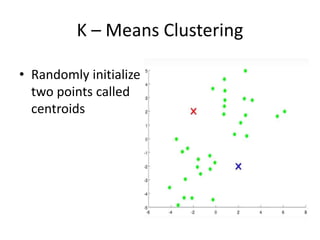
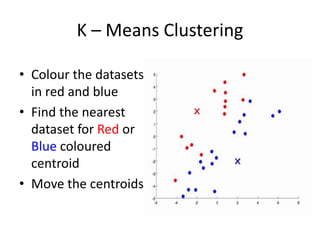
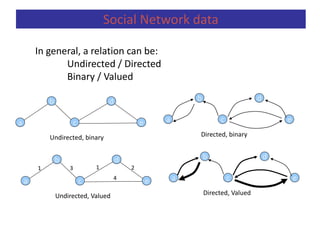
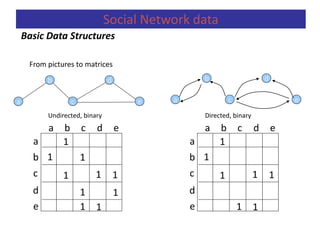
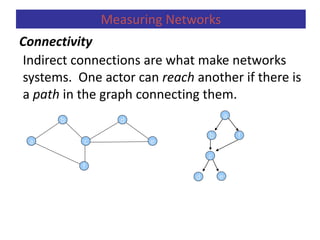
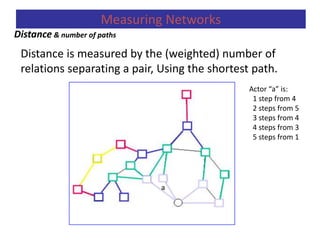
Measuring Networks
1
1
)],([)(
ki
n
i
kC ppdPC
),(
1
1
),(
)('
1
1
1
ki
n
i
ki
n
i
kC
ppd
n
n
ppd
PC
](https://image.slidesharecdn.com/predictiveanalytics-191125140618/85/Predictive-analytics-95-320.jpg)
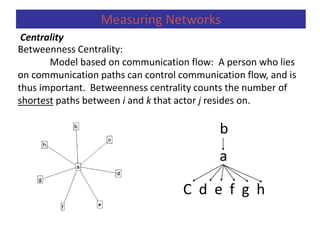
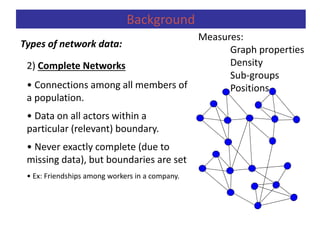
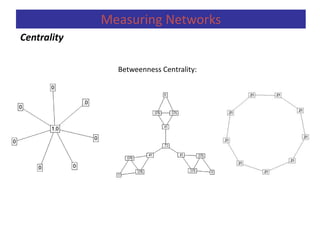
![Centrality
Measuring Networks
Betweenness centrality can be defined in terms of probability (1/gij),
CB(pk) = iij(pk) = =
gij = number of geodesics that bond actors pi and pj.
gij(pk)= number of geodesics which bond pi and pj and content pk.
iij(pk) = probability that actor pk is in a geodesic randomly chosen among the
ones which join pi and pj.
Betweenness centrality is the sum of these probabilities (Freeman, 1979).
)(*
g
1
ij
kij pg
ij
kij
g
)(pg
Normalizad: C’B(pk) = CB(pk) / [(n-1)(n-2)/2]](https://image.slidesharecdn.com/predictiveanalytics-191125140618/85/Predictive-analytics-98-320.jpg)
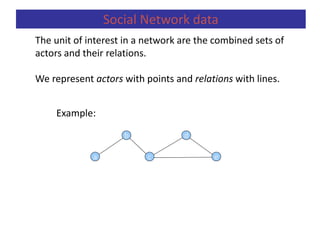
![If we want to measure the degree to which the graph as a whole is centralized, we look
at the dispersion of centrality:
Freeman’s general formula for centralization (which ranges from 0 to 1):
)]2)(1[(
)()(1
*
nn
pCpC
C
n
i iDD
D
Centralization
Measuring Networks](https://image.slidesharecdn.com/predictiveanalytics-191125140618/85/Predictive-analytics-100-320.jpg)