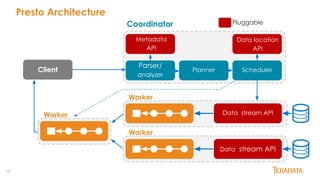
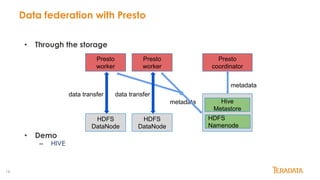
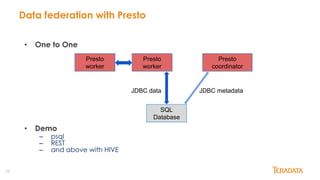
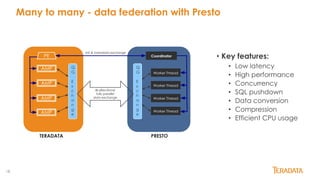
Presto is an open-source, distributed SQL query engine designed for performance and scalability, initially developed by Facebook. It supports data federation from multiple sources, allowing for complex queries across different databases with features like ANSI SQL support, various connectors, and in-memory processing. This document outlines its architecture, key features, and user adoption by companies like Facebook, Netflix, and Uber.









![10
[ WITH with_query [, ...] ]
SELECT [ ALL | DISTINCT ] select_expr [, ...]
[ FROM table1 [[ INNER | OUTER ] JOIN table2 ON (…)]
[ WHERE condition ]
[ GROUP BY expression [, ...] ]
[ HAVING condition]
[ UNION [ ALL | DISTINCT ] select ]
[ ORDER BY expression [ ASC | DESC ] [, ...] ]
[ LIMIT [ count | ALL ] ]
In addition:
• Windowing functions
• UNNEST, TABLESAMPLE
• ROLLUP, CUBE, GROUPING SETS
• UNION, EXCEPT, INTERSECT
• Subqueries (EXISTS, IN)
ANSI SQL Support](https://image.slidesharecdn.com/presto-sqlonanything-170216100507/85/Presto-SQL-on-anything-10-320.jpg)