Downloaded 21 times












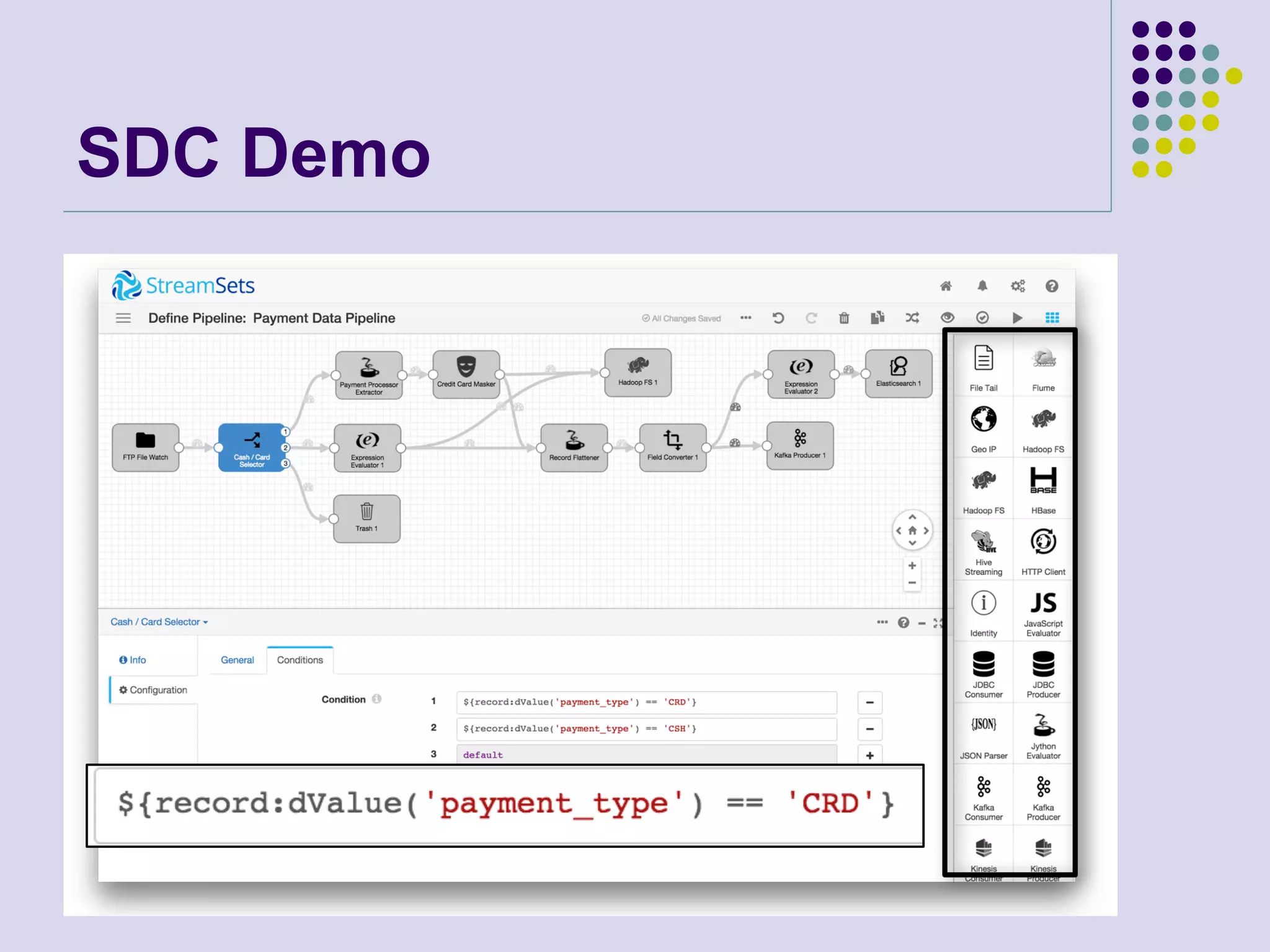



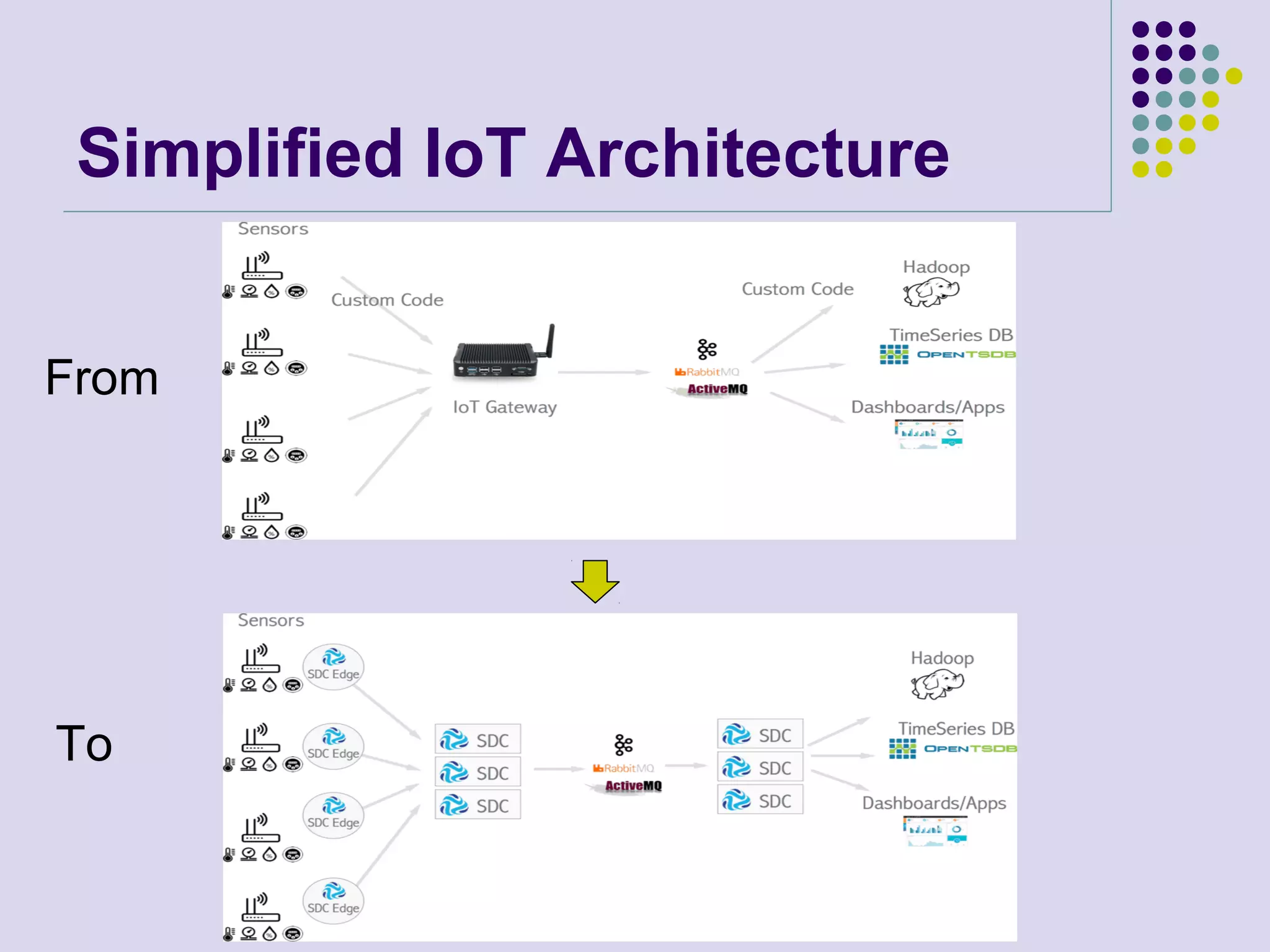





The document discusses ultralight data movement for IoT utilizing StreamSets Data Collector (SDC) and SDC Edge, highlighting challenges in data ingestion from edge devices and proposing solutions for efficient data flow management. SDC is presented as a tool for designing data pipelines with real-time monitoring and minimal coding, while SDC Edge serves as a lightweight agent for data processing at the edge. Use cases for both technologies include IoT applications and cybersecurity analytics.



































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)


















