Downloaded 45 times













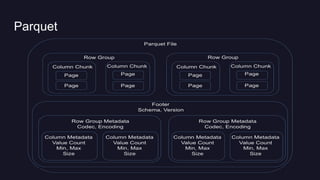
![Parquet Improvement
Predicate Pushdown
Stats [ min: 5, max: 8 ]
Skip this Row Group
Dictionary Pushdown
Stats [ min 5, max: 20]
Dictionary Page [ 5, 9, 12,
17, 20]
Skip this Row Group
Query: Select A, B from T where C = 10;](https://image.slidesharecdn.com/prestohadoopworld-160823054007/85/Presto-Uber-18-320.jpg)




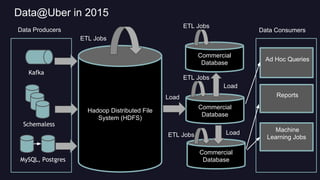
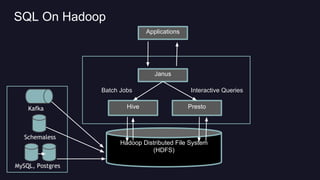
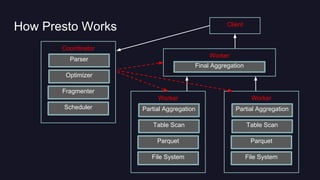
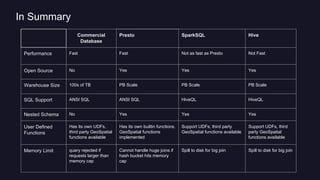
Presto is Uber's distributed SQL query engine for their Hadoop data warehouse. Some key points: - Presto allows interactive SQL queries directly on Uber's petabyte-scale Hadoop data lake without needing to first load the data into another database. - It provides fast performance at scale by leveraging columnar data formats like Parquet and optimizing for distributed execution across many nodes. - Uber deployed a 200 node Presto cluster that handles 30,000 queries per day, serving both ad hoc queries and real-time applications accessing data in Hadoop and improving on the performance of alternative solutions like Hive.



































































