Downloaded 42 times








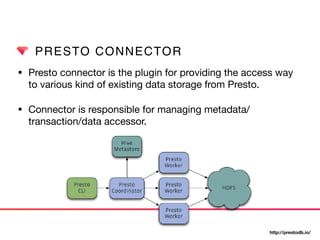



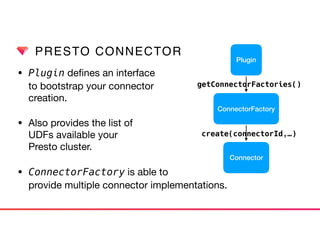
![PRESTO CONNECTOR
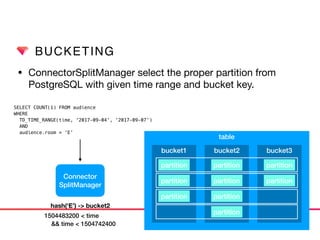
• Connector provides classes to manage metadata, storage
accessor and table access control.
• ConnectorSplitManager create
data source metadata to be
distributed multiple worker
node.
• ConnectorPage
[Source|Sink]Provider
is provided to split
operator. Connector
Connector
Metadata
Connector
SplitManager
Connector
PageSource
Provider
Connector
PageSink
Provider
Connector
Access
Control](https://image.slidesharecdn.com/optimizingprestoconnectoroncloudstorage-170907023958/85/Optimizing-Presto-Connector-on-Cloud-Storage-15-320.jpg)
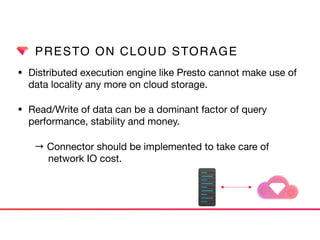




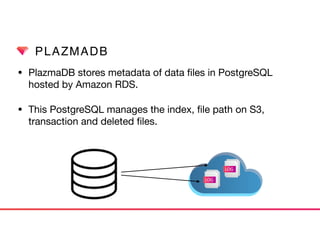



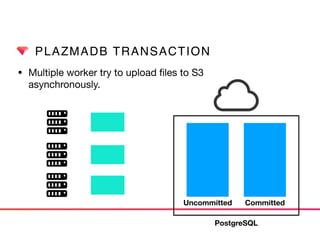
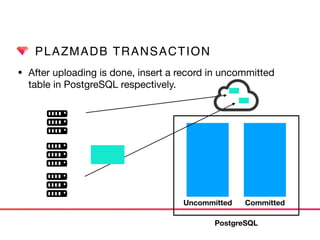
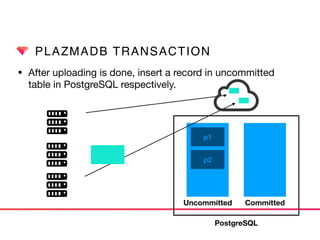
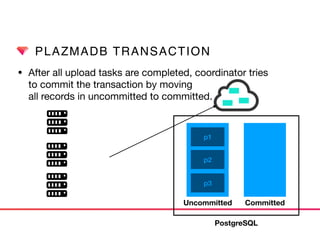
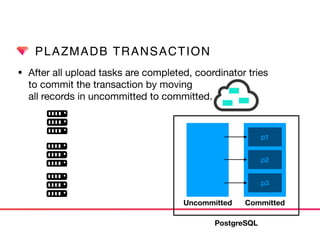
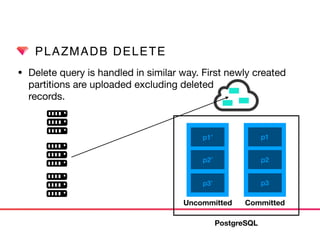
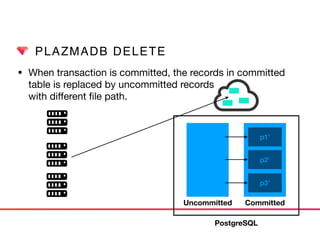

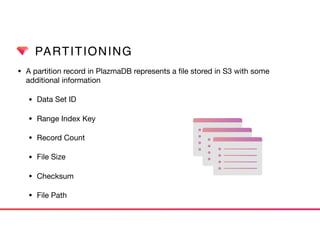

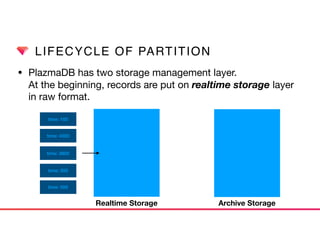
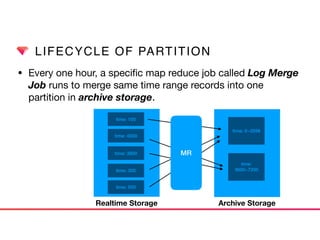
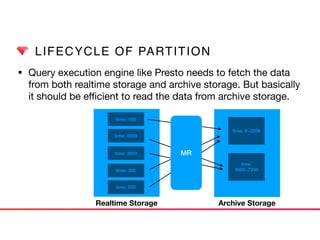


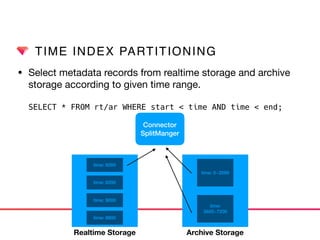
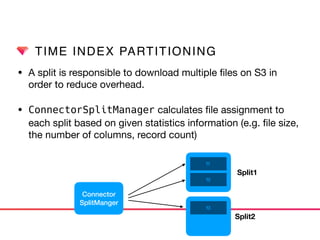
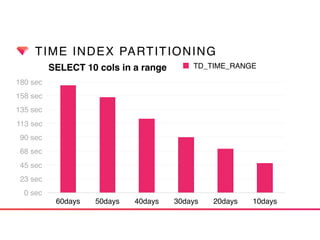
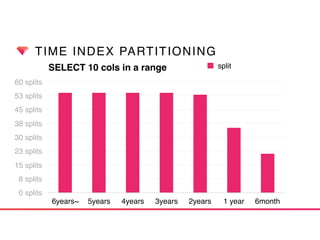



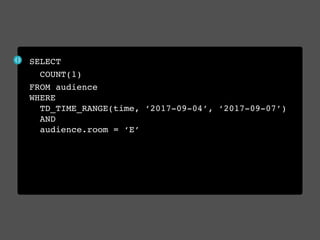
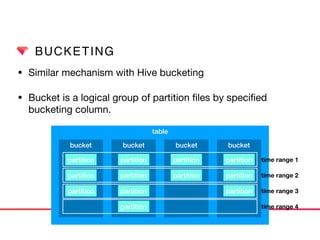
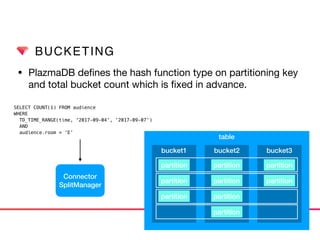
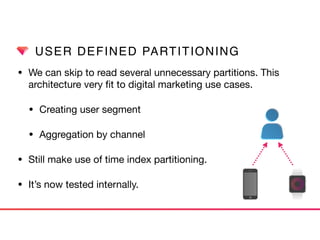



This document discusses Presto connectors and how Treasure Data optimizes the Presto connector for cloud storage. It provides details on: 1) How Treasure Data uses Presto as a distributed SQL query engine and developed its own Presto connector to interface with its cloud-based data storage system called PlazmaDB. 2) Key aspects of PlazmaDB including using PostgreSQL for metadata and S3 for storage, with transactions managed across these systems. 3) How data is partitioned in PlazmaDB to optimize query performance, including time index partitioning based on ingestion time and user-defined partitioning.




![[db tech showcase Tokyo 2017] C34: Replacing Oracle Database at DBS Bank ~Ora...](https://cdn.slidesharecdn.com/ss_thumbnails/replacingoracledatabaseatdbsbankdbtechshowcasetokyosept2017-170911075631-thumbnail.jpg?width=640&height=640&fit=bounds)





























































































